
东北大学《实体对齐》最新综述论文

摘要
实体对齐(Entity Alignment)旨在发现不同知识图谱(Knowledge Graph)中指代相同事物的实体,是知识图谱融合的关 键技术,近年来受到了广泛的关注。早期,研究者们使用字符串的各种特征来进行实体对齐工作。近年来,随着知识表示学 习(Knowledge Representation Learning)技术的不断发展,研究者们提出了许多基于知识表示学习的实体对齐方法,效果明显 优于传统方法。然而,实体对齐的研究仍然存在着许多亟待解决的问题与挑战,比如数据质量、计算效率等。本文从实体对齐的定义、数据集和评价指标出发,详细深入地综述和比较了传统实体对齐方法和基于知识表示学习的实体对齐方法。针对传统方法,分类介绍了基于相似性计算和基于关系推理的实体对齐方法,并深入研究了每类方法对字符特 征、属性特征、关系特征的利用,同时深入分析了不同方法之间的优势与不足。针对基于知识表示学习的实体对齐方法,本文进行了重点讨论、分析和对比。 首先,本文将该类实体对齐方法抽象为由三个模块(即嵌入模块、交互模块和对齐模块)组 成的统一框架,依据三个模块对每个方法进行了详细的综述。进一步地,根据方法所利用的信息种类的不同,将已有方法划 分为基于结构信息、属性信息、实体名信息、实体描述信息和综合信息等八类方法,对每一类方法进行了详细的综述。然后, 对基于知识表示学习的实体对齐方法进行了深入对比分析。最后,讨论了实体对齐工作的主要挑战,包括稀疏知识图谱的处 理、标注数据的缺乏和噪声问题、方法的效率问题等,并对该工作的未来进行了展望。
https://cjc.ict.ac.cn/online/bfpub/zf-202237100856.pdf
1 引言
近几年,互联网的快速发展促使各领域建立了 越 来 越 多 包 含 互 补 信 息 的 大 规 模 知 识 图 谱 (Knowledge Graph)。同时,随着链接数据(Linked Data)1计划的发展,网络上语义数据的数量不断增 加,而各应用领域面临的主要挑战之一就是集成越 来越多独立设计且存在于不同知识图谱中的实体, 使得大规模的知识图谱之间可以高效协调。因此, 如何发现不同知识图谱实例之间的链接成为各个 领域亟待解决的重要问题[1]。
尤其是,随着近几年知识图谱的快速发展,涌 现出大量的知识图谱[2]。然而,目前很多的知识图 谱由不同机构和个人构建,这些知识图谱的需求特 定,设计和构建并不统一,因此互相之间存在异构 和冗余问题。知识融合旨在将知识图谱中的异构和 冗余等信息进行对齐和合并,形成全局统一的知识 标识和关联[1]。实体对齐(Entity Alignment,EA) [3], [4] 是知识图谱融合过程的关键技术,主要目的是发现 不同知识图谱之间的等价实体。由于不同知识图谱 的知识内容存在来源各异和人为理解不同,指代同 一个事物的文字表达会各有不同。这是不同知识图 谱融合集成的显著问题,影响共享数据的实现。因 此,针对基于知识图谱的知识融合研究,对后续大 数据集成统一的技术探索和发展意义重大[5]。
实体对齐一般可以分为本体对齐和实例对齐, 本体对齐重点关注类、属性和关系,而实例对齐则 更加注重真实世界中指代的具体事物[2]。早期的相 关工作主要集中在本体对齐方面,近几年随着机器 学习和深度学习的发展,也逐渐向实例对齐方向发 展。本体对齐相对于实例对齐而言更加笼统概括,主要针对包含相似实例的一类实体;而实例对齐对 信息的精细程度要求更多,也更加复杂。此外,实 体对齐任务与传统的实体消歧(链接)任务存在差 异,传统的实体消歧需要将文本内容中提及的实 体,链接到知识图谱或知识图谱中的实体。然而实 体对齐,是将两个或者多个结构化的知识图谱或知 识图谱中的实体进行等价对齐[6]。
随着实体对齐技术的发展,许多学者提出了不同种类的实体对齐方法,涌现出大量的实体对齐研 究文献。早期,研究者们使用字符串的各种特征来 进行实体对齐工作。近些年,随着知识表示学习 (Knowledge Representation Learning)技术的快速发 展,研究者们提出了许多基于知识表示学习的实体 对齐方法,这些方法取得了比传统方法更好的效果。然而,截止目前仍然缺少有关实体对齐技术全 面而深入的方法综述。已有的综述文献[7]主要概括 了传统实体对齐方法;文献[8]仅针对基于图神经网 络(Graph Neural Network,GNN)的实体对齐方法进 行了简略介绍;文献[5]和[9]从实验的角度,对部分 实体对齐方法在数据集上的性能进行了深入比较 分析。与上述已有综述不同,本文从方法和技术层 面,更加全面深入地综述和比较了传统实体对齐方 法和基于知识表示学习的实体对齐方法,对这些已 有方法进行了详细的划分与综述。针对传统方法, 本文深入分析研究了每类方法对字符特征、属性特 征、关系特征的利用,进而对比了不同方法之间的 优势与不足。针对主流的基于知识表示学习的实体 对齐方法,本文深入挖掘并研究了每种方法所利用 的知识图谱信息,根据所利用信息种类的不同将已 有方法细分为八个类别,同时进行了详细的综述和 对比分析。
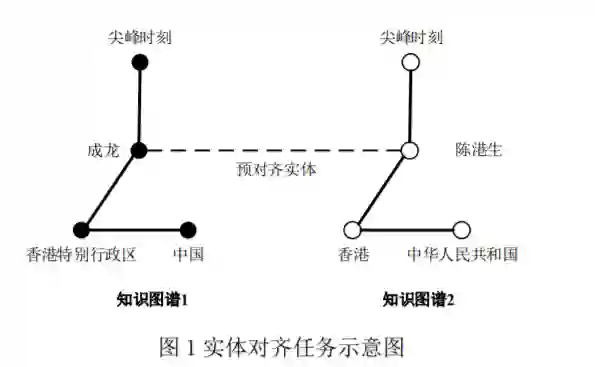
基于以上分析,本文将实体对齐方法分为两大 类,一类是传统的实体对齐方法,一类是基于知识表示学习的实体对齐方法。在给出实体对齐的问题 定义、数据集和评价指标的基础上,进一步详细深 入地综述和比较了这两大类方法。主要贡献如下:
-
针对传统方法,分类介绍了基于相似性计算和 基于关系推理的实体对齐方法,并深入研究了 每类方法对字符特征、属性特征、关系特征的 利用,同时深入分析了不同方法之间的优势与 不足。
-
针对基于知识表示学习的实体对齐方法,本文进行了重点讨论、分析和对比:(i)本文将该 类实体对齐方法抽象为由三个模块(即嵌入模 块、交互模块和对齐模块)组成的统一框架,依 据三个模块对每个方法进行了详细的综述;(ii)根据方法所利用的知识图谱信息种类的 不同,将已有方法细分为基于结构信息、属性 信息、实体名信息、实体描述信息和综合信息 等八类方法,并对每类方法进行了详细介绍和 分析;(iii)进一步对基于知识表示学习的实体 对齐方法进行了深入对比分析。分析结果表 明,科学有效的迭代方法和对多种信息的利用 都能够提升方法的性能等。
-
讨论了实体对齐工作的主要挑战和未来方向, 包括稀疏知识图谱的处理、标注数据的缺乏和 噪声问题、方法的效率问题等。
本文后续章节安排如下:第 2 节给出实体对齐 的问题定义、数据集和评价指标;第 3 节介绍传统 实体对齐方法;第 4 节综述基于知识表示学习的实 体对齐方法;第 5 节概括实体对齐工作的主要挑战 和未来方向;最后给出本文总结。
2 数据
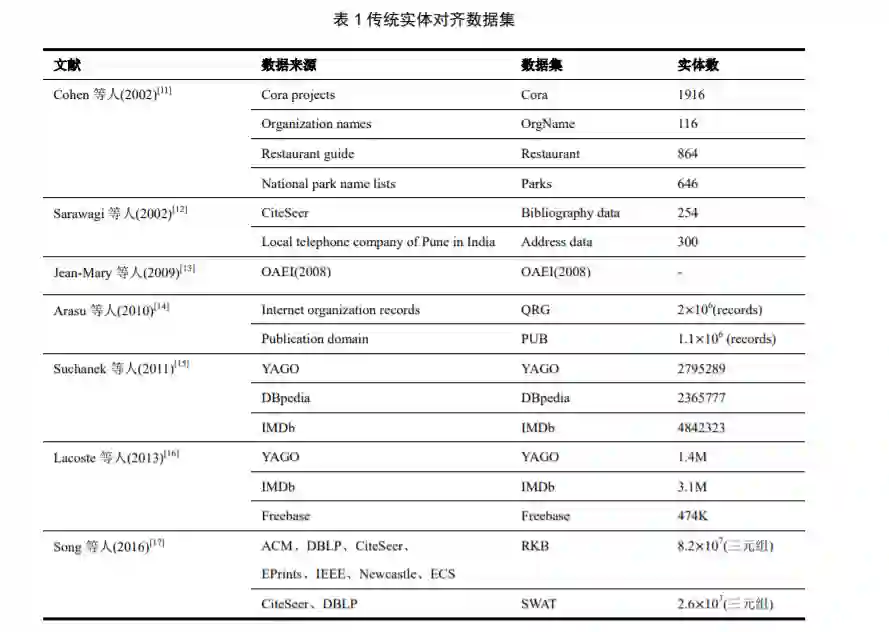
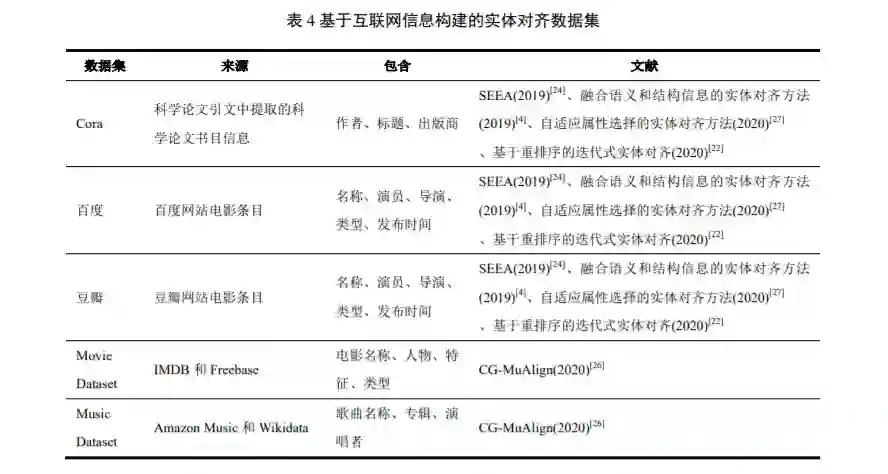
3 传统实体对齐方法
传统的实体对齐方法大多数都集中在句法和 结构上,尤其是早期的实体对齐和映射技术主要侧 重于计算实体之间标签和字符的距离。传统的实体 对齐方法主要从两个角度解决实体对齐问题:一类 是基于相似度计算来比较实体的符号特征[11],另一 类是基于关系推理[32],最近的研究还使用统计机器 学习来提高准确性。本节将详细综述已有的传统实 体对齐方法,同时深入研究每类方法对字符特征、 属性特征、关系特征的利用,并进行对比分析。

4 基于知识表示学习的实体对齐方法
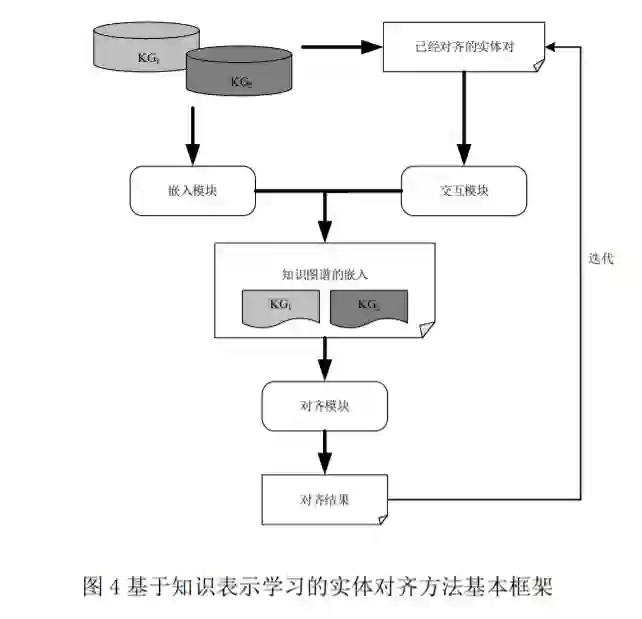
表 示 学 习 又 叫 做 表 征 学 习 (Representation Learning),其目的是利用机器学习技术将描述对象 表示为低维稠密的向量,两个向量之间的距离反映 的是两个对象之间的语义关系。将表示学习应用于 知 识 表 示 中 , 即 知 识 表 示 学 习 (Knowledge Representation Learning),目的是实现知识图谱中实 体和实体之间关系的向量表示,通过降低高维实体 和关系,得到低维向量的数值表示。基于知识表示学习技术能够将实体和关系表 示为低维向量空间的能力,许多研究者们提出了基 于知识表示学习的实体对齐方法,该类方法也成为 目前解决实体对齐问题的主要技术。通过深入研究 这些方法,本文概括并抽象出一个统一的实体对齐 框架,如图 4 所示。其基本思想就是首先通过知识 表示学习技术对知识图谱进行嵌入,即嵌入模块;之后根据已对齐的实体对将不同知识图谱的嵌入空间映射到同一个向量空间中,即交互模块;最后 根据向量空间中实体之间的距离或者相似度得到 实体对齐结果,即对齐模块。此外,大多数方法还 引入了迭代机制,将实体对齐结果添加至已经对齐 的实体对中。本节接下来将对基于知识表示学习的实体对 齐方法进行重点介绍、对比分析和总结。首先,依 据图 4 提到的三个模块(即嵌入模块、交互模块和对 齐模块)对每一种方法进行了详细介绍。同时,本文 通过深入研究,对所有方法根据其利用的知识图谱 信息的不同进行了详细的分类(见 4.2 节)。然后进一 步对该类方法进行了详细的对比,并对结果进行了 深入的分析(见 4.3 节)。下面 4.1 节首先简单介绍现有的知识表示学习 技术,然后后续几节重点综述基于知识表示学习的 实体对齐方法,并进行深入的对比分析。
4.1 知识表示学习技术 目前主要的知识表示学习技术可以分为三类:翻译模型、语义匹配模型、深度模型[38], [39]。
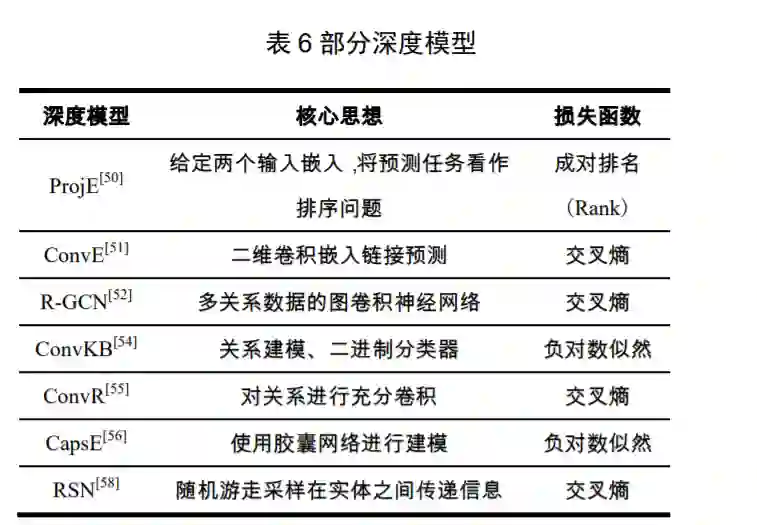
**4.2 基于知识表示学习的实体对齐方法 **
基于知识表示学习的实体对齐方法已经成为 目前解决实体对齐问题的主要技术,并取得了较好 的效果,其中绝大多数方法都使用翻译模型或图神 经网络(Graph Neural Network, GNN) [59]进行知识表 示学习,因为它们有着较强的鲁棒性和泛化能力。

5 展望
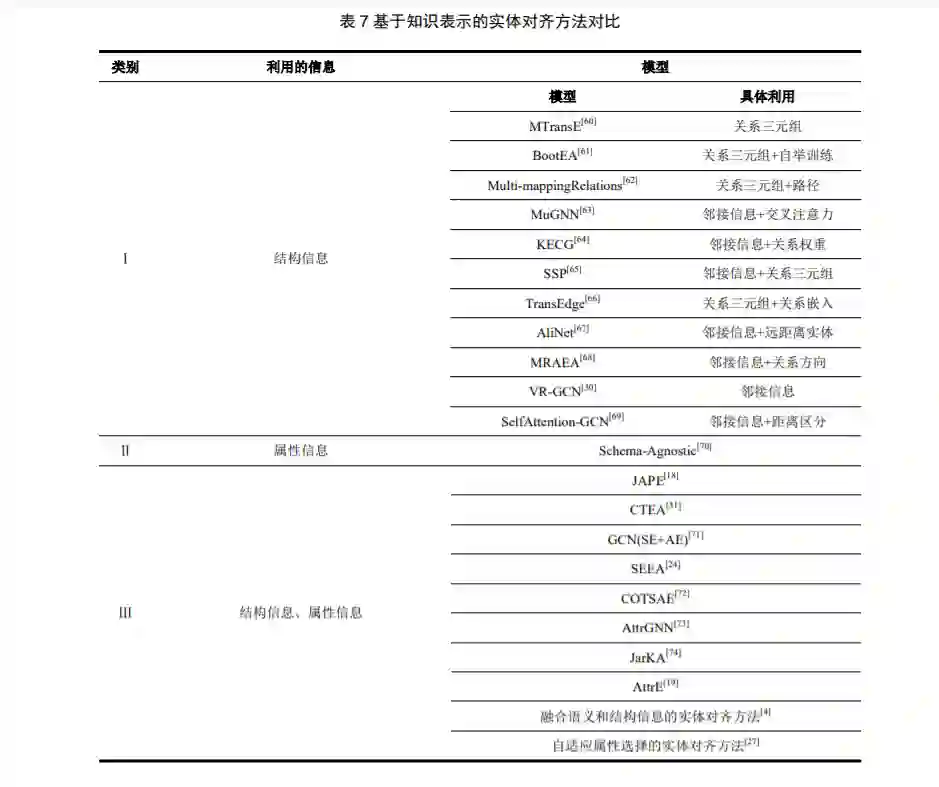
从上述已有方法可以看出,目前基于知识表示 学习的实体对齐方法主要包括三个模块,分别是嵌 入模块、交互模块和对齐模块。嵌入模块目前主要 有三种方法,一种是利用 TransE 及其改进系列进行 关系结构信息嵌入;一种是使用 GNN 构建邻接关 系图进行嵌入;一种是使用 GNN 的改进模型 GCN 进行结构信息嵌入。嵌入模块利用的信息主要有两 种,即结构信息和属性信息。交互模块的作用主要 是将两个不同的知识图谱映射到同一向量空间,使 得向量的计算在同一空间。目前联系两个知识图谱 的桥梁主要是预对齐的实体对,通过预对齐的实体 对在不同向量空间的转换和校准,统一两个知识图 谱。对齐模块的作用主要是根据已经嵌入的实体向 量来计算距离,此外,还能通过一些推理策略选择 待对齐的实体。 值得注意的是,虽然基于知识表示学习的实体 对齐方法取得了较为不错的效果,但是这并不意味 着传统的实体对齐方法不具有研究价值。 正如文献 [5]也指出这两类方法是相辅相成的,结合起来考虑 会有可能取得更好的效果。 随着知识图谱的不断完善,许多知识图谱都变 得越来越复杂,规模也越来越大,原有的实体对齐 算法需要进一步考虑执行效率和准确率。 为了解决 这个问题,并行处理技术受到了越来越多地关注。目前研究工作将并行处理技术应用到实体对齐任 务中的是极少数[7],有关大规模知识图谱的实体对 齐问题仍然需要进行深入的研究和探索。
通过 4.3 节的对比分析,可以看到针对知识图 谱结构信息的利用还有待于继续研究探索,无论是 邻接实体还是实体间的关系,均对知识图谱的更准 确表示起着至关重要的作用。使用神经网络嵌入知 识图谱的结构信息时,如何缓解错误信息的传播至 关重要。目前普遍使用高速门机制,使得错误传播 的问题得到了一定程度的缓解,但是对于单跳和多 跳实体的计算和信息传播仍需继续研究。此外,在知识图谱结构信息嵌入表示方面,大 多数实体对齐模型是以实体为中心,多方面信息辅 助嵌入,在以后的研究中可以提高关系信息的占 比,甚至可以以实体之间关系为中心研究嵌入表 示,进而更深入地挖掘知识图谱的结构信息。除了 结构信息,加入原知识图谱中的实体描述信息使得 实体对齐效果显著提高,如 BERT-INT,甚至可以 忽略结构信息。但是在真实大型知识图谱中,很多实体缺乏具体准确的描述信息,所以对结构信息以 及其他未挖掘的信息有待于进一步深入研究。再 者,在实体对齐任务中,大多数模型方法在通用数 据集 DBP15K 数据集上获得了不错的效果。然而在 实际大型真实知识图谱的表现一般,因此如何进一 步提出不同种类的数据集也成为实体对齐领域的 重要研究问题。

