近期必读的七篇AAAI 2021【问答(QA)】相关论文和代码
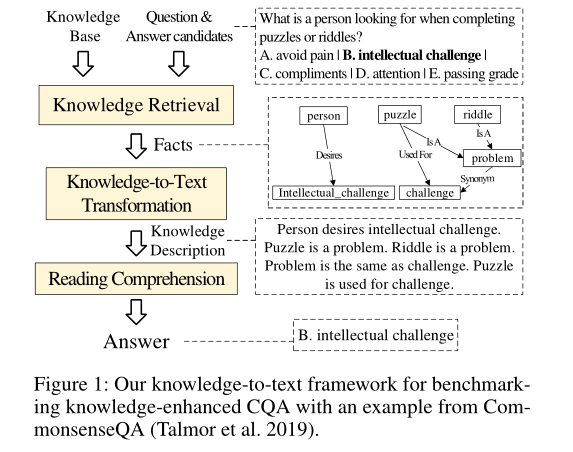
1. Benchmarking Knowledge-Enhanced Commonsense Question Answering via Knowledge-to-Text Transformation
作者:Ning Bian, Xianpei Han, Bo Chen, Le Sun
摘要:人类的一项基本能力是在语言理解和问题解答中利用常识知识。近年来,已经提出了许多知识增强的常识问答(CQA)方法。但是,目前尚不清楚:(1)利用CQA的外部知识能走多远?(2)当前的CQA模型已开发了多少知识潜能?(3)未来CQA最有希望的方向是什么?为了回答这些问题,我们通过使用简单有效的知识到文本转换框架对多个标准CQA数据集进行广泛的实验来对知识增强的CQA进行基准测试。实验表明:(1)我们的知识文本框架是有效的,并且在CQA数据集上达到了最先进的性能,为CQA提供了简单而强大的知识增强基线;(2)知识的潜力仍远未在CQA中得到充分利用-从当前模型到具有黄金知识的模型之间存在巨大的性能差距;(3)上下文相关知识选择,异构知识开发和常识性语言模型是后续CQA的方向。
网址:
https://www.zhuanzhi.ai/paper/7f135777acbf62becbe89ac7ead8d000
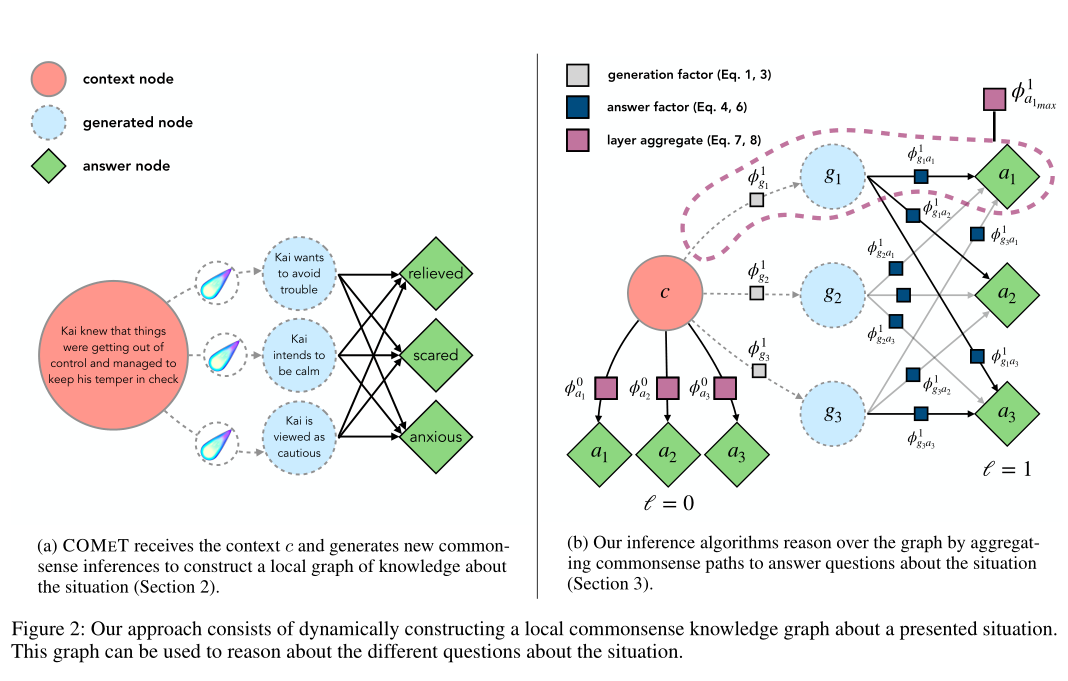
2. Dynamic Neuro-Symbolic Knowledge Graph Construction for Zero-shot Commonsense Question Answering
作者:Antoine Bosselut, Ronan Le Bras, Yejin Choi
摘要:理解故事叙述(Understanding narratives)需要推理有关隐含的世界知识的知识,这些知识与文本中描述情况的原因,结果和状态有关。这个挑战的核心是如何按需访问上下文相关的知识并对其进行推理。在本文中,我们通过将任务转换为对动态生成的常识知识图的推理,并提出了对零样本常识问答的初步研究。与以往依赖于从静态知识图中检索现有知识的知识集成研究相反,我们的研究需要常识性知识集成,而在现有知识库中通常不存在与上下文相关的知识。因此,我们提出了一种新颖的方法,该方法使用生成的神经常识知识模型按需生成上下文相关的符号知识结构。在两个数据集上的实验结果证明了我们的神经符号方法对于动态构建知识图进行推理有着不错的效果。另外,我们的方法在预训练的语言模型和原始知识模型上均取得了显着的性能提升,同时为预测提供了可解释的推理路径。
网址:
https://www.zhuanzhi.ai/paper/33dd7d7d6921f8f5f9168479c51a2464
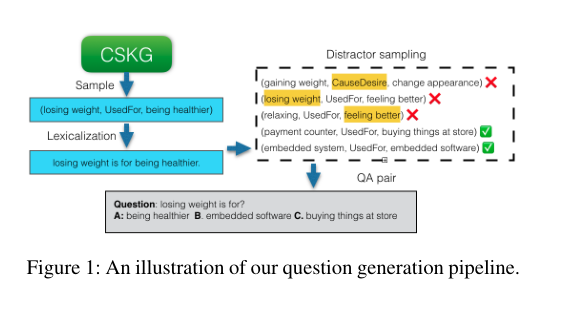
3. Knowledge-driven Data Construction for Zero-shot Evaluation in Commonsense Question Answering
作者:Kaixin Ma, Filip Ilievski, Jonathan Francis, Yonatan Bisk, Eric Nyberg, Alessandro Oltramari
摘要:预训练神经语言建模的最新发展已使得常识问答基准模型的准确性有了很大的提升。但是,人们越来越担心在不学习利用外部知识或执行一般语义推理的情况下,模型仅仅适合特定任务。相比之下,零样本评估可以更可靠地衡量模型的一般推理能力。在本文中,我们针对常识性任务的零样本问题提出了一种新颖的神经符号框架。在一组假设的指导下,该框架研究如何将各种现有的知识资源转换成对预训练模型最有效的形式,另外,我们会改变语言模型,训练制度,知识来源和数据生成策略的集合,并衡量它们在各项任务中的影响。在先前工作的基础上,我们设计并比较了四种受约束的干扰采样策略,使用来自五个外部知识资源的数据提供了五个常识性问答任务的实验结果。实验表明,虽然单个知识图更适合于特定任务,但全局知识图可为不同任务带来一致的帮助。此外,我们发现保留任务的结构以及生成公平而翔实的问题都有助于语言模型更有效地学习。
网址:
https://www.zhuanzhi.ai/paper/80ab4cd4f2e2a7c91e75ca553f6bdb68
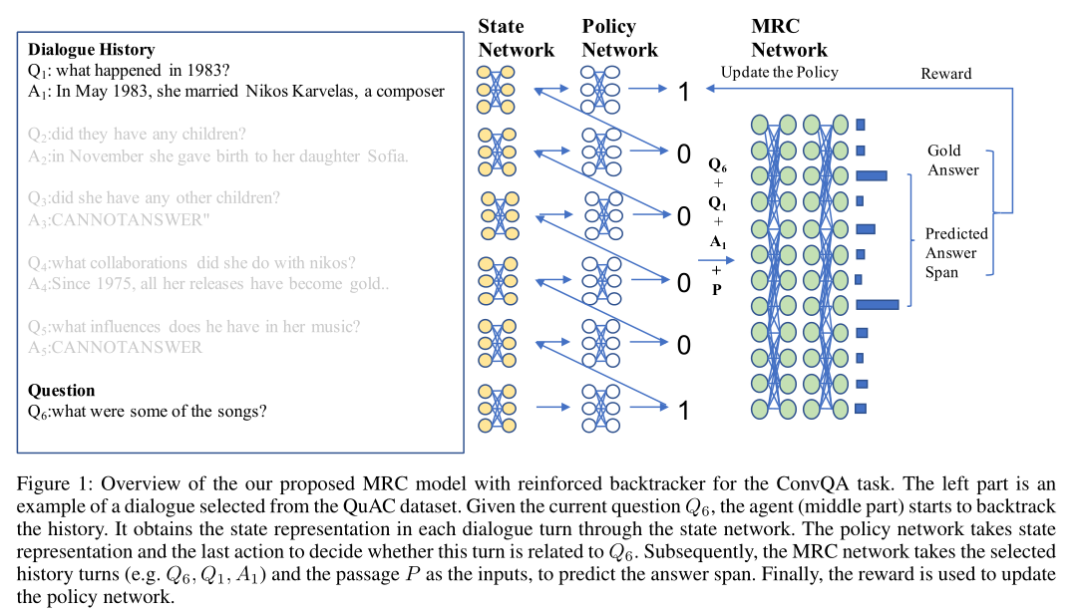
4. Reinforced History Backtracking for Conversational Question Answering
作者:Minghui Qiu, Xinjing Huang, Cen Chen, Feng Ji, Chen Qu, Wei Wei, Jun Huang, Yin Zhang
摘要:在多轮对话中建模上下文历史记录已成为迈向更好理解问答系统中用户查询的关键步骤。为了利用上下文历史信息,大多数现有研究将整个上下文视为输入,这将不可避免地面临以下两个挑战。首先,对悠久的历史进行建模可能会很昂贵,因为它需要更多的计算资源。其次,较长的上下文历史记录包含许多不相关的信息,这使得很难对与用户查询有关的适当信息进行建模。为了缓解这些问题,本文提出了一种基于强化学习的方法来捕获和回溯相关的对话历史,以提高模型性能。我们的方法试图利用模型性能的隐式反馈自动回溯历史信息,进一步考虑立即和延迟的奖励,以指导强化的回溯政策。在大型对话式问答数据集上进行的大量实验表明,所提出的方法可以缓解由较长的上下文历史引起的问题。同时,实验表明该方法比其他模型具有更好的性能。
网址:
https://www.aaai.org/AAAI21Papers/AAAI-1260.QiuM.pdf
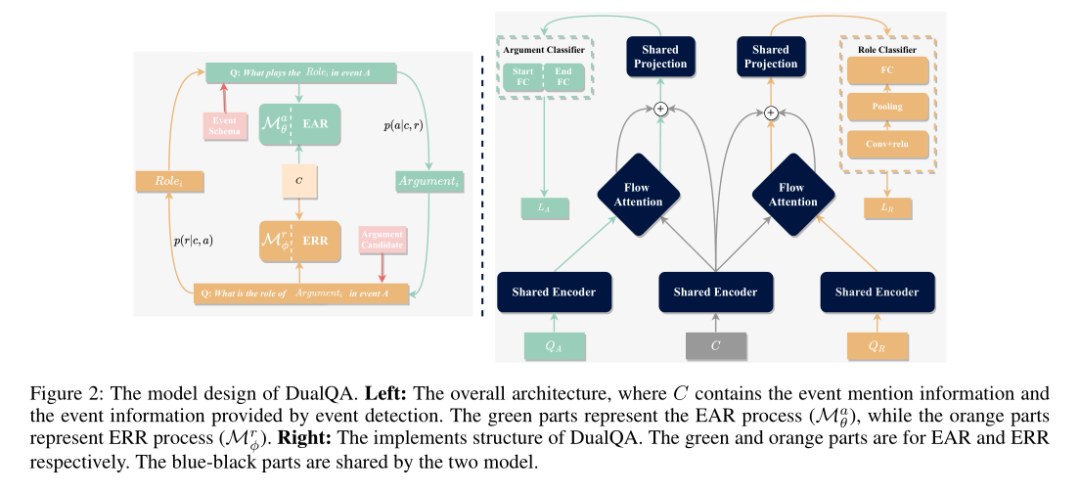
5. What the role is vs. What plays the role: Semi-supervised Event Argument Extraction via Dual Question Answering
作者:Yang Zhou, Yubo Chen, Jun Zhao, Yin Wu, Jiexin Xu, Jinlong Li
摘要:事件论点提取(Event argument extraction)是事件提取中的一项基本任务,在资源匮乏的情况下尤其具有挑战性。我们从两个方面解决了资源匮乏情况下现有研究中的问题。从模型的角度来看,现有的方法总是担心参数共享不足,并且没有考虑角色的语义,这不利于处理稀疏数据。从数据的角度来看,大多数现有方法都专注于数据生成和数据增强。但是,这些方法严重依赖于外部资源,这比创建未标记的数据更费力。在本文中,我们提出了一种新颖的框架DualQA,该框架将事件论点提取任务建模为问题回答,以缓解数据稀疏问题,并利用事件论点识别的双重性(即“起什么作用”)作为事件角色识别,即询问“角色是什么”,以相互促进。在两个数据集上的实验结果证明了我们方法的有效性,特别是在资源极少的情况下。
网址:
https://www.aaai.org/AAAI21Papers/AAAI-2635.ZhouY.pdf
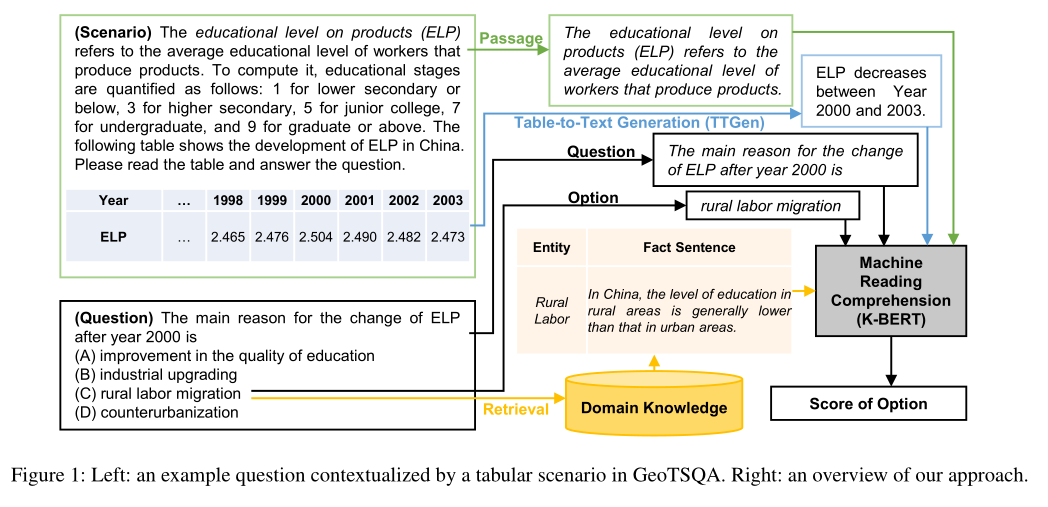
6. TSQA: Tabular Scenario Based Question Answering
作者:Xiao Li, Yawei Sun, Gong Cheng
摘要:基于场景的问题解答(SQA)引起了越来越多的研究兴趣。与经过深入研究的机器阅读理解(MRC)相比,SQA是一项更具挑战性的任务:一个场景不仅可以包含用于阅读的文本段落,还可以包含诸如表的结构化数据,即基于表格的场景问答(TSQA)。TSQA的AI应用程序(例如在高中考试中回答多项选择题)要求综合多个单元格中的数据,并将表格与文本和领域知识相结合以推断出答案。为了支持这项任务的研究,我们构建了GeoTSQA。该数据集包含1k个实际问题,这些问题由地理领域中的表格情境所关联。为了解决该任务,我们使用TTGen(一种新颖的表到文本生成器)扩展了最新的MRC方法。它从各种合成的表格数据生成句子,并向下游MRC方法提供最有用的句子。它的句子排序模型融合了场景,问题和领域知识中的信息。在GeoTSQA上,我们的方法优于各种强大的基线方法。
网址:
https://www.aaai.org/AAAI21Papers/AAAI-4940.LiX.pdf
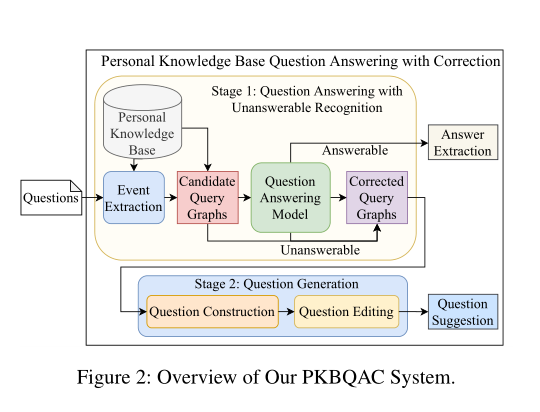
7. Unanswerable Question Correction in Question Answering over Personal Knowledge Base
作者:An-Zi Yen, Hen-Hsen Huang, Hsin-Hsi Chen
摘要:在本文中,我们旨在构建一个问答系统,使人们可以通过个人知识库查询过去的经历。以前有关知识库问答的工作着重于寻找可回答问题的答案。但是,在现实世界的应用程序中,人们经常混淆事实,并提出那些知识库无法回答的问题。这项工作提出了一个由问题回答模型和问题产生模型组成的新颖系统。它不仅可以回答可疑问题,还可以在必要时纠正无法解决的问题。我们的问题回答模型可以识别与个人知识库状态不符的问题,并提出可以构成可行问题的事实。然后,通过问题生成模型将事实转换为可回答的问题。为提炼问题,我们提出了一种基于强化学习(RL)和问题编辑机制的问题生成模型。实验结果表明,我们提出的系统可以有效地纠正个人知识库问答中无法回答的问题。
网址:
https://www.aaai.org/AAAI21Papers/AAAI-6350.YenAZ.pdf
请关注专知公众号(点击上方蓝色专知关注)
后台回复“AAAI2021QA” 就可以获取《7篇顶会AAAI 2021 问答(Question Answering)相关论文》的PDF下载链接~




