3年从0到300万用户,我们怎样在高速发展中扩展云基础设施?

作者 | Kareem Ayesh
译者 | 张卫滨
策划 | 万佳
Meddy 成立于 2016 年,随着其规模的扩展,它取得了很大成功。在 2019 年,我们庆祝达成 100000 个预定和服务于 300 万用户,并获得 A 轮融资。在过去四年中,Meddy 经历很多技术上的变化。本文为成长中的科技初创公司提供基础设施方面的建议。我们将讨论四年前最初的基础设施,这些年来我们面临的所有问题以及为解决这些问题采用的增量式解决方案。
我记得 CEO 告诉我,他的代码比我写的任何代码都好,当我问他为什么,他说“因为我的代码已经被成千上万的人使用了”。
……他是对的。
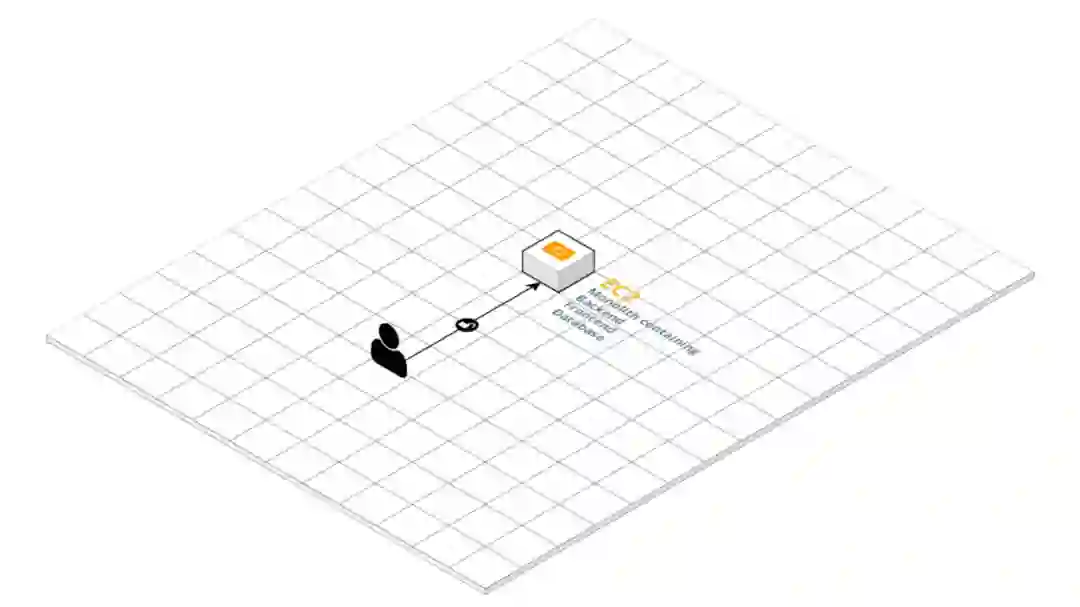
使用单体结构本身并不是什么问题。只是,对于大多数单体应用来讲,随着它不断演化,最终将会作茧自缚,而这恰好是我们经历的。
也就是说,这意味着在项目的生命周期中会出现很多的问题。
但是,我们所担心的并不是技术方面本身的问题,而是最终无法解决它们的宿命。
单体的存在就意味着问题就像进入了死胡同。请求添加的特性越多,出现的问题也就越多,解决这些问题就像创建新特性一样自然。
基础设施最初的重构和更新对应用的增长是至关重要的,这反过来又为可能出现的问题提前提供了潜在的解决方案。这样一来,对新功能的要求就不会引发一连串的推诿扯皮或更糟的“我认为现在这是不可能的”。
在当前的单体架构中,数据持久化是一个令人头疼的大问题。上传的镜像、数据库和日志都必须备份到根文件系统中,当新实例启动的时候会用到它们。当时没有 staging 实例,所以测试都是在生产环境进行的,服务器频繁出现故障,从而危及我们的数据。
另外一个需要解决的大问题就是部署。部署是通过 SSH 和直接从 Github origin 上git pull代码完成的,没有任何形式的脚本来自动化新进程启动、运行测试以及报告错误的过程。
显然,我们需要有一些变化,我们决定除了应用代码的变更外,还需要对基础设施进行一些小的变更,也就是将数据库和上传的文件放到单独的服务中。
通过使用 AWS 的三个服务,解决了如下三个问题:
使用 RDS 管理 Postgres 数据库
使用 S3 存储上传的媒体文件
使用 ElasticBeanstalk 管理部署
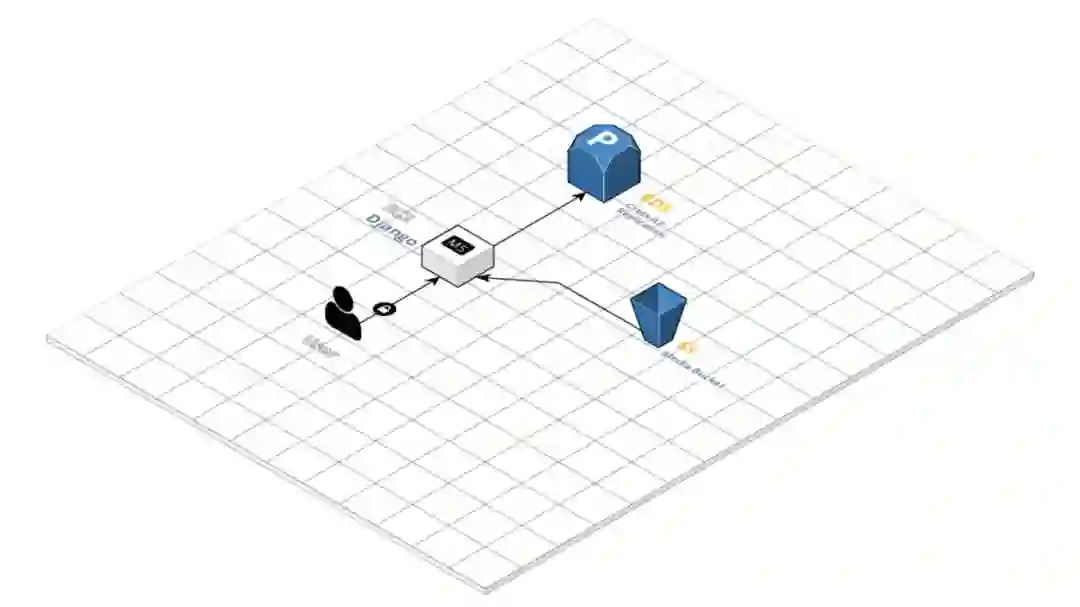
重申一下,我们在这个项目中所做的整体变更并没有对基础设施带来很大的改善。这种分离只是保证应用程序中未来的问题不会损害任何敏感的东西。此外,由于在主 EC2 实例上只有一个应用程序,这意味着任何额外的资源都可以存在于独立的服务器或服务上而没有任何问题。
但这并不完美:
Celery 和 Redis 运行在和应用本身所在的服务器上
前端应用采用了 AngularJS 和 Django 的混合渲染,有时候这会阻塞处理器
日志存储在文件服务器上(并没有其他可用的地方)
当时,业务量比较低,我们并没有太多的服务甚至太多的特性,所以这些问题都是可以容忍的。
不过,这个项目提供了一个很重要的敲门砖,并为以后奠定了坚实的基础。
搜索是一个令人沮丧的功能,它会耗费很长时间,但并不是十分精准。我们以前使用 Postgres 的 Trigram Similarity 来实现搜索功能。针对大量记录进行搜索的话,它并不是最快的方案,而且针对多字段的搜索也并不准确。
https://stackoverflow.com/questions/43156987/postgresql-trigrams-and-similarity
最重要的是,我们无法真正控制这些搜索的行为。我们希望跟踪所有在搜索查询中遇到的问题。

我们用 Google Sheet 记录了所有想要对搜索功能进行的改善
搜索会占用其所在实例的大量资源。与其扩展实例并继续在实例中运行搜索,我们决定采用一个不同的方案,那就是启用一个单独的服务,在 EC2 实例上运行 ElasticSearch。每当有新的记录创建或更新的时候,我们就会更新该 EC2 实例中的一个索引。另外,还有一个 cronjob 定时更新完整的索引。
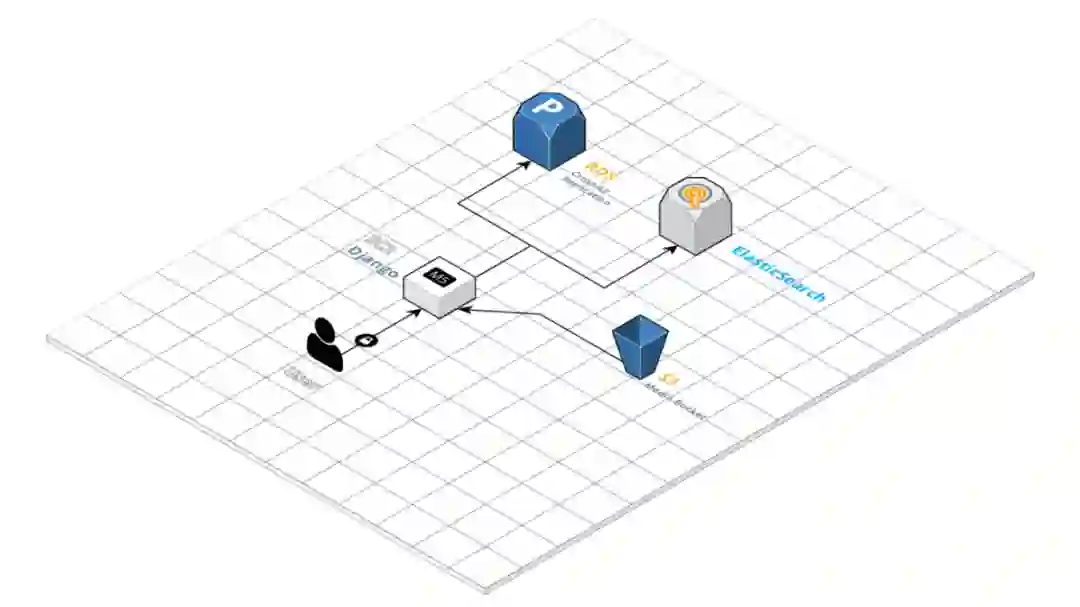
添加 ElasticSearch
经过我们反复迭代,最终形成了更好以及更加可控的搜索功能,这个过程中没有对 ElasticSearch 服务上运行的镜像进行太大的修改。
在每次部署的时候,我们都会经历 10 秒钟的停机时间。部署是由 ElasticBeanstalk 负责的。在底层,EB 会并行运行新的(ondeck)和旧的(current)应用,并且会在所有的执行脚本成功时进行一个符号链接(symlink)。因为我们使用的是一个服务器,所以符号链接会导致 5 到 10 秒的停机时间,这是我们需要解决的。
为了解决这个问题,我们需要在多个服务器上进行滚动部署。这是一个相对比较简单的过程,只需要在我们的 ElasticBeanstalk 管理的自动扩展组(Autoscaling group)前面添加一个 [应用负载均衡器 Application Load Balancer 就可以了。
https://rollout.io/blog/rolling-deployment/
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
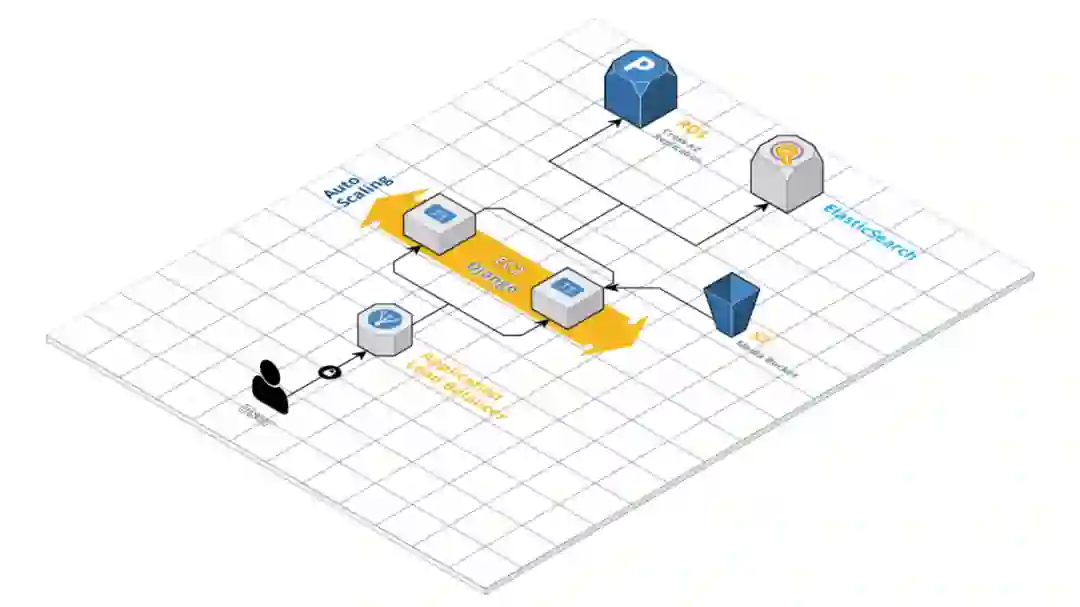
添加负载均衡器
滚动部署增加了测试开销,也带来了更长的部署时间,但是彻底消除了停机的问题。
过去,我们采用了混合渲染的方式,其中 Django 应用会部分渲染 HTML,而在客户端会运行 AngularJS 应用。这导致了很多问题:
我们的渲染非常慢并且会困住开发团队和服务器。我们的服务器需要很多的处理能力才能进行渲染,响应时间出现了难以避免的瓶颈。甚至开发都变得非常困难,因为一个变更我们就需要编码很多次。在某些情况下,改变一个跟踪事件都是很困难的。
https://docs.djangoproject.com/en/3.0/topics/performance/#alternatives-to-django-s-template-language
糟糕的构建系统导致了高负载时间。我们过去使用自己的构建系统,因为对于混合渲染来说,没有 AngularJS 构建管理器,我们自己的系统有很多打包不一致和缓存问题,这导致了低效的构建和高负载时间。这也是一个需要改变和改进的问题。
网站偶尔会卡住 5 到 10 分钟。当我们收到来自用户或机器人的大量请求时,服务器会打开太多与数据库的连接,导致数据库被挂起。A 轮融资为 Meddy 带来更多的业务之后,在 2019 年底,这种情况每周都会发生。原因在于 Django 会打开一个数据库连接,该连接会一直处于打开状态,直到 HTML 渲染结束。因为打开了太多的数据库连接,这会导致服务器卡住,最终生成 504 响应。
在 A 轮融资后,我们开始将代码从混合渲染转向纯客户端渲染。为实现这一点,必须对后端服务请求的方式进行大量更改。
我们决定使用 S3 的桶托管前端资源,并使用 CloudFront 分发响应。CloudFront 还允许我们附加 Lambda 函数,从而能够非常细粒度地对请求进行所需的控制。
我们进行混合渲染的一个重要原因是担心动态渲染会影响 SEO,而我们网站卡住的一个重要原因是机器人导致的请求暴增。通过预先渲染页面以及为机器人提供预先渲染的页面,这两个问题都得到了解决。
https://community.cloudflare.com/t/anyone-else-in-the-recent-days-getting-small-attacks-from-facebook-bots/89019
为了实现这一点,我们使用了一个名为 prerender.io 的服务,它能预渲染请求页面、缓存这些页面并将这些页面提供给机器人。基于 HTTP 请求的 User-agent,我们在所使用的 CloudFront 分发版本的 Lambda Edge 函数中新增了一个机器人探测机制。如果探测到机器人的话,它们就会被重定向到 prerender.io,从而得到一个缓存的页面。
https://prerender.io/
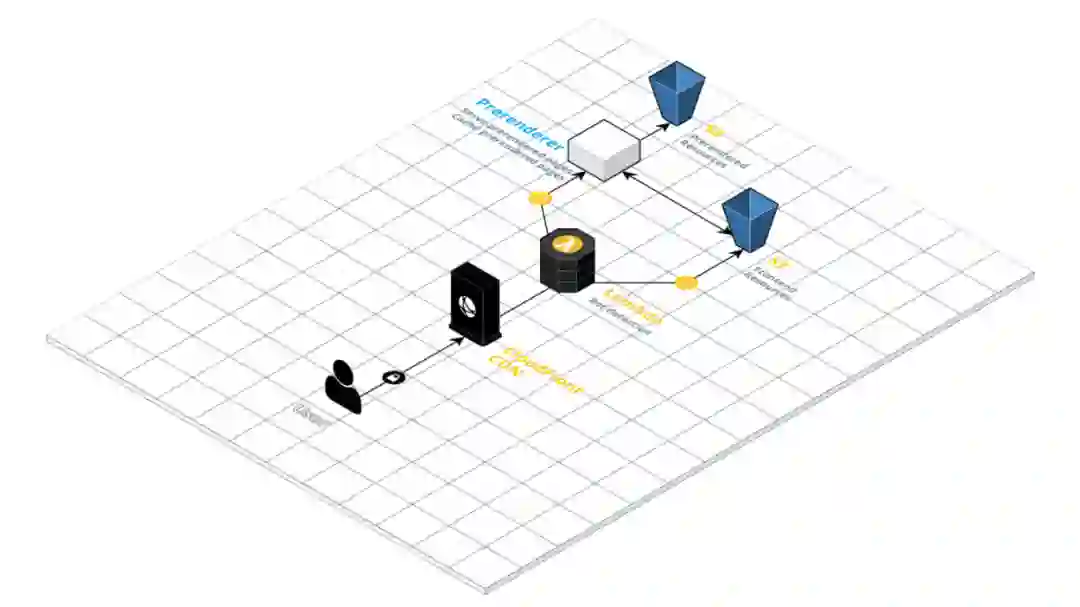
添加预渲染和机器人探测
很重要的一点需要注意,一旦我们达到 300,000 个页面,prerender.io 的成本就会变得非常高,所以必须要有自己的预渲染服务。于是,我们使用 S3 实现了自己的缓存机制,并使用 ECS Fargate 来托管服务。
缓存资源无法在服务器之间共享。缓存资源无法在服务器之间共享,这意味着有些请求是被缓存的,而有些则是没有被缓存的。另外,我们也遇到了服务器上的 Redis 问题。Redis 在服务器上有调度的数据转储,当磁盘空间被其他服务占用的时候,这会导致停机,这样的情况曾经出现过两次。
调度任务需要在一台服务器上运行。Celery Beat 具有内置的功能以便于在特定的日期和时间运行任务,并且会生成事件流,该事件流会以表的形式存储在数据库中。对我们来说,这是非常有用的,因为我们可以使用它在预约前后的特定时间间隔发送提醒短信。假如将它保存在服务器上,将会导致任务重复执行,这主要会在我们的通知模块中引发冲突。
https://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
因为我们要基于负载均衡器使用多台服务器,后端必须要共享类似的缓存服务器。为了实现这一点,我们使用了 ElastiCache。初始环境的搭建非常容易,更具挑战性的方面是我们的任务管理器,它在每台服务器上由 Celery Beat 进行管理。
为了实现解耦,我们会在一个新服务上创建事件,该服务通过向后端发送请求调用这些事件。事件只会存储它需要调用的函数、函数的参数以及它需要调用的时间。这里会有自己的数据库,当请求后端的时候,后端将会填充事件。
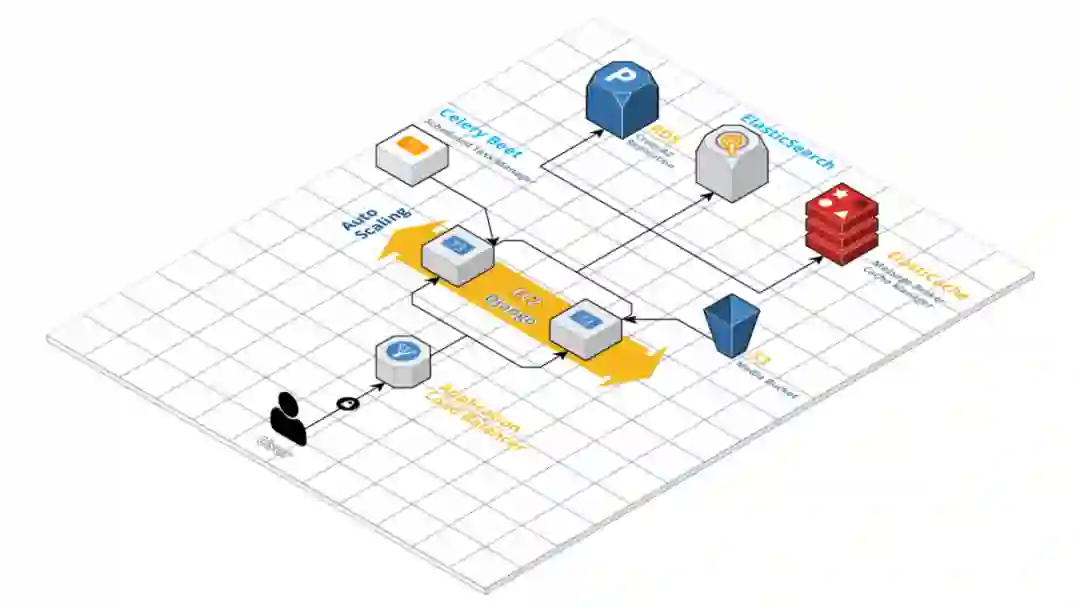
将 Redis 和 Celery 移到单独的服务中
这会带来一个很明显的不足:那就是不能使用 pickle,因为请求是通过 HTTP 调用的。但是,鉴于 Celery 不推荐使用 Pickle,所以我们没有在代码中使用它。
https://docs.celeryproject.org/projects/kombu/en/stable/userguide/serialization.html#serializers
短链接的重定向会在客户端应用中出现。转向纯客户端应用意味着服务器无法在某个连接上提供 301 响应,这是因为所有的请求都转到了 S3 的桶中。当某个重定向要从/x转向/y时,客户端侧的应用必须要向服务器检查/x,并通过向 DOM 中添加一个额外的参数告知 Prerenderer 该页面需要进行重定向。为了确保 Prerenderer 能够注意到这一点,我们创建一个页面,该页面显示“重定向中,请稍候”并添加了这个额外的参数。
对于内部重定向来讲,这还是可行的,因为我们没有太多这样的场景。但是对于短链接来讲,这种方式就不理想了,因为我们想要用户直接看到这些短链接,不需要进行任何的等待,尤其是当我们需要重定向到 Meddy 外部时尤为如此。
为了解决这一点,我们创建了两个 Lambda 函数,这两个函数会从一个包含 hash 和链接的 Dynamo 表中读取数据。其中一个 Lambda 函数用来生成短链接,另外一个函数则负责重定向短链接。
除此之外,针对这些 URL,我们使用 API 网关作为重定向 Lambda 函数的入口,并将其关联到一个新的域中。
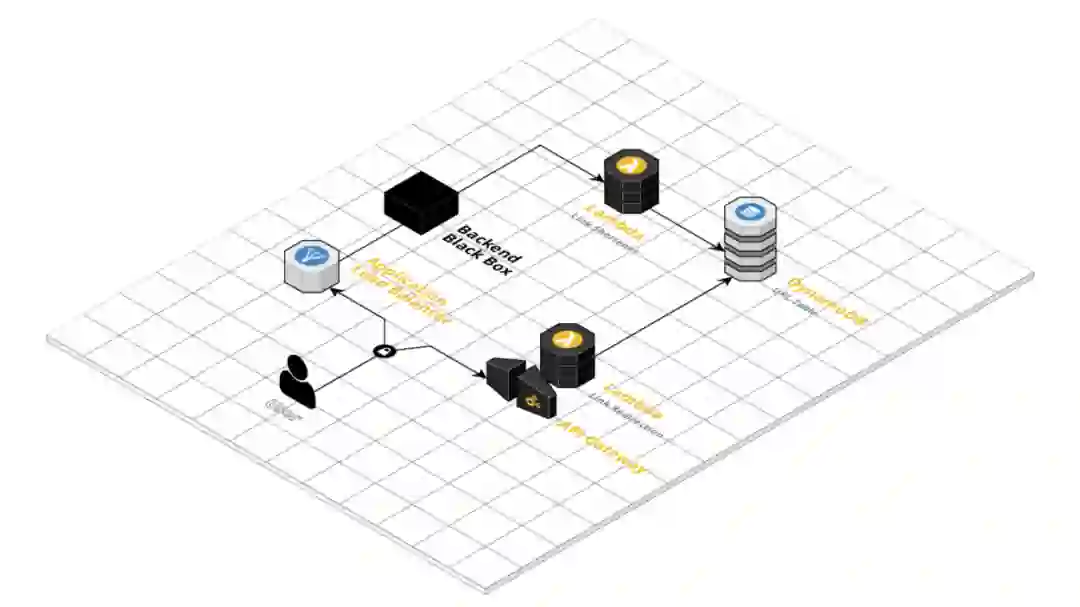
使用 Lambda 添加链接重定向
这种方式能够很好地运行,Lambda 几乎没有提供任何维护和使用图表,我们的数据库中不需要维护一个持有这些重定向的大表。
对更好日志的需求是相当迫切的。服务器请求数量的增加意味着我们不能再依赖于在文件系统中轮流切换日志文件,因为文件会轮转地非常快。除此之外,我们所使用的服务数量也在增长,从不同的文件系统拉取文件是一个噩梦。为所有的服务提供一个中心化的日志系统是一项挑战。
我们决定使用 Grafana Loki 构建一个服务实现日志和监控功能。Loki 是一个开源的、可水平伸缩的、支持多租户的日志管理聚合系统,其灵感来源于 Prometheus。而 Grafana 是一个开源的分析和交互式可视化软件。实际上,我们使用 Loki 作为日志聚合工具,使用 Grafana 可视化这些日志。
https://grafana.com/oss/loki/
这里的理念是让我们的不同服务推送日志到 Loki 服务所打开的一个 HTTP 端点上。Loki 将会对它们进行索引并以二进制格式存储到 S3 和 DynamoDB 表的索引中。这样的话,我们就能够在日志中查找特定的标记,比如特定的状态码和特定的日志级别。通过这种方式,我们也能查询日志,甚至对它们使用聚合功能,比如计算过去 5 分钟内具有特定标记的日志的数量。
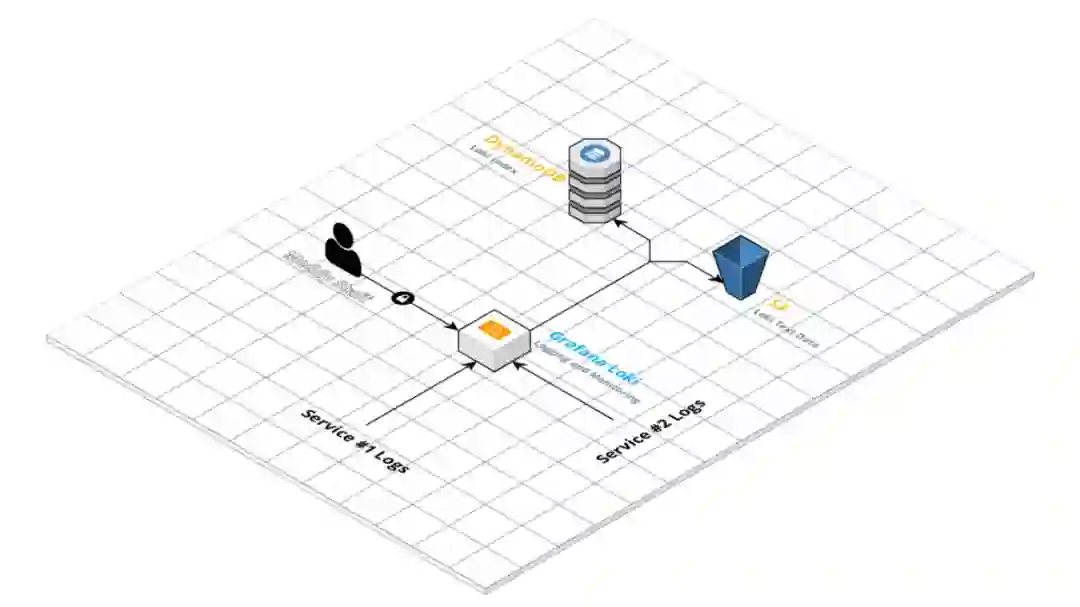
使用 Grafana Loki 添加日志和监控
在事件监控方面,我们依然使用 Grafana,但是,这次它搭配的是 AWS CloudWatch。Grafana 作为 CloudWatch 的客户端,按需获取数据并对其进行可视化。
如上所述,为了将日志推送至 Loki,我们必须为不同的服务采用不同的技术,比如在应用服务器上构建处理程序、为数据转储添加 Lambda 函数。Lambda 函数用来解析来自 S3 的 Load Balancer 和 CloudFront 日志,并将它们推送至 Loki。
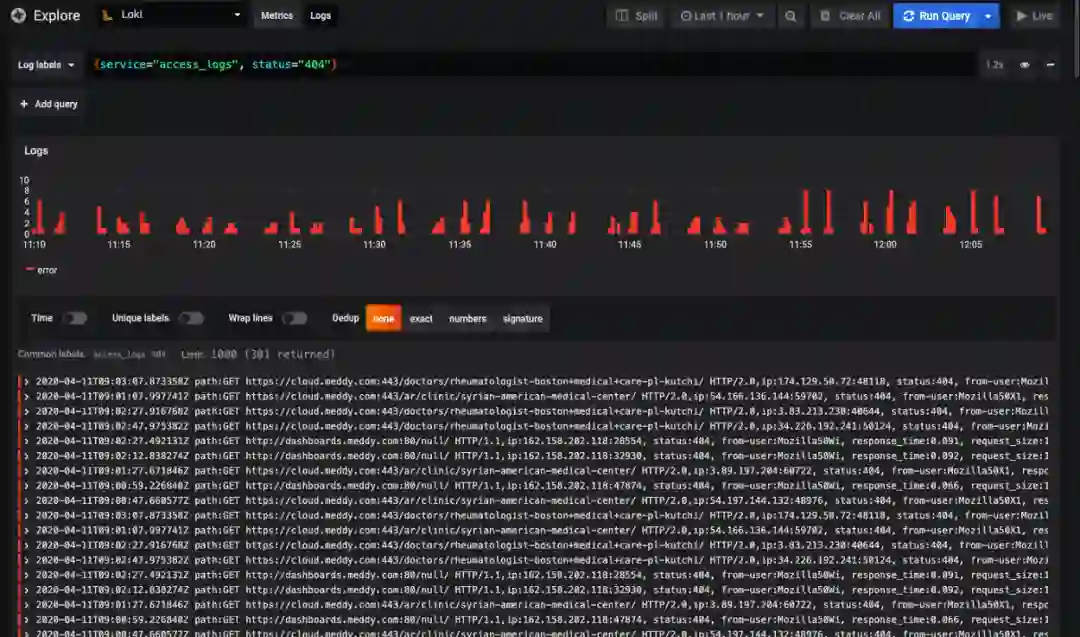
通过混合使用数据处理程序和 CloudWatch,我们就能够为基础设施中的所有内容构建一个中心化的日志和监控系统,我们可以在一个地方监控所有的东西。
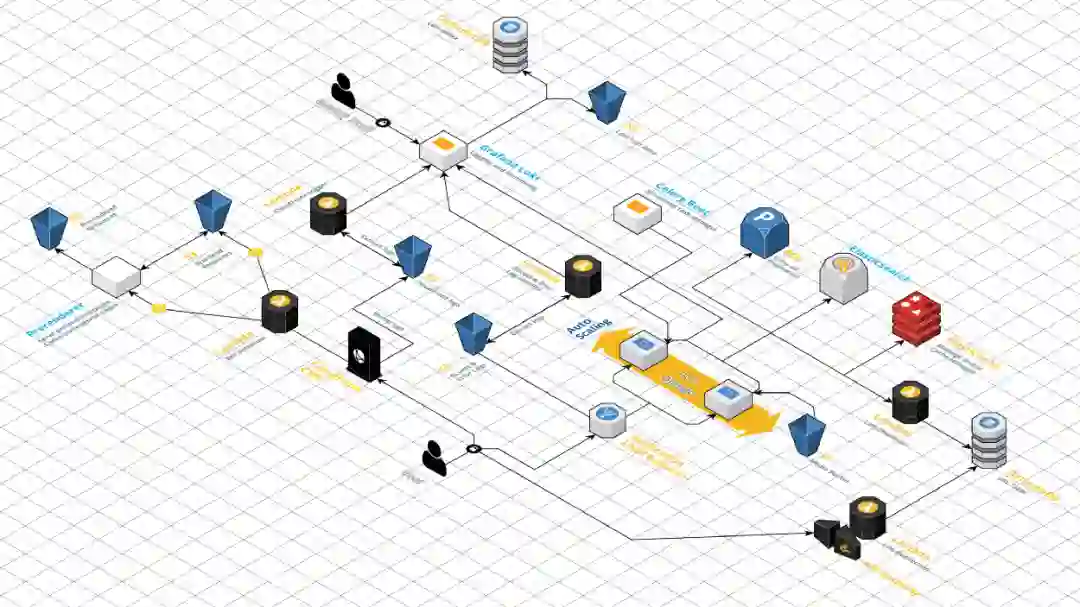
这可能是到目前为止我们最喜欢的文章,因为它这展示了我们在经历这些挑战时所带来的成长。最令人兴奋的是,对 Meddy 来说仅仅是一个开始。
原文链接:
https://medium.com/swlh/scaling-our-aws-infrastructure-9e64e6817b8c






