"炼丹"黑科技!用cutlass进行低成本、高性能卷积算子定制开发
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达


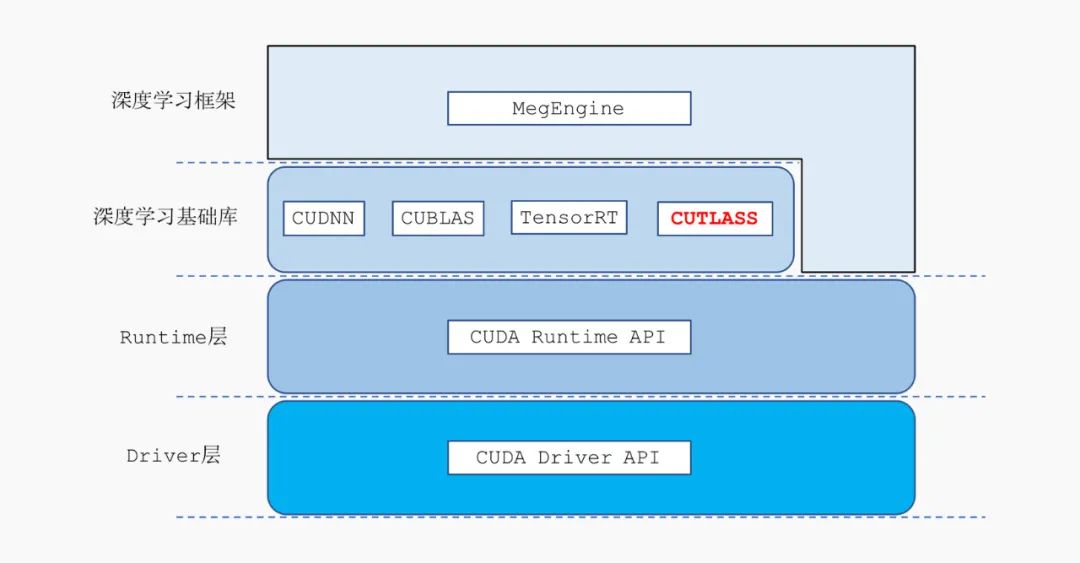
为了充分发挥 CUDA 平台的计算能力,NVIDIA 推出了高度优化的深度学习、线性代数算子库 cudnn、cublas、cutlass,以及 CUDA 平台上的深度学习推理框架 TensorRT。
-
cudnn、cublas 这样的基础算子原语库在常见的卷积层上性能表现很好,通常都能够满足用户的需求,但是在面对用户高度定制化的算法时,基础算子库往往并不能充分发挥硬件的性能。这是由于算子优化的长尾问题引起的,基础算子库引入了许多卷积优化的通用策略,但是这些优化的策略并不能覆盖所有的情况,实际算法中的卷积层有可能并不能从通用的优化策略中获得收益,从而无法充分发挥硬件的性能。
基础算子库的另一个问题是用户无法对这些基础算子进行定制化开发,当算法开发人员想为卷积算子添加一种新的激活函数,或者想添加一种特殊的卷积算子(比如:LocalConv)时,就会变得束手无策。
-
cutlass 是 NVIDIA 推出的一款线性代数模板库,它定义了一系列高度优化的算子组件,开发人员可以通过组合这些组件,开发出性能和 cudnn、cublas 相当的线性代数算子。但是 cutlass 仅支持矩阵乘法运算,不支持卷积算子,从而难以直接应用到计算机视觉领域的推理部署中。
-
TensorRT 是一款非常强大的深度学习推理部署框架,在 CUDA 平台上性能表现非常优秀,而且目前已经比较成熟,用户使用起来比较方便。然而 TensorRT 也存在着一些问题,对于开发人员来说,TensorRT 是一个黑盒,用户没有办法细粒度控制 TensorRT 内部的实现细节。
例如:在部署量化网络时,开发人员无法控制 TensorRT 底层的量化细节,有可能会出现部署和训练的精度对不齐的问题。再比如:TensorRT 在推理部署时,用户无法精细的控制算子的显存使用情况,有时 TensorRT 在运行网络时耗费了大量的显存,而用户却没有特别好的办法对此进行优化。
-
大部分开源训练框架在 CUDA 平台上的部署方案,都是基于模型转换工具,将网络转换成 TensorRT 支持的格式,然后交由 TensorRT 来执行推理任务。然而各大训练框架在算子的定义上会有细微的差别,这使得在模型转换的过程中会引入难以避免的性能、精度上的损失。
-
TVM 作为一款支持全平台的深度学习推理框架,对 CUDA 平台进行了比较好的支持。TVM 基于算子优化的原语定义了一系列矩阵乘法、卷积的模板,通过对模板进行运行时调优,来获得最优的性能。但是 TVM 采用的代码自动生成技术在 CUDA 平台上的效果和 cudnn、cublas 等手动调优的算子库还有不少差距,另外 TVM 在性能调优时需要耗费比较长的时间。上述两点原因阻碍了 TVM 在真实的推理部署场景中得到很好的应用。

基于 CUTLASS 的卷积算子开发框架
算子优化的长尾问题
算子优化的长尾问题
// 定义输入 feature map tensor 的 layoutusing LayoutSrc = cutlass::layout::TensorNCxHWx<32>;// 定义输入 weight tensor 的 layoutusing LayoutFilter = cutlass::layout::TensorCxRSKx<32>;// 定义线程块的分块大小,M,N,Kusing ThreadBlockShape = cutlass::gemm::GemmShape<32, 64, 64>;// 定义 warp 的分块大小,M,N,Kusing WarpShape = cutlass::gemm::GemmShape<32, 16, 64>;// 定义 Matrix Multiply-Add 指令的矩阵分块大小,M,N,Kusing InstructionShape = cutlass::gemm::GemmShape<8, 8, 16>;// 定义卷积后处理 operatorusing EpilogueOp = cutlass::epilogue::thread::BiasAddLinearCombinationReluClamp<int8_t, 8,int32_t, int32_t, float>;using Convolution = cutlass::convolution::device::Convolution<int8_t, // 输入 feature map 的 data typeLayoutSrc, // 输入 feature map 的 layoutint8_t, // 输入 weight 的 data typeLayoutFilter, // 输入 weight 的 layoutint8_t, // 输出 tensor 的 data typeLayoutSrc, // 输出 tensor 的 layoutint32_t, // 输入 bias 的 data typeLayoutSrc, // 输入 bias 的 layoutint32_t, // 矩阵乘法内部累加的 data typecutlass::convolution::ConvType::kConvolution,cutlass::arch::OpClassTensorOp,cutlass::arch::Sm75,ThreadBlockShape, WarpShape, InstructionShape,EpilogueOp,cutlass::convolution::threadblock::ConvolutionNCxHWxThreadblockSwizzle<cutlass::Convolution::ConvType::kConvolution>,2, // 2 代表是否开启 shared memory ping-pong prefetch 优化16, 16>; // tensor alignment, 代表 load/store 指令的位宽// 越宽指令吞吐量越高,有助于提升性能Convolution conv_op;typename Convoluition::Arguments args{...};conv_op.initialize(args, workspace);// 执行 convolution 算子conv_op();
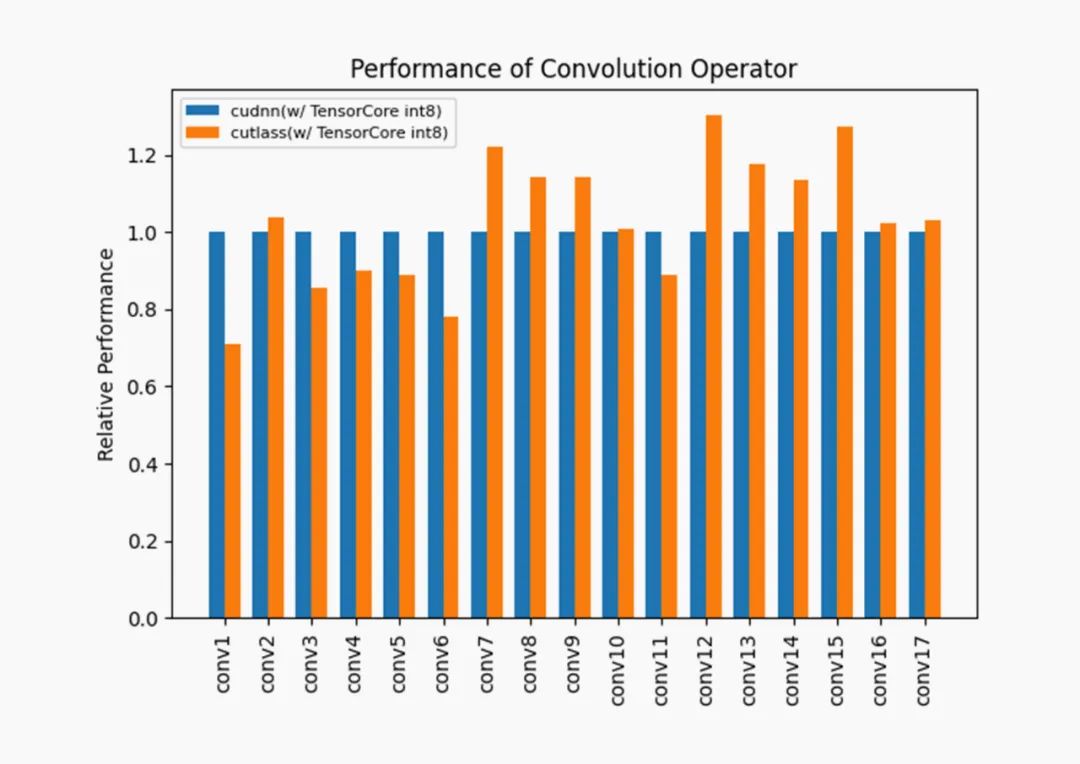
cutlass 在选取的 17 个卷积层下有 11 个卷积层的性能超过了 cudnn,余下的 6 个卷积层的性能也基本达到了 cudnn 的 80%以上。
算子融合
// 定义输入 feature map tensor 的 layoutusing LayoutSrc = cutlass::layout::TensorNCxHWx<4>;// 定义输入 weight tensor 的 layoutusing LayoutFilter = cutlass::layout::TensorCxRSKx<4>;// 定义输出 tensor 的 layoutusing LayoutDst = cutlass::layout::TensorNCxHWx<32>;// 定义线程块的分块大小,M,N,Kusing ThreadBlockShape = cutlass::gemm::GemmShape<64, 128, 32>;// 定义 warp 的分块大小,M,N,Kusing WarpShape = cutlass::gemm::GemmShape<64, 32, 32>;// 定义 Matrix Multiply-Add 指令的矩阵分块大小,M,N,Kusing InstructionShape = cutlass::gemm::GemmShape<1, 1, 4>;// 定义卷积后处理 operatorusing EpilogueOp = cutlass::epilogue::thread::BiasAddLinearCombinationReluClamp<int8_t, 4,int32_t, int32_t, float>;using Convolution = cutlass::convolution::device::Convolution<int8_t, // 输入 feature map 的 data typeLayoutSrc, // 输入 feature map 的 layoutint8_t, // 输入 weight 的 data typeLayoutFilter, // 输入 weight 的 layoutint8_t, // 输出 tensor 的 data typeLayoutDst, // 输出 tensor 的 layoutint32_t, // 输入 bias 的 data typeLayoutDst, // 输入 bias 的 layoutint32_t, // 矩阵乘法内部累加的 data typecutlass::convolution::ConvType::kConvolution,cutlass::arch::OpClassSimt,cutlass::arch::Sm61,ThreadBlockShape, WarpShape, InstructionShape,EpilogueOp,cutlass::convolution::threadblock::ConvolutionNCxHWxThreadblockSwizzle<cutlass::Convolution::ConvType::kConvolution>,2, // 2 代表是否开启 shared memory ping-pong prefetch 优化4, 16>; // tensor alignment, 代表 load/store 指令的位宽// 越宽指令吞吐量越高,有助于提升性能Convolution conv_op;typename Convoluition::Arguments args{...};conv_op.initialize(args, workspace);// 执行 convolution 算子conv_op();
定制卷积算子
自定义激活函数
template <typename ElementOutput_,int Count,typename ElementAccumulator_ = ElementOutput_,typename ElementBias_ = ElementOutput_,typename ElementCompute_ = ElementOutput_,FloatRoundStyle Round = FloatRoundStyle::round_to_nearest,typename Policy = NumericArrayConverterPolicy<ElementOutput_, Count,ElementAccumulator_, ElementBias_,ElementCompute_, Round>>class BiasAddLinearCombinationHSwishClamp {/// 定义 Param、构造函数等,这里省略部分代码/// ...public:CUTLASS_HOST_DEVICEFragmentOutput operator()(FragmentAccumulator const& accumulator,FragmentBias const& bias,FragmentOutput const& source) const {SourceConverter source_converter;AccumulatorConverter accumulator_converter;BiasConverter bias_converter;ComputeFragment converted_source = source_converter(source);ComputeFragment converted_accumulator =accumulator_converter(accumulator);ComputeFragmentBias converted_bias = bias_converter(bias);ComputeFragment intermediate;multiplies<ComputeFragment> mul_add_source;multiply_add<ComputeFragment> mul_add_accumulator;multiply_add<ComputeFragmentBias> mul_add_bias;HSwish<ComputeFragment> hswish;minimum<ComputeFragment> min_accumulator;maximum<ComputeFragment> max_accumulator;/// 计算+biasintermediate =mul_add_source(gamma_, converted_source);intermediate =mul_add_accumulator(alpha_, converted_accumulator,intermediate);intermediate = mul_add_bias(beta_, converted_bias,intermediate);/// 计算 HSwish 激活intermediate = hswish(scale_, inv_scale_, intermediate);ElementCompute const kClamp = ElementCompute((1U << (sizeof_bits<ElementOutput>::value - 1)) - 1);intermediate =max_accumulator(intermediate, -kClamp - ElementCompute(1));intermediate = min_accumulator(intermediate, kClamp);/// 转换成输出的 data typeOutputConverter destination_converter;return destination_converter(intermediate);}};
CUDA 平台的推理部署
按照[文档]介绍的方法 dump 量化好的模型,就可以使用 MegEngine 来完成推理的部署了。
[文档地址] https://megengine.org.cn/doc/advanced/inference_in_nvidia_gpu.html#inference-in-nvidia-gpu
[如何使用 load_and_run] https://megengine.org.cn/doc/advanced/how_to_use_load_and_run.html#how-to-use-load-and-run
./load_and_run resnet18.mge --input ./cat.npy --enable-nchw32 --fast-runmgb load-and-run: using MegBrain 8.9999.0(0) and MegDNN 9.3.0[09 14:14:14 from_argv@mgblar.cpp:1169][WARN] enable nchw32 optimizationload model: 3018.428ms=== prepare: 182.441ms; going to warmup[09 14:11:11 invoke@system.cpp:492][ERR] timeout is set, but no fork_exec_impl not given; timeout would be ignored[09 14:11:11 invoke@system.cpp:492][ERR] timeout is set, but no fork_exec_impl not given; timeout would be ignored[09 14:11:11 invoke@system.cpp:492][ERR] timeout is set, but no fork_exec_impl not given; timeout would be ignoredwarmup 0: 481.411ms=== going to run input for 10 timesiter 0/10: 19.432ms (exec=0.754,device=19.307)iter 1/10: 18.537ms (exec=0.899,device=18.497)iter 2/10: 18.802ms (exec=0.727,device=18.762)iter 3/10: 18.791ms (exec=0.653,device=18.759)iter 4/10: 18.614ms (exec=0.761,device=18.585)iter 5/10: 18.529ms (exec=0.708,device=18.499)iter 6/10: 18.660ms (exec=0.706,device=18.634)iter 7/10: 18.917ms (exec=0.667,device=18.894)iter 8/10: 19.093ms (exec=0.655,device=19.070)iter 9/10: 19.211ms (exec=0.630,device=19.187)=== finished test #0: time=188.586ms avg_time=18.859ms sd=0.304ms minmax=18.529,19.432
总结
参考文献
欢迎访问
-
MegEngine Website:
https://megengine.org.cn -
MegEngine GitHub(欢迎Star):
https://github.com/MegEngine

登录查看更多
相关内容
Arxiv
0+阅读 · 2020年12月2日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年12月2日