卫星图片重建洛杉矶3D模型,效果就像谷歌地球,港中大团队提出CityNeRF
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
看到下面这张动图,你会想到什么?是谷歌地球,还是苹果自带的3D地图?

其实都不是,它是用卫星和航拍图片直接渲染生成的洛杉矶。
很难想象,如此精细的城市3D模型,竟然是用几张不同角度和高度的2D图片重建的。
这项研究来自香港中文大学多媒体实验室团队,叫做CityNeRF。
说到这里,有人应该想到了这两年大热的“神经辐射场”(NeRF),它可以用多张角度照片重建3D对象,性能出色。量子位之前对此进行了相关报道和解读。

NeRF虽然恢复室内场景效果惊艳,但是直接用到城市级的卫星地图上,却面临着巨大的挑战。
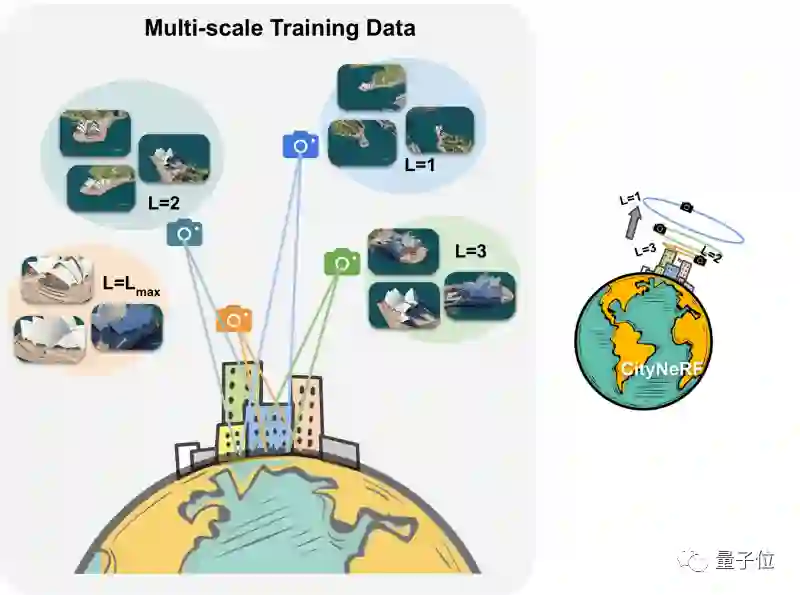
首先是拍摄相机有很大的运动自由度。随着相机的上升,场景中的地物外观越来越粗糙,几何细节越来越少,纹理分辨率越来越低。
同时,随着空间覆盖范围的扩大,来自外围区域的新对象会加入到视图中。

相机在这个一系列场景中,产生了具有不同细节级别和空间覆盖范围的多尺度数据。
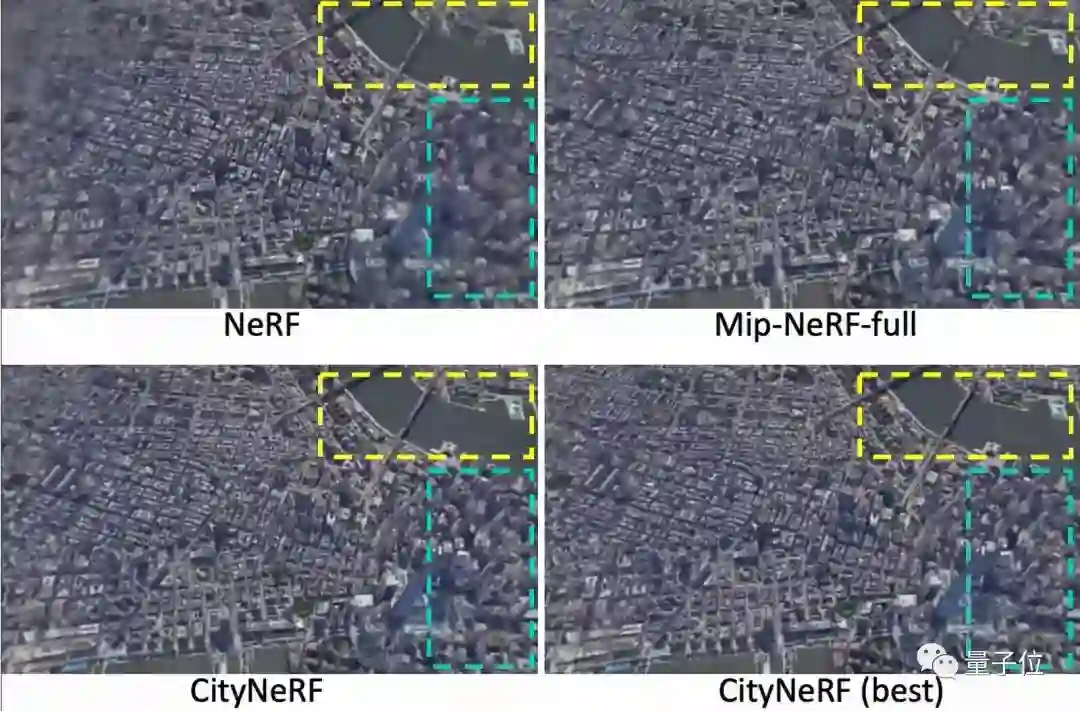
如果使用原来的NeRF渲染,那么生成的远景往往不完整,周边场景区域存在伪影,近景总是具有模糊的纹理和形状。
什么原理?
针对上述问题,作者提出了采用多阶段渐进式学习范式的CityNeRF。
作者根据相机距离将整个训练数据集划分为预定义数量的尺度。从最远的尺度开始,每个训练阶段逐渐将训练集扩大一个更近的尺度,并同步增长模型。
通过这种方式,CityNeRF可以稳健地学习跨场景所有尺度的表示层次结构。
CityNeRF引入了两个特殊的设计:
1、具有残差块结构的生长模型:
在每个训练阶段附加一个额外的块来扩展模型。每个块都有自己的输出head,用于预测连续阶段之间的颜色和密度残差,促使块在近距离观察中关注新兴细节;
2、包容的多级数据监督:
每个块的输出head由从最远尺度到其对应尺度的图像联合监督。
换句话说,最后一个块接受所有训练图像的监督,而最早的块只暴露于最粗尺度的图像。通过这样的设计,每个块模块都能够充分利用其能力,在更近的视图中对复杂的细节进行建模,并保证尺度之间一致的渲染质量。
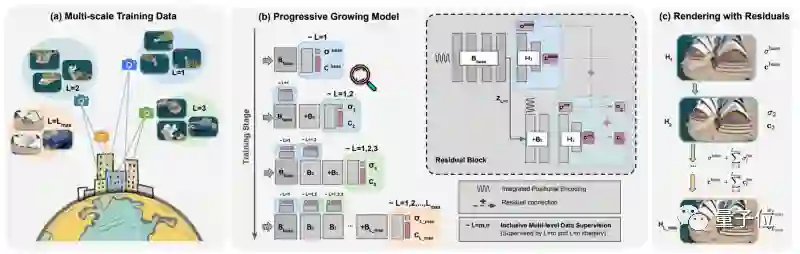
总体来说,CityNeRF是一种渐进式学习范式,可同步增长NeRF模型和训练集。从用浅基块拟合远景开始,随着训练的进行,添加新的块以适应越来越近的视图中出现的细节。
该策略有效地激活了位置编码中的高频通道,并随着训练的进行展开更复杂的细节。
简而言之,使用基本神经网络多层感知器的权重,NeRF将提前处理所有图像,知道其观点位置。NeRF将使用相机的光线找到每个像素的颜色和密度。
因此,它知道相机的方向,并可以同时使用所有数组来了解深度和相应的颜色。然后,使用损失函数优化了神经网络的收敛性,
模型训练数据数据来自Google Earth Studio中的12个城市图像。结果显示在几种常见重建模型中达到了最佳的效果。

最后,作者又将该模型用于重建无人机拍摄的空中图像,依然收到了更佳的效果。

团队简介
本篇论文的两位一作是来自香港中文大学MMLab的两位博士生相里元博和徐霖宁。前者曾有一篇论文被ICLR 2020收录,后者有多篇论文被CVPR、ICCV等顶会收录。

通讯作者是以上两位的导师林达华。

林达华是香港中文大学信息工程系副教授,也是港中大-商汤科技联合实验室主任。
论文地址:
https://arxiv.org/abs/2112.05504
项目地址:
https://city-super.github.io/citynerf/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


