GPU BERT上线性能不合格,看看微信AI的PPoPP论文

问题背景
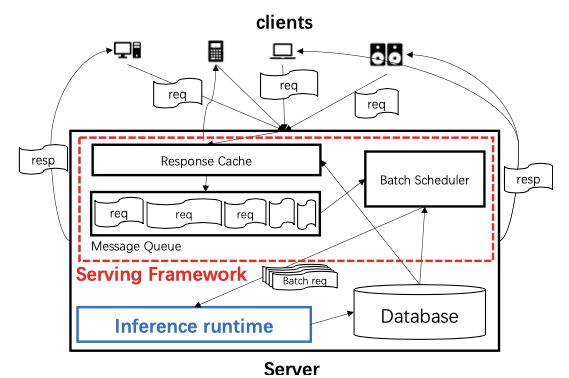
高效的批量规约化方法
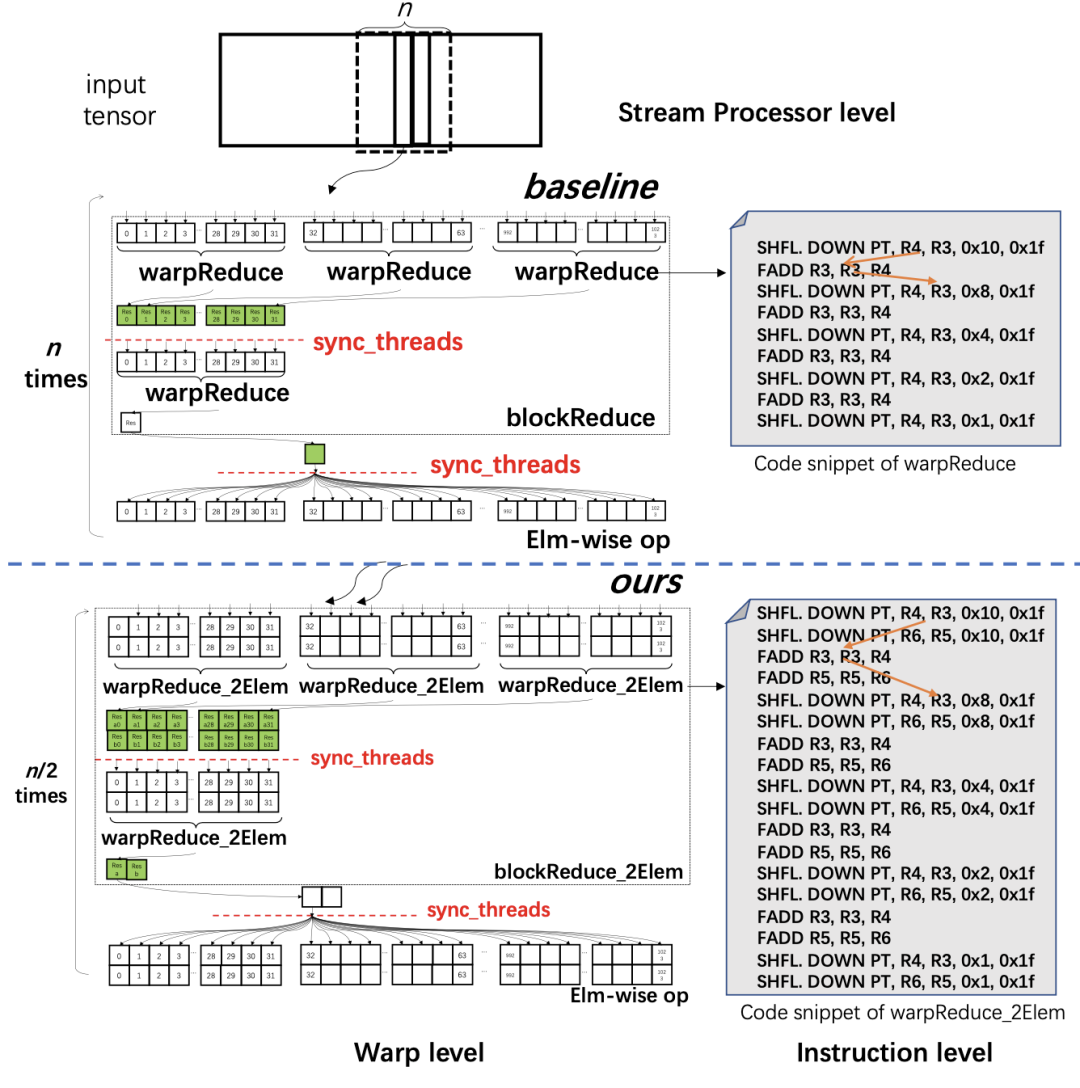
可感知序列长度的内存分配算法
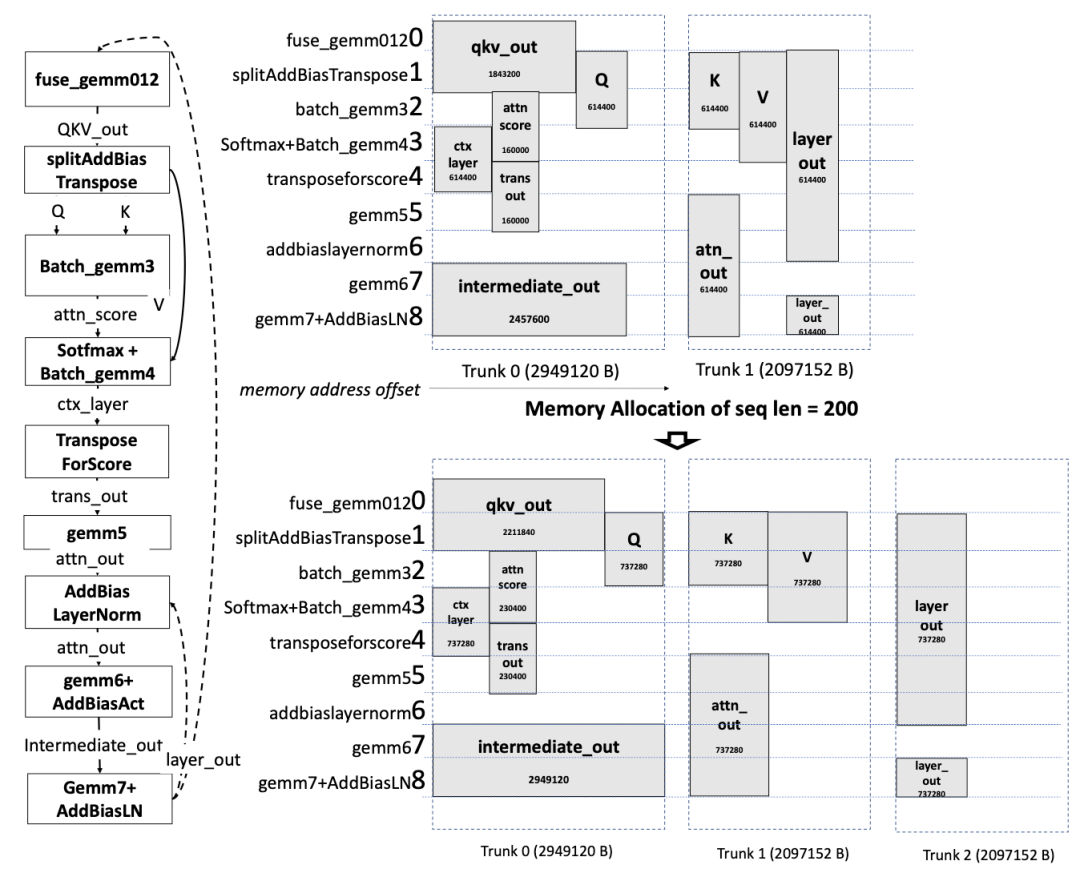
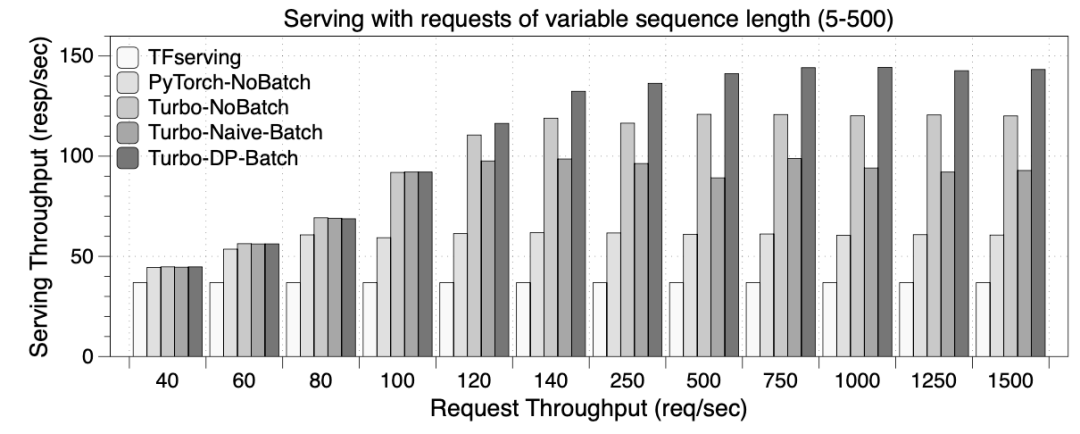
可感知序列长度的服务批处理算法
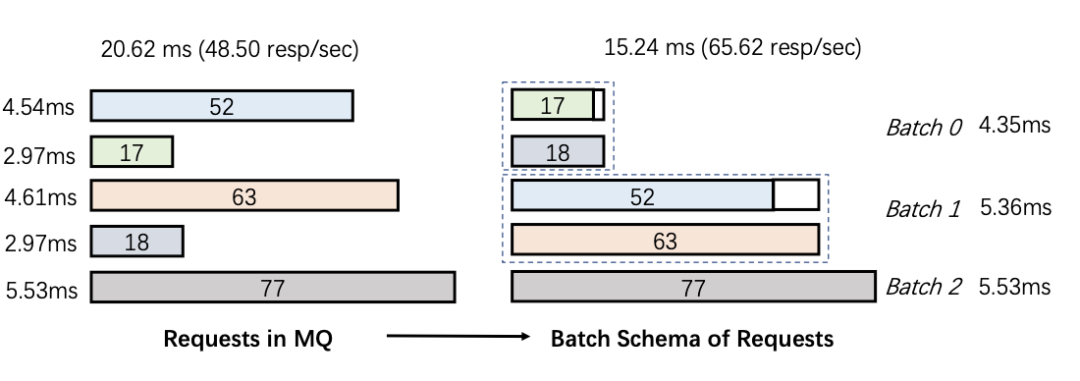
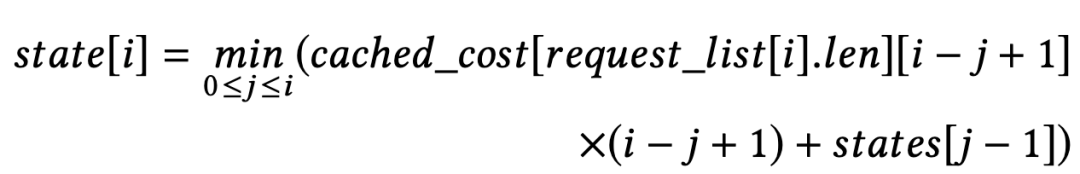
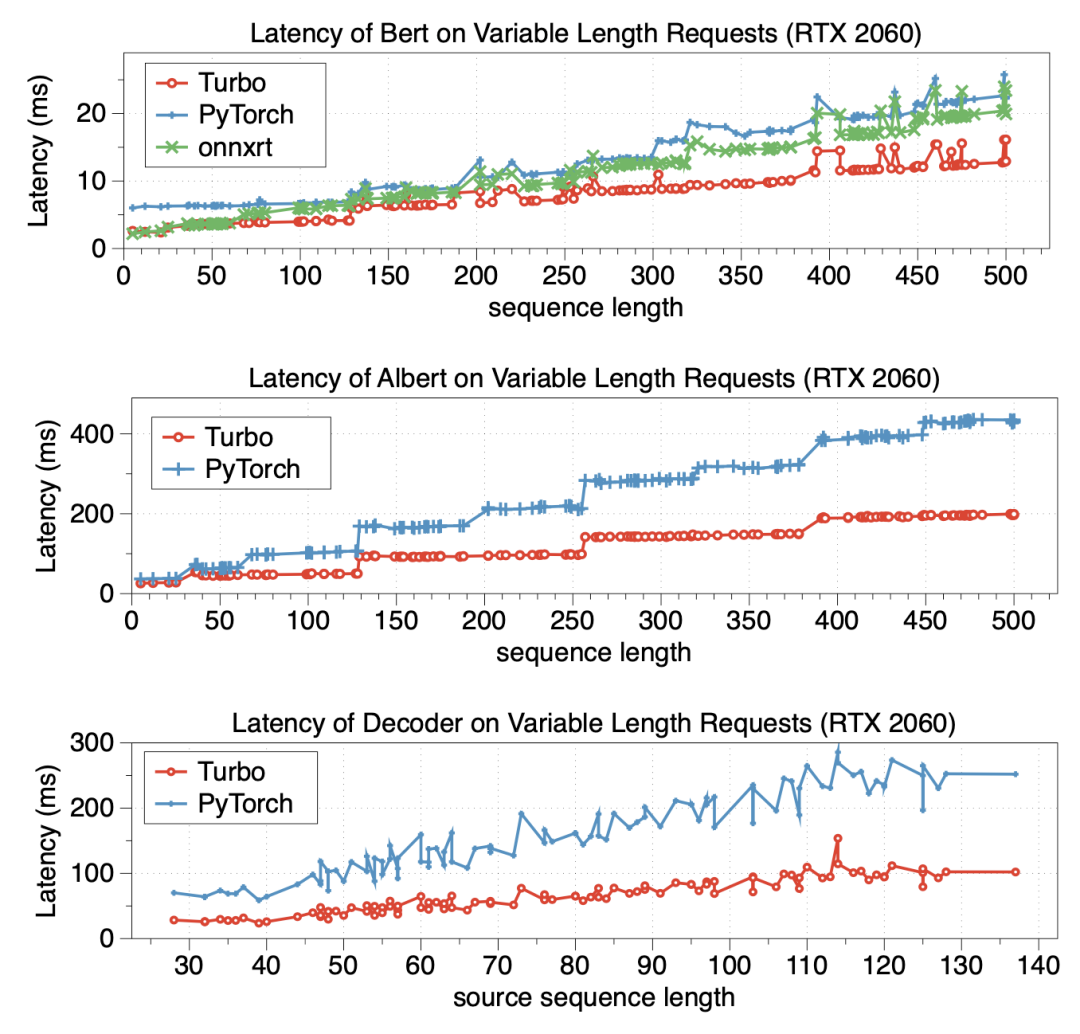
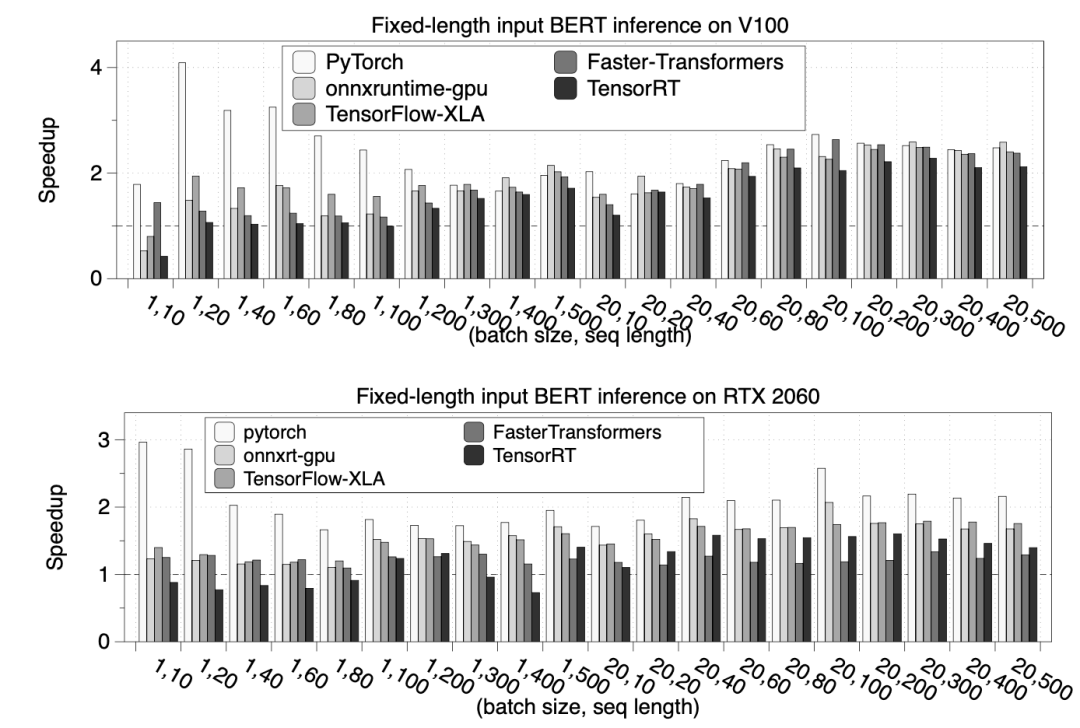
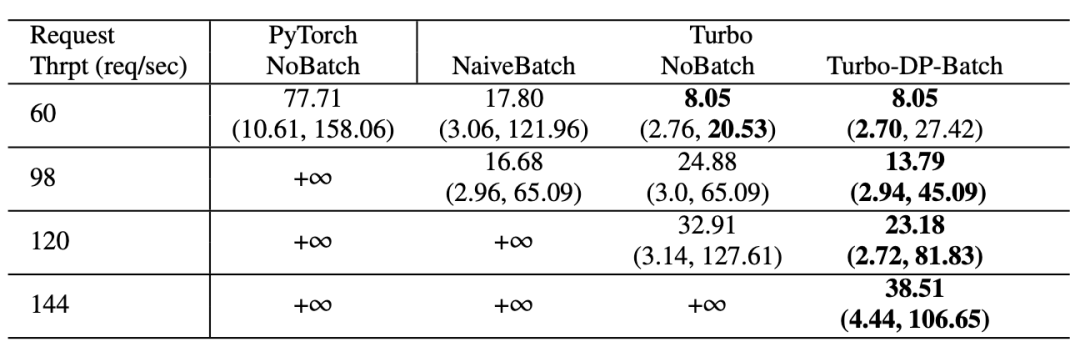
实验效果
总 结
未来工作
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。

登录查看更多
相关内容

PPoPP:ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming。
Explanation:ACM-SIGPLAN并行编程原理与实践研讨会。
Publisher:ACM。
SIT:http://dblp.uni-trier.de/db/conf/ppopp/
相关主题




相关VIP内容
相关资讯
相关论文