谷歌用3亿张图做了个深度学习实验,结论:数据还是越大越好

陈桦 编译自 Google Blog
量子位 报道 | 公众号 QbitAI
都说深度学习的兴起和大数据息息相关,那么是不是数据集越大,训练出的图像识别算法准确率就越高呢?
Google的研究人员用3亿张图的内部数据集做了实验,然后写了篇论文。他们指出,在深度模型中,视觉任务性能随训练数据量(取对数)的增加,线性上升。
以下是Google Research机器感知组指导教师,卡耐基梅隆大学助理教授Abhinav Gupta对这项工作的介绍,发布在Google Research官方博客上,量子位编译:
过去10年,计算机视觉技术取得了很大的成功,其中大部分可以归功于深度学习模型的应用。此外自2012年以来,这类系统的表现能力有了很大的进步,原因包括:
1)复杂度更高的深度模型;
2)计算性能的提升;
3)大规模标签数据的出现。
每年,我们都能看到计算性能和模型复杂度的提升,从2012年7层的AlexNet,发展到2015年101层的ResNet。
然而,可用数据集的规模却没有成比例地扩大。101层的ResNet在训练时仍然用着和AlexNet一样的数据集:ImageNet中的10万张图。
作为研究者,我们一直在关注这样的问题:如果能将训练数据集扩大10倍,精确度是否会有成倍的提升?如果数据集扩大100倍或300倍又会怎样?精确度会停滞不前,还是随着数据量的增长不断提升?
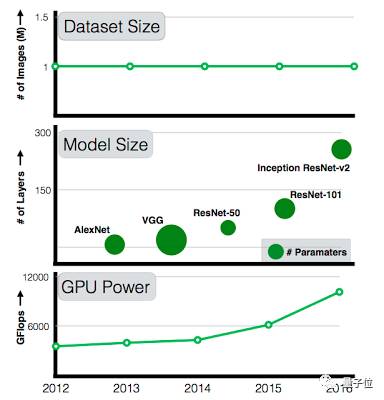
△ 过去5年间,GPU计算力和模型复杂度都在持续增长,但训练数据集的规模没有任何变化
在论文Revisit the Unreasonable Effectiveness of Data中,我们迈出了第一步,探索“大量数据”与深度学习之间的关系。我们的目标是研究:
1)使用当前的算法,如果提供越来越多带噪声标签的图片,视觉表现是否仍然可以得到优化;
2)对于标准的视觉任务,例如分类、对象探测,以及图像分割,数据和性能之间的关系是什么;
3)利用大规模学习技术,开发能胜任计算机视觉领域各类任务的最先进的模型。
当然,问题的关键在于,我们要从何处找到比ImageNet大300倍的数据集。
Google一直努力构建这样的数据集,以优化计算机视觉算法。在Geoff Hinton、Francois Chollet等人的努力下,Google内部构建了一个包含3亿张图片的数据集,将其中的图片标记为18291个类,并将其命名为JFT-300M。
图片标记所用的算法混合了复杂的原始网络信号,以及网页和用户反馈之间的关联。
通过这种方法,这3亿张图片获得了超过10亿个标签(一张图片可以有多个标签)。在这10亿个标签中,约3.75亿个通过算法被选出,使所选择图片的标签精确度最大化。然而,这些标签中依然存在噪声:被选出图片的标签约有20%是噪声。
我们的实验验证了一些假设,但也带来了意料之外的结果:
更好的表征学习(Representation Learning)能带来帮助。
我们观察到的首个现象是,大规模数据有助于表征学习,从而优化我们所研究的所有视觉任务的性能。
我们的发现表明,建立用于预训练的大规模数据集很重要。这还说明无监督表征学习,以及半监督表征学习方法有良好的前景。看起来,数据规模继续压制了标签中存在的噪声。
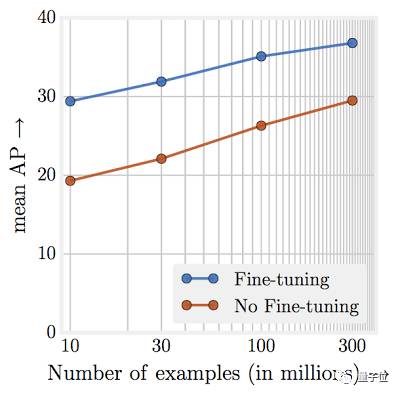
随着训练数据数量级的增加,任务性能呈线性上升。
或许最令人惊讶的发现在于,视觉任务性能和表现学习训练数据量(取对数)之间的关系。我们发现,这样的关系仍然是线性的。即使训练图片规模达到3亿张,我们也没有观察到性能上升出现停滞。如下图所示:
模型容量非常关键。
我们观察到,如果希望完整利用3亿张图的数据集,我们需要更大容量(更深)的模型。
例如,对于ResNet-50,COCO对象探测得分的上升很有限,只有1.87%,而使用ResNet-152,这一得分上升达到3%。
新的最高水准结果。
我们的论文用JFT-300M去训练模型,多项得分都达到了业界最高水准。例如,对于COCO对象探测得分,单个模型目前可以实现37.4 AP,高于此前的34.3 AP。
需要指出,我们使用的训练体系、学习进度以及参数基于此前用ImageNet 1M图片训练ConvNets获得的经验。
由于我们并未在这项工作中探索最优的超参数(这将需要可观的计算工作),因此很有可能,我们还没有得到利用这一数据集进行训练能取得的最佳结果。因此我们认为,量化的性能报告可能低估了这一数据集的实际影响。
这项工作并未关注针对特定任务的数据,例如研究更多边界框是否会影响模型的性能。我们认为,尽管存在挑战,但获得针对特定任务的大规模数据集应当是未来研究的一个关注点。
此外,构建包含300M图片的数据集并不是最终目标。我们应当探索,凭借更庞大的数据集(包含超过10亿图片),模型是否还能继续优化。
Google Research Blog原文:https://research.googleblog.com/2017/07/revisiting-unreasonable-effectiveness.html
相关论文:Revisiting the Unreasonable Effectiveness of Data
https://arxiv.org/abs/1707.02968
你可能还关心那个3亿张图的数据集。它目前还是Google内部用品,这两篇论文提到过它:
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, Jeff Dean
https://arxiv.org/abs/1503.02531
Xception: Deep Learning with Depthwise Separable Convolutions
Franc¸ois Chollet
https://arxiv.org/abs/1610.02357
【完】


点击下方“阅读原文”下载同声译
↓↓↓



