Spark精华问答 | Spark的计算方法是什么?
戳蓝字“CSDN云计算”关注我们哦!

Spark是一个针对超大数据集合的低延迟的集群分布式计算系统,比MapReducer快40倍左右,是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。今天,就让我们一起来看看关于它的更加深度精华问答吧!

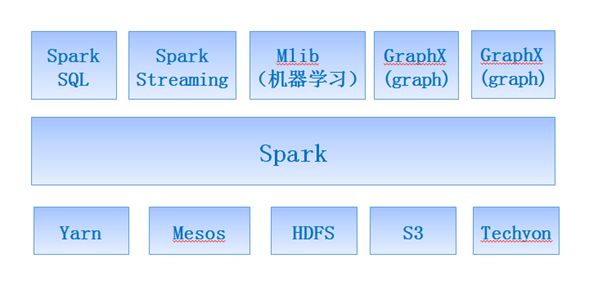
Q:Spark生态圈介绍
A:Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;使用Spark,可以实现MapReduce应用;基于Spark,Spark SQL可以实现即席查询,Spark Streaming可以处理实时应用,MLib可以实现机器学习算法,GraphX可以实现图计算,SparkR可以实现复杂数学计算。
Q:Spark的组成部分。
A:Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
它的主要组件有:
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
Q:Spark的应用场景是什么?
A:Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和即席查询等
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等。
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。
Q:在其他机器上部署了HDFS、HBase、Spark,请问怎么在本地调试Java Spark来操作远程的HBase,就像操作远程数据库一样?
A:1. HBase是一个数据库(分布式),有自己的JDBC,可以根据HBase的JDBC开发自己应用, 只要能连接上,本地远程都可以。
2. Spark集群部署好了,写好Spark作业提交给Spark集群,Spark cluster计算完成后,可以参看结果。
3. Spark相关的rest server是livy,然而并不是很好用有一定的版本和环境要求,很多开发者会选择避开这个坑,所以你会看到网上的大部分博客。
4. 推荐Linux环境下开发,少爬很多坑,Windows不适合大数据相关的开发。
Q:Spark的计算方法是什么?
A:Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
当下Spark已不止步于实时计算,目标直指通用大数据处理平台,而终止Shark,开启SparkSQL或许已经初见端倪。
近几年来,大数据机器学习和数据挖掘的并行化算法研究成为大数据领域一个较为重要的研究热点。早几年国内外研究者和业界比较关注的是在 Hadoop 平台上的并行化算法设计。然而, HadoopMapReduce 平台由于网络和磁盘读写开销大,难以高效地实现需要大量迭代计算的机器学习并行化算法。
随着 UC Berkeley AMPLab 推出的新一代大数据平台 Spark 系统的出现和逐步发展成熟,近年来国内外开始关注在 Spark 平台上如何实现各种机器学习和数据挖掘并行化算法设计。为了方便一般应用领域的数据分析人员使用所熟悉的 R 语言在 Spark 平台上完成数据分析,Spark 提供了一个称为 SparkR 的编程接口,使得一般应用领域的数据分析人员可以在 R 语言的环境里方便地使用 Spark 的并行化编程接口和强大计算能力。
小伙伴们冲鸭,后台留言区等着你!
关于Spark,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~

福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
Elastic Jeff Yoshimura:开源正在开启新一轮的创新 | 人物志
深入浅出Docker 镜像 | 技术头条
19岁当老板, 20岁ICO失败, 21岁将项目挂到了eBay, 为何初创公司如此艰难?
码二代的出路是什么?
机器学习萌新必备的三种优化算法 | 选型指南
小程序的侵权“生死局”
@996 程序员,ICU 你真的去不起!