当 Mars 遇上 RAPIDS:用 GPU 加速数据科学

Numpy
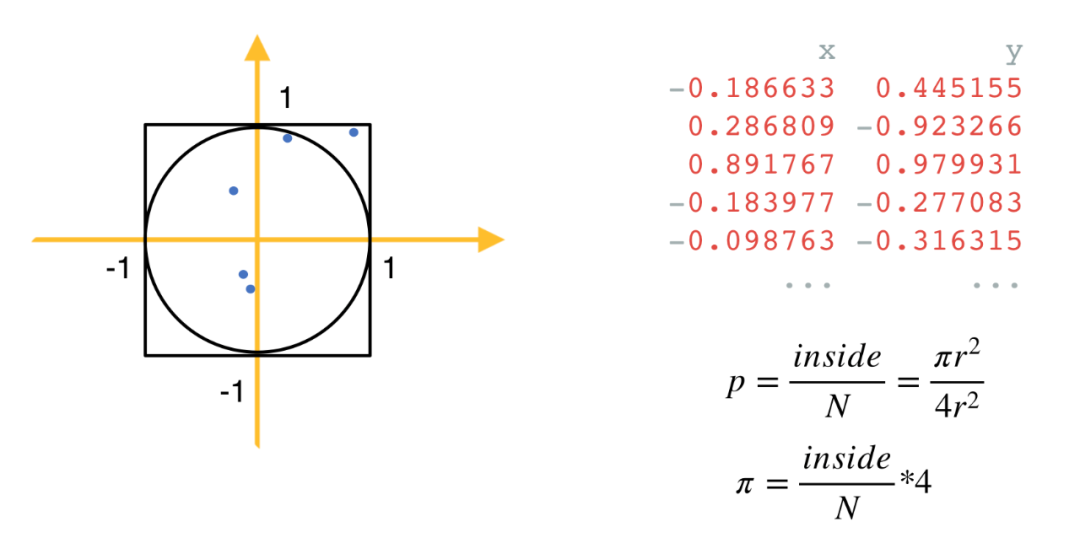
import numpy as np
N = 10 ** 7 # 1千万个点
data = np.random.uniform(-1, 1, size=(N, 2)) # 生成1千万个x轴和y轴都介于-1和1间的点inside = (np.sqrt((data ** 2).sum(axis=1)) < 1).sum() # 计算到原点的距离小于1的点的个数pi = 4 * inside / Nprint('pi: %.5f' % pi)
pandas
import pandas as pd
ratings = pd.read_csv('ml-20m/ratings.csv')ratings.groupby('userId').agg({'rating': ['sum', 'mean', 'max', 'min']})
scikit-learn
import pandas as pdfrom sklearn.neighbors import NearestNeighbors
df = pd.read_csv('data.csv') # 输入是 CSV 文件,包含 20万个向量,每个向量10个元素nn = NearestNeighbors(n_neighbors=10)nn.fit(df)neighbors = nn.kneighbors(df)
Mars —— Numpy、pandas 和 scikit-learn 的并行和分布式加速器
现在是多核时代,这几个库里鲜有操作能利用得上多核的能力。
随着深度学习的流行,用来加速数据科学的新的硬件层出不穷,这其中最常见的就是 GPU,在深度学习前序流程中进行数据处理,我们是不是也能用上 GPU 来加速呢?
这几个库的操作都是命令式的(imperative),和命令式相对应的就是声明式(declarative)。命令式的更关心 how to do,每一个操作都会立即得到结果,方便对结果进行探索,优点是很灵活;缺点则是中间过程可能占用大量内存,不能及时释放,而且每个操作之间就被割裂了,没有办法做算子融合来提升性能;那相对应的声明式就刚好相反,它更关心 what to do,它只关心结果是什么,中间怎么做并没有这么关心,典型的声明式像 SQL、TensorFlow 1.x,声明式可以等用户真正需要结果的时候才去执行,也就是 lazy evaluation,这中间过程就可以做大量的优化,因此性能上也会有更好的表现,缺点自然也就是命令式的优点,它不够灵活,调试起来比较困难。
我们希望 Mars 足够简单,只要会用 Numpy、pandas 或 scikit-learn 就会用 Mars。
避免重复造轮子,我们希望能利用到这些库已有的成果,只需要能让他们被调度到多核/多机上即可。
声明式和命令式兼得,用户可以在这两者之间自由选择,灵活度和性能兼而有之。
足够健壮,生产可用,能应付各种 failover 的情况。
Mars tensor:Numpy 的并行和分布式加速器
import mars.tensor as mt
N = 10 ** 10
data = mt.random.uniform(-1, 1, size=(N, 2))inside = (mt.sqrt((data ** 2).sum(axis=1)) < 1).sum()pi = (4 * inside / N).execute()print('pi: %.5f' % pi)
import mars.tensor as mtfrom mars.config import options
options.eager_mode = True # 打开 eager mode 后,每一次调用都会立即执行,行为和 Numpy 就完全一致
N = 10 ** 7
data = mt.random.uniform(-1, 1, size=(N, 2))inside = (mt.linalg.norm(data, axis=1) < 1).sum()pi = 4 * inside / N # 不需要调用 .execute() 了print('pi: %.5f' % pi.fetch()) # 目前需要 fetch() 来转成 float 类型,后续我们会加入自动转换
Mars DataFrame:pandas 的并行和分布式加速器
import mars.dataframe as mdratings = md.read_csv('ml-20m/ratings.csv')ratings.groupby('userId').agg({'rating': ['sum', 'mean', 'max', 'min']}).execute()
Mars Learn:scikit-learn 的并行和分布式加速器
import mars.dataframe as mdfrom mars.learn.neighbors import NearestNeighbors
df = md.read_csv('data.csv') # 输入是 CSV 文件,包含 20万个向量,每个向量10个元素nn = NearestNeighbors(n_neighbors=10)nn.fit(df) # 这里 fit 的时候也会整体触发执行,因此机器学习的高层接口都是立即执行的neighbors = nn.kneighbors(df).fetch() # kneighbors 也已经触发执行,只需要 fetch 数据
RAPIDS:GPU 上的数据科学
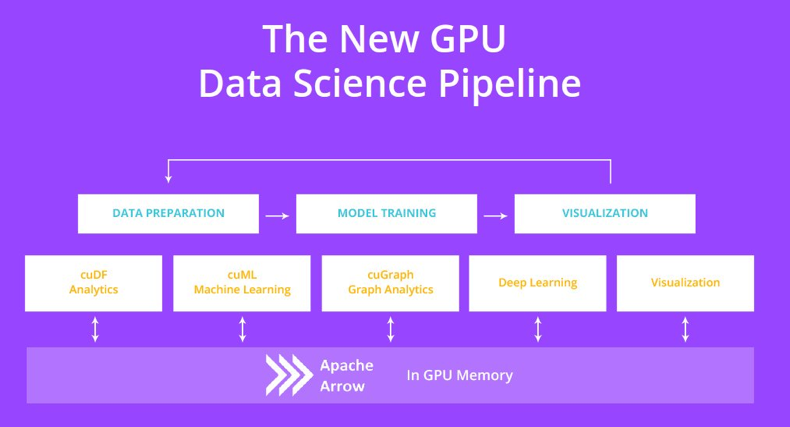
CuPy:用 GPU 加速 Numpy
import cupy as cp N = 10 ** 7
data = cp.random.uniform(-1, 1, size=(N, 2))inside = (cp.sqrt((data ** 2).sum(axis=1)) < 1).sum()pi = 4 * inside / Nprint('pi: %.5f' % pi)
RAPIDS cuDF:用 GPU 加速 pandas
import cudf
ratings = cudf.read_csv('ml-20m/ratings.csv')ratings.groupby('userId').agg({'rating': ['sum', 'mean', 'max', 'min']})
RAPIDS cuML:用 GPU 加速 scikit-learn
import cudffrom cuml.neighbors import NearestNeighbors
df = cudf.read_csv('data.csv')nn = NearestNeighbors(n_neighbors=10)nn.fit(df)neighbors = nn.kneighbors(df)
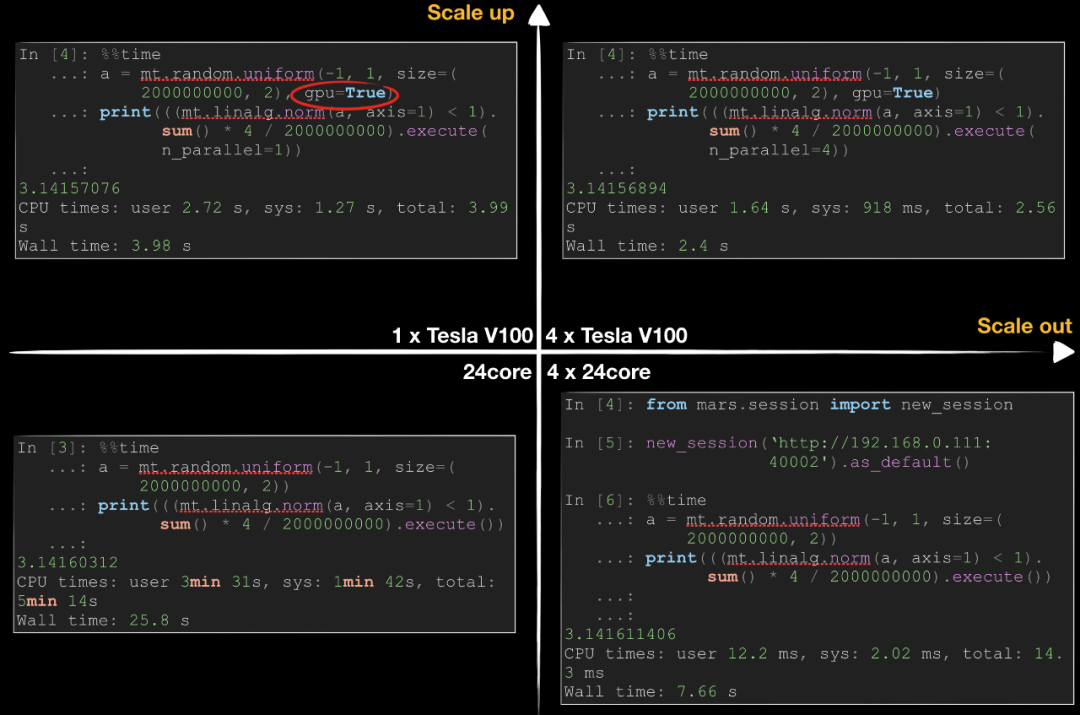
Mars 和 RAPIDS 结合能带来什么?
import mars.tensor as mtimport mars.dataframe as md
a = mt.random.uniform(-1, 1, size=(1000, 1000), gpu=True)df = md.read_csv('ml-20m/ratings.csv', gpu=True)
性能测试
Groupby
查询一:
df = read_csv('data.csv')df.groupby('id1').agg({'v1': 'sum'})
查询二:
df = read_csv('data.csv')df.groupby(['id1', 'id2']).agg({'v1': 'sum'})
查询三:
df = read_csv('data.csv')df.gropuby(['id6']).agg({'v1': 'sum', 'v2': 'sum', 'v3': 'sum'})
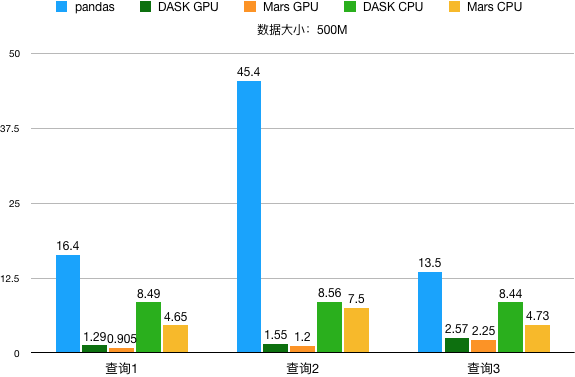
数据大小 500M,性能结果
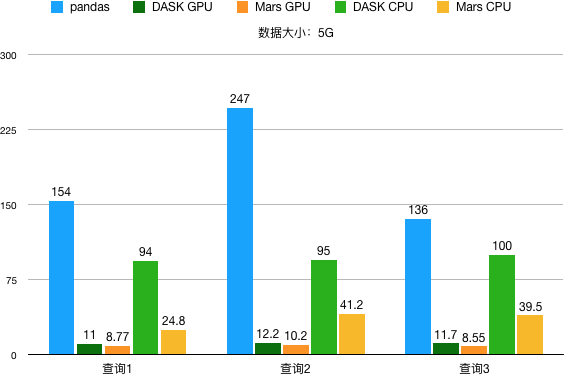
数据大小 5G,性能结果
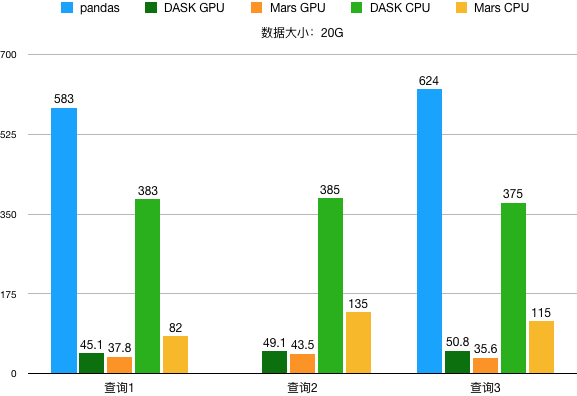
数据大小 20G,性能结果
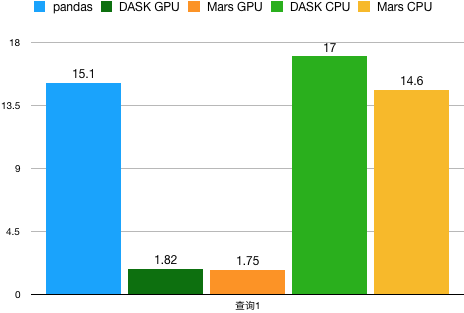
Join
x = read_csv('x.csv')y = read_csv('y.csv')x.merge(y, on='id1')
总结

电子书免费下载
深度解析典型场景大数据实践
《阿里巴巴大数据及 AI 实战》

阿里经济体大数据及 AI 典型场景最佳实践全揭秘!本书将深度剖析淘宝、高德、友盟+、1688、优酷、阿里妈妈、阿里影业大数据实战场景,是 2020 不容错过的企业大数据实战手册。





毕业10年才懂,会升层思考,工作有多轻松?


登录查看更多
相关内容

Scikit-learn项目最早由数据科学家David Cournapeau 在2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
专知会员服务
65+阅读 · 2019年10月27日
Arxiv
7+阅读 · 2020年3月12日
Arxiv
8+阅读 · 2019年5月20日



相关VIP内容
专知会员服务
65+阅读 · 2019年10月27日
相关资讯
相关论文
Arxiv
7+阅读 · 2020年3月12日
Arxiv
8+阅读 · 2019年5月20日