针对各种任务设计合适的损失函数往往需要消耗一定的人力成本,一种名为AutoLoss-Zero的新型通用框架可以从零开始搜索损失函数,使成本大大降低。
近年来,自动机器学习(AutoML)在模型结构、训练策略等众多深度学习领域取得了进展。然而,损失函数作为深度学习模型训练中不可或缺的部分,仍然缺乏良好的探索。目前,多数研究工作仍然使用交叉熵损失(Cross-Entropy Loss)、范数损失(L1/L2 Loss)来监督网络训练。尽管这类损失函数在多数情况下可以取得不错的效果,但它们与网络在测试时使用的评估指标之间大多存在差异,而这种差异会对模型训练效果造成损伤。
为了尽可能减少针对各种任务设计合适的损失函数时所需的人力成本,来自香港中文大学、商汤科技等机构的研究者设计了一个通用的损失函数搜索框架AutoLoss-Zero。为了确保通用性,该方法的搜索空间由一些基本的数学运算组成,而不包括对于某个评价指标的针对性设计。由于此类搜索空间中有效的损失函数十分稀疏,研究者提出了高效且通用的拒绝机制和梯度等价性检测,以提高搜索的效率。给定任意任务和评价指标,AutoLoss-Zero可以以合理的开销(4张V100,48h内)从随机初始化开始,搜索到与手工设计的损失函数表现相似或更优的损失函数。
![]()
论文地址:https://arxiv.org/abs/2103.14026
AutoLoss-Zero是首个通用于各种任务的损失函数搜索框架,其搜索空间由基本数学运算构成,无需先验知识,可以极大地减少损失函数设计所需的人力。该研究在多项计算机视觉任务(目标检测、语义分割、实例分割、姿态估计)上验证了AutoLoss-Zero的有效性;
该研究提出了高效的拒绝机制,从而快速地筛选掉绝大多数没有希望的损失函数。同时,该研究提出了一个基于梯度的等价性检测,以避免对于彼此等价的损失函数进行重复的评估;
实验表明,该方法搜索出的损失函数可以很好地迁移到不同数据集和网络结构上。
该研究首先定义了搜索目标。给定任意任务上的评价指标 ξ ,该方法尝试搜索一个最优的损失函数 L(y ̂,y;N_ω ),其中N_ω表示参数为ω的网络,y ̂表示网络的预测,y表示网络的训练目标。因此,搜索目标可以表示为一个嵌套优化(nested optimization):
![]()
其中优化目标 f(L;ξ) 表示损失函数 L 在评价指标 ξ 上的得分,ω^* (L) 表示使用损失函数L训练的网络参数,E(⋅) 表示数学期望,S_train 和S_eval 表示搜索过程中使用的训练集和验证集。
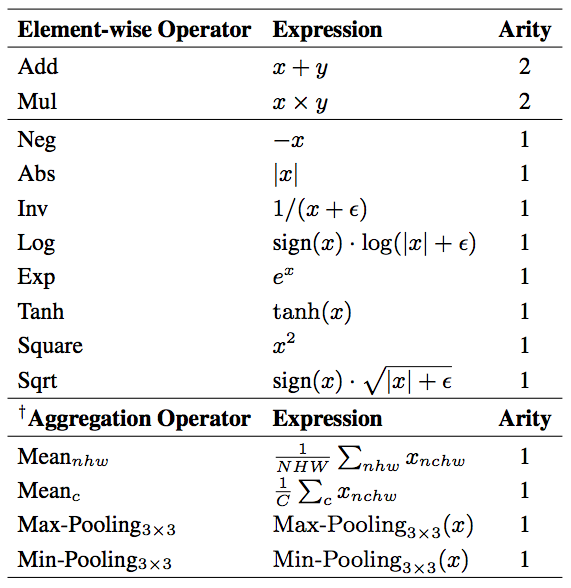
该搜索空间由一些基础的数学运算组成,这个集合称为 H,如下表所示。
![]()
该方法将损失函数表示为一个计算图 G。G 是一个有根树(rooted tree),其中叶子节点表示损失函数的输入(即网络预测 y ^和训练目标 y),根节点表示损失函数的输出 o,其他的中间节点从表中的数学运算里采样得到。此外,该方法还添加一个常数 1 作为损失函数的候选输入,以增加其表示能力。在整个运算图内,所有的张量(tensor)都保持同样的形状 (N,C,H,W),分别代表(batch, channel, height, width)四个维度的尺寸。计算图 G 的输出 o 会被融合(aggregate)为最终的损失值:
![]()
在一些任务中,损失函数由多个分支组成(如目标检测中的分类和边框回归分支)。在这种情况下,我们将每个分支表示为一个独立的计算图 G,并将它们的损失值求和作为最终的损失值。搜索对所有的分支同时进行。
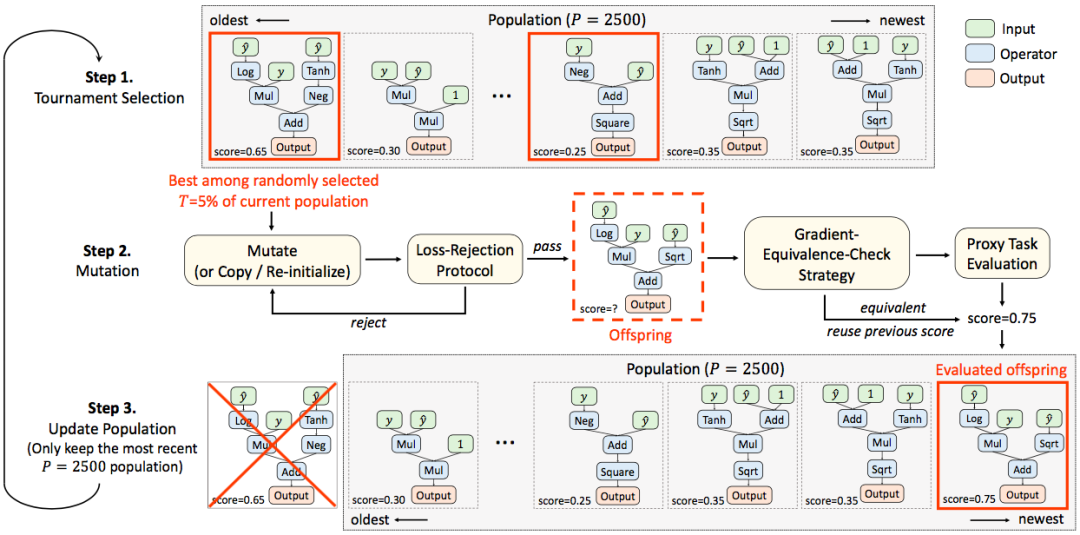
该方法使用进化算法对损失函数进行搜索。图1为整个搜索算法的流程图。
![]()
在搜索初始化阶段,我们首先随机生成 K(默认K=20)个损失函数作为初始种群。此后,每一次更新随机采样当前种群内 T(默认T=5%)比例的损失函数,并对其中在代理任务上得分最高的一个进行变异(mutation),得到后代个体,并加入种群。在种群的更新过程中,只有最新的 P=2500 个个体会被保留。
由于搜索空间中有效的损失函数十分稀疏,尽管代理任务相对于最终的网络训练已经相当简化,但对于每个候选的损失函数都进行代理任务上的评估,时间成本仍然是不可接受的。为此,研究者设计了一个损失函数拒绝机制(loss-rejection protocol),对候选的损失函数进行初步筛选。在损失函数的随机生成和变异过程中,如果候选子代个体无法通过筛选,则重新进行随机生成/变异,直到得到可以通过筛选的损失函数,用于代理任务上的评估。此外,该方法在对候选的损失函数进行评估前,会先检测其是否与已评估过的损失函数等价(gradient-equivalence-check strategy),若等价则跳过代理任务的网络训练,复用之前相同个体的分数。
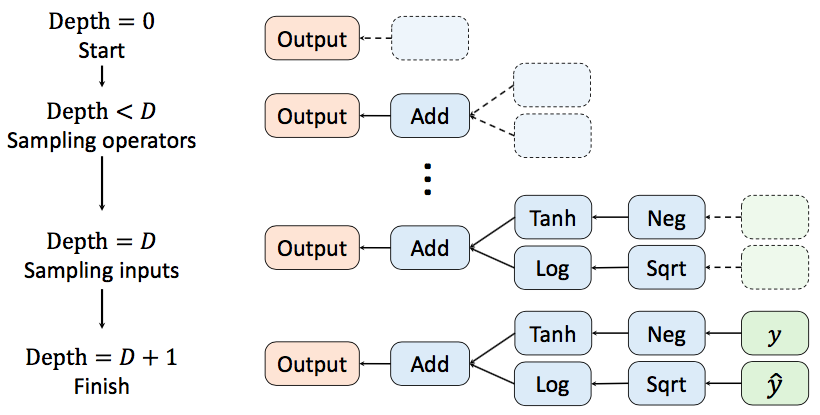
损失函数随机初始化的过程如图2所示。计算图
![]() 从根节点开始,递归地从候选运算集合 H 中随机采样运算符作为其子节点。
每个节点的子节点数由这个节点所代表的运算的操作数决定。
该方法固定随机初始化的计算图深度为 D(默认D=3),在当前节点深度达到 D 后,其从候选的输入集合 {y ^,y,1} 中有放回地随机采样子节点,这些子节点即为计算图的叶子节点。
从根节点开始,递归地从候选运算集合 H 中随机采样运算符作为其子节点。
每个节点的子节点数由这个节点所代表的运算的操作数决定。
该方法固定随机初始化的计算图深度为 D(默认D=3),在当前节点深度达到 D 后,其从候选的输入集合 {y ^,y,1} 中有放回地随机采样子节点,这些子节点即为计算图的叶子节点。
![]()
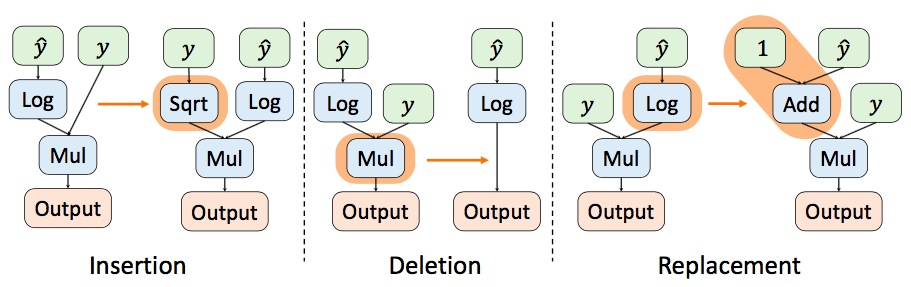
基于该研究提出的损失函数表示形式,研究者定义了三种不同的变异类型:
插入(Insertion),删除(Deletion)及替换(Replacement)
。三种变异类型的示意图如图3所示。
![]()
在每次产生子代的过程中,存在10%的概率不进行变异,而直接复制父代个体。此外,为了鼓励算法进行探索,在变异时,损失函数有50%的概率被重新随机初始化。
搜索的目标是找到可以尽可能最大化评价指标ξ的损失函数 L。基于此,研究者提出一个损失函数L和评价指标ξ之间的相关性分数 g(L;ξ),来衡量一个损失函数对评价指标进行优化的能力。
该研究从训练数据集中随机选择 B 个样本(在实验中统一使用B=5),使用一个随机初始化的网络 N_(ω_0 ) 对这 B 个样本进行计算,并将网络预测 y ^ 和对应的训练目标 y 存储下来,记作 {(y ^_b,y_b )}_(b=1)^B。接下来,通过梯度下降的方式,使用候选的损失函数 L(y ^,y) 对网络预测 y ^ 直接进行优化,并计算优化结果 y ^* 在评价指标 ξ上的得分,即
![]()
g(L;ξ) 即为优化结果相对于初始预测的提升。这个分数越高,意味着损失函数对评价指标的优化能力越强。因此,该研究设置了一个阈值 η(实验中默认η=0.6),相关性分数 g(L;ξ) 低于此阈值的损失函数被认为是没有希望(unpromising)的,会被直接拒绝。在此过程中并没有网络计算的参与,而是直接对输入进行优化,这使得该损失函数拒绝机制十分高效。实验表明,在一个 GPU 上,每分钟可以筛选 500~1000 个候选损失函数。这大大提高了算法探索搜索空间的能力。
为了避免对于相互等价的损失函数进行重复的代理任务评估,对于每个评估过的损失函数,该方法记录其相对于上文「损失函数拒绝机制」中使用的B个样本的梯度的二范数,即
![]() 。
若两个损失函数对于这B个样本,其梯度二范数均相同(取两位有效数字),则我们认为这两个损失函数是等价的,并将较早的损失函数的代理任务分数复用于新的损失函数。
。
若两个损失函数对于这B个样本,其梯度二范数均相同(取两位有效数字),则我们认为这两个损失函数是等价的,并将较早的损失函数的代理任务分数复用于新的损失函数。
该研究在语义分割、目标检测、实例分割和姿态估计等四项计算机视觉任务上从随机初始化开始进行了搜索。此外,该研究对搜索得到的损失函数的泛化性进行了研究,并对前文所提到搜索算法中的各项技术对于搜索效率的影响进行了分析。
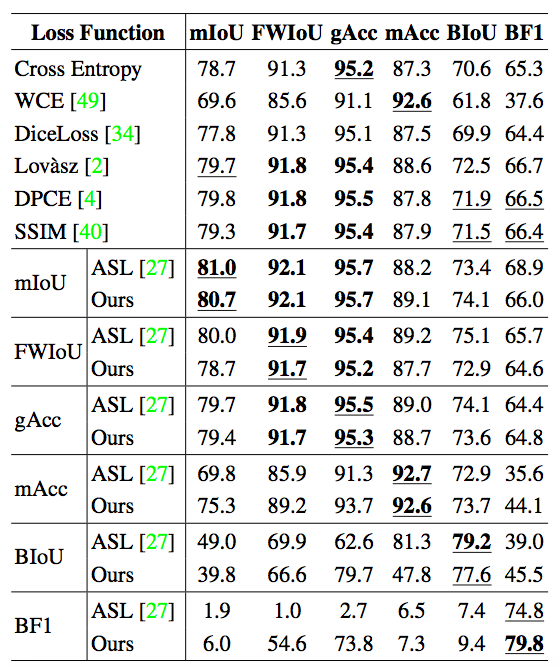
该研究使用 PASCAL VOC 数据集对语义分割任务中主流的 6 个评价指标进行了搜索,并使用得到的损失函数对 DeepLab V3+ 网络进行了重新训练(re-train)。表 2 为该研究的实验结果。该研究将搜索得到的损失函数与常见的基于手工设计的损失函数及自动搜索的损失函数(ASL, Auto Seg-Loss)进行了比较。结果表明,在主流的几个评价指标上,AutoLoss-Zero 搜索到的损失函数
达到或超过了当前最好的结果
,仅在 BIoU 这一指标上略低于为专门关注语义分割任务的 ASL 方法,但也大大超过了现有基于手工设计的损失函数。
![]()
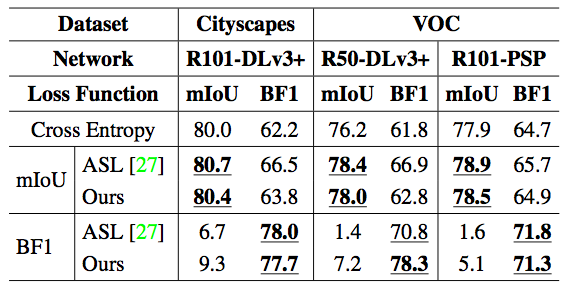
该研究还对搜索得到的损失函数的在不同数据集和不同网络结构上的泛化性进行了验证。表3中,该研究使用ResNet50-DeepLabV3+ 网络在PASCAL VOC上搜索,并将得到的损失函数应用于不同数据集(Cityscapes)和不同网络结构(PSPNet)。表3中的结果表明,该方法搜索得到的损失函数具有良好的泛化性。
![]()
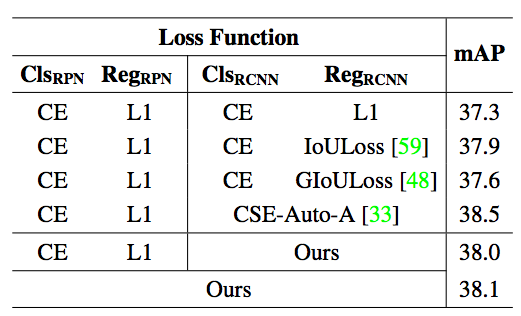
该研究使用 Faster R-CNN 在 COCO 数据集上进行实验。对于 Faster R-CNN 中的四个损失函数分支(RPN 网络的分类、回归,Fast R-CNN 子网络的分类、回归),该方法同时进行搜索。表 4 给出了该方法与常用的 IoULoss、GIoULoss,以及针对目标检测任务进行损失函数搜索的工作 CSE-AutoLoss-A 进行比较的 结果。实验表明,该方法搜索到的损失函数与这些损失函数表现相似。
![]()
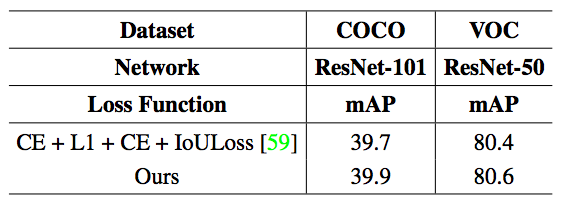
该研究也对目标检测搜索得到的损失函数的泛化性进行了实验。表 5 为实验结果。
![]()
该研究使用 Mask R-CNN 在 COCO数 据集上进行实验,并对五个损失函数分支同时进行搜索。表 6 表明该方法搜索到的损失函数与手工设计的损失函数表现相近。
![]()
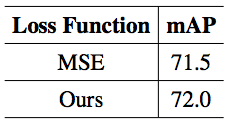
该研究在 COCO 上对姿态估计任务进行了实验。表 7 为实验结果。该研究与姿态估计中常用的均方误差损失(MSE Loss)进行了比较,实验表明,AutoLoss-Zero 从零开始搜索到的损失函数表现略好于 MSE Loss。
![]()
该搜索算法基于进化算法。为了提高搜索效率,研究者设计了
损失函数拒绝机制(Loss-Rejection Protocol)和梯度等价性检测(Gradient-Equivalence-Check Strategy)
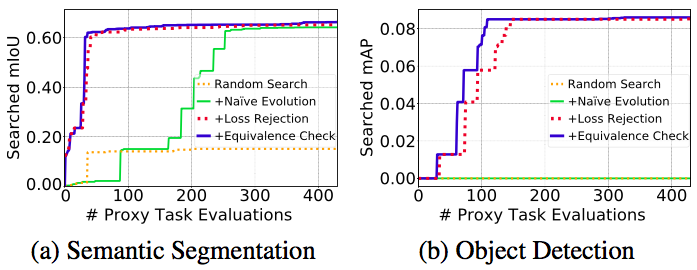
。如图 4 所示,研究者发现这些模块可以有效地提高搜索的效率。尤其是在目标检测任务上,由于同时对 4 个分支进行搜索,搜索空间尤为稀疏,这使得在没有损失函数拒绝机制的情况下,搜索过程无法在合理的时间内(约 400 次代理任务评估)找到任何分数大于 0 的损失函数。这表明高效的拒绝机制是搜索有效的关键。
![]()
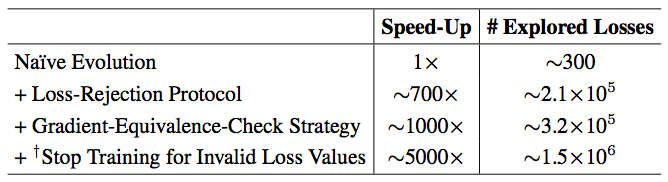
研究者在表 8 中进一步分析了各个模块给搜索效率带来的提升。“满血”的 AutoLoss-Zero 可以在 48 小时内(使用 4 块 V100 GPU)探索超过10^6 个候选损失函数,这使得它可以在庞大而稀疏的搜索空间内有效地探索。
![]()
表8. 目标检测任务的搜索效率分析。(“# Explored Losses”表示算法在48小时内探索的损失函数数量。“Stop Training for Invalid Loss Values”表示网络在代理任务的前20轮更新内即由于出现NaN或Inf而停止了训练。)
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
大会包括主题演讲和六大分会场。内容涵盖亚马逊机器学习实践揭秘、人工智能赋能企业数字化转型、大规模机器学习实现之道、AI 服务助力互联网快速创新、开源开放与前沿趋势、合作共赢的智能生态等诸多话题。
亚马逊云科技技术专家以及各个行业合作伙伴将现身说法,讲解 AI/ML 在实现组织高效运行过程中的巨大作用。每个热爱技术创新的 AI/ML 的爱好者及实践者都不容错过。
识别二维码或点击阅读原文,免费报名看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

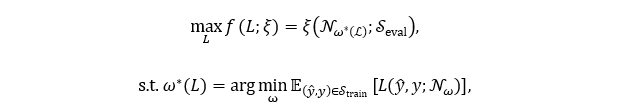
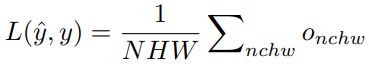
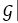 从根节点开始,递归地从候选运算集合 H 中随机采样运算符作为其子节点。
每个节点的子节点数由这个节点所代表的运算的操作数决定。
该方法固定随机初始化的计算图深度为 D(默认D=3),在当前节点深度达到 D 后,其从候选的输入集合 {y ^,y,1} 中有放回地随机采样子节点,这些子节点即为计算图的叶子节点。
从根节点开始,递归地从候选运算集合 H 中随机采样运算符作为其子节点。
每个节点的子节点数由这个节点所代表的运算的操作数决定。
该方法固定随机初始化的计算图深度为 D(默认D=3),在当前节点深度达到 D 后,其从候选的输入集合 {y ^,y,1} 中有放回地随机采样子节点,这些子节点即为计算图的叶子节点。
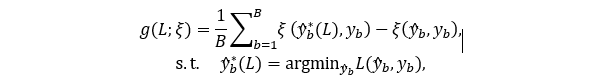
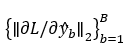 。
若两个损失函数对于这B个样本,其梯度二范数均相同(取两位有效数字),则我们认为这两个损失函数是等价的,并将较早的损失函数的代理任务分数复用于新的损失函数。
。
若两个损失函数对于这B个样本,其梯度二范数均相同(取两位有效数字),则我们认为这两个损失函数是等价的,并将较早的损失函数的代理任务分数复用于新的损失函数。