残次老照片被补全,回忆满满瞬间泪奔...

来源:OSC开源社区
本次复现使用的数据集是CelebA人脸数据集,这是一个大规模的人脸属性数据集,是由香港中文大学汤晓鸥教授实验室公布的大型人脸识别数据集,拥有超过20万张名人图像,已下载放置在此项目的数据集中,人脸属性有40多种。
本文项目代码github地址:
https://github.com/Eric-Hjx/PaddlePaddle_Image_Completion
模型摘要

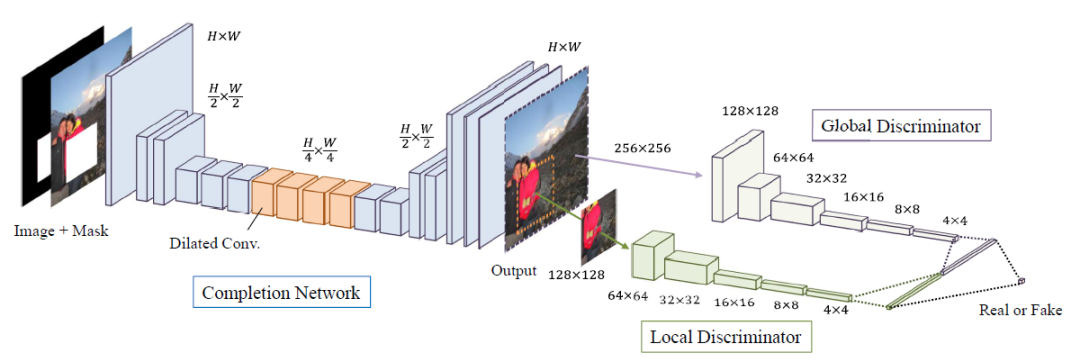
网络介绍:
-
补全网络:补全网络是完全卷积的,目的是用来修复图像。 -
全局鉴别器:以完整的图像作为输入,识别场景的全局一致性。 -
局部鉴别器:只关注完成区域周围的一个小区域,以判断更详细的外观质量。
1. 补全网络结构
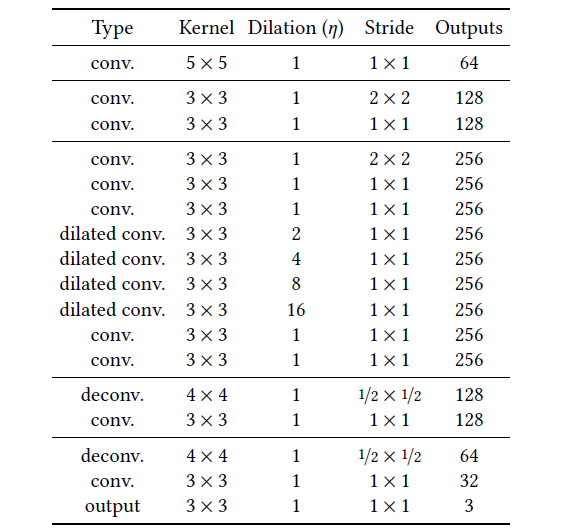
# 搭建补全网络
def generator(x):
# conv1
conv1 = fluid.layers.conv2d(input=x,num_filters=
64,filter_size=
5,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv1',data_format=
'NHWC')
conv1 = fluid.layers.batch_norm(conv1, momentum=
0.99, epsilon=
0.001)
conv1 = fluid.layers.relu(conv1, name=
None)
# conv2
conv2 = fluid.layers.conv2d(input=conv1,num_filters=
128,filter_size=
3,dilation=
1,stride=
2,padding=
'SAME',name=
'generator_conv2',data_format=
'NHWC')
conv2 = fluid.layers.batch_norm(conv2, momentum=
0.99, epsilon=
0.001)
conv2 = fluid.layers.relu(conv2, name=
None)
# conv3
conv3 = fluid.layers.conv2d(input=conv2,num_filters=
128,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv3',data_format=
'NHWC')
conv3 = fluid.layers.batch_norm(conv3, momentum=
0.99, epsilon=
0.001)
conv3 = fluid.layers.relu(conv3, name=
None)
# conv4
conv4 = fluid.layers.conv2d(input=conv3,num_filters=
256,filter_size=
3,dilation=
1,stride=
2,padding=
'SAME',name=
'generator_conv4',data_format=
'NHWC')
conv4 = fluid.layers.batch_norm(conv4, momentum=
0.99, epsilon=
0.001)
conv4 = fluid.layers.relu(conv4, name=
None)
# conv5
conv5 = fluid.layers.conv2d(input=conv4,num_filters=
256,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv5',data_format=
'NHWC')
conv5 = fluid.layers.batch_norm(conv5, momentum=
0.99, epsilon=
0.001)
conv5 = fluid.layers.relu(conv5, name=
None)
# conv6
conv6 = fluid.layers.conv2d(input=conv5,num_filters=
256,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv6',data_format=
'NHWC')
conv6 = fluid.layers.batch_norm(conv6, momentum=
0.99, epsilon=
0.001)
conv6 = fluid.layers.relu(conv6, name=
None)
# 空洞卷积
# dilated1
dilated1 = fluid.layers.conv2d(input=conv6,num_filters=
256,filter_size=
3,dilation=
2,padding=
'SAME',name=
'generator_dilated1',data_format=
'NHWC')
dilated1 = fluid.layers.batch_norm(dilated1, momentum=
0.99, epsilon=
0.001)
dilated1 = fluid.layers.relu(dilated1, name=
None)
# dilated2
dilated2 = fluid.layers.conv2d(input=dilated1,num_filters=
256,filter_size=
3,dilation=
4,padding=
'SAME',name=
'generator_dilated2',data_format=
'NHWC')
#stride=1
dilated2 = fluid.layers.batch_norm(dilated2, momentum=
0.99, epsilon=
0.001)
dilated2 = fluid.layers.relu(dilated2, name=
None)
# dilated3
dilated3 = fluid.layers.conv2d(input=dilated2,num_filters=
256,filter_size=
3,dilation=
8,padding=
'SAME',name=
'generator_dilated3',data_format=
'NHWC')
dilated3 = fluid.layers.batch_norm(dilated3, momentum=
0.99, epsilon=
0.001)
dilated3 = fluid.layers.relu(dilated3, name=
None)
# dilated4
dilated4 = fluid.layers.conv2d(input=dilated3,num_filters=
256,filter_size=
3,dilation=
16,padding=
'SAME',name=
'generator_dilated4',data_format=
'NHWC')
dilated4 = fluid.layers.batch_norm(dilated4, momentum=
0.99, epsilon=
0.001)
dilated4 = fluid.layers.relu(dilated4, name=
None)
# conv7
conv7 = fluid.layers.conv2d(input=dilated4,num_filters=
256,filter_size=
3,dilation=
1,name=
'generator_conv7',data_format=
'NHWC')
conv7 = fluid.layers.batch_norm(conv7, momentum=
0.99, epsilon=
0.001)
conv7 = fluid.layers.relu(conv7, name=
None)
# conv8
conv8 = fluid.layers.conv2d(input=conv7,num_filters=
256,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv8',data_format=
'NHWC')
conv8 = fluid.layers.batch_norm(conv8, momentum=
0.99, epsilon=
0.001)
conv8 = fluid.layers.relu(conv8, name=
None)
# deconv1
deconv1 = fluid.layers.conv2d_transpose(input=conv8, num_filters=
128, output_size=[
64,
64],stride =
2,name=
'generator_deconv1',data_format=
'NHWC')
deconv1 = fluid.layers.batch_norm(deconv1, momentum=
0.99, epsilon=
0.001)
deconv1 = fluid.layers.relu(deconv1, name=
None)
# conv9
conv9 = fluid.layers.conv2d(input=deconv1,num_filters=
128,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv9',data_format=
'NHWC')
conv9 = fluid.layers.batch_norm(conv9, momentum=
0.99, epsilon=
0.001)
conv9 = fluid.layers.relu(conv9, name=
None)
# deconv2
deconv2 = fluid.layers.conv2d_transpose(input=conv9, num_filters=
64, output_size=[
128,
128],stride =
2,name=
'generator_deconv2',data_format=
'NHWC')
deconv2 = fluid.layers.batch_norm(deconv2, momentum=
0.99, epsilon=
0.001)
deconv2 = fluid.layers.relu(deconv2, name=
None)
# conv10
conv10 = fluid.layers.conv2d(input=deconv2,num_filters=
32,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv10',data_format=
'NHWC')
conv10 = fluid.layers.batch_norm(conv10, momentum=
0.99, epsilon=
0.001)
conv10 = fluid.layers.relu(conv10, name=
None)
# conv11
x = fluid.layers.conv2d(input=conv10,num_filters=
3,filter_size=
3,dilation=
1,stride=
1,padding=
'SAME',name=
'generator_conv11',data_format=
'NHWC')
x = fluid.layers.tanh(x)
return x
2. 内容鉴别器
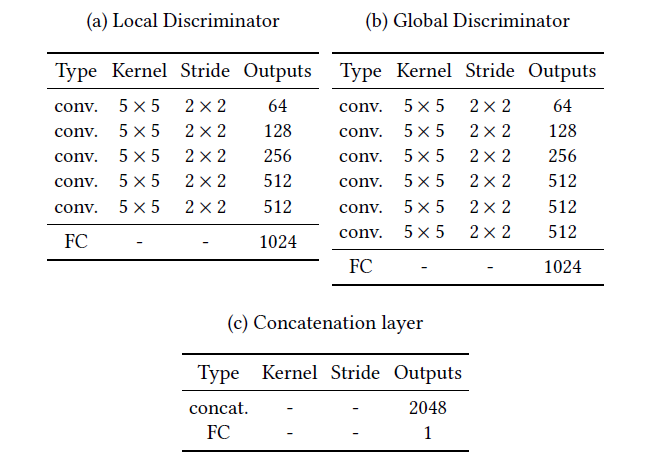
# 搭建内容鉴别器
def discriminator(global_x, local_x):
def global_discriminator(x):
# conv1
conv1 = fluid.layers.conv2d(input=x,num_filters=
64,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv1',data_format=
'NHWC')
conv1 = fluid.layers.batch_norm(conv1, momentum=
0.99, epsilon=
0.001)
conv1 = fluid.layers.relu(conv1, name=
None)
# conv2
conv2 = fluid.layers.conv2d(input=conv1,num_filters=
128,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv2',data_format=
'NHWC')
conv2 = fluid.layers.batch_norm(conv2, momentum=
0.99, epsilon=
0.001)
conv2 = fluid.layers.relu(conv2, name=
None)
# conv3
conv3 = fluid.layers.conv2d(input=conv2,num_filters=
256,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv3',data_format=
'NHWC')
conv3 = fluid.layers.batch_norm(conv3, momentum=
0.99, epsilon=
0.001)
conv3 = fluid.layers.relu(conv3, name=
None)
# conv4
conv4 = fluid.layers.conv2d(input=conv3,num_filters=
512,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv4',data_format=
'NHWC')
conv4 = fluid.layers.batch_norm(conv4, momentum=
0.99, epsilon=
0.001)
conv4 = fluid.layers.relu(conv4, name=
None)
# conv5
conv5 = fluid.layers.conv2d(input=conv4,num_filters=
512,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv5',data_format=
'NHWC')
conv5 = fluid.layers.batch_norm(conv5, momentum=
0.99, epsilon=
0.001)
conv5 = fluid.layers.relu(conv5, name=
None)
# conv6
conv6 = fluid.layers.conv2d(input=conv5,num_filters=
512,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_global_conv6',data_format=
'NHWC')
conv6 = fluid.layers.batch_norm(conv6, momentum=
0.99, epsilon=
0.001)
conv6 = fluid.layers.relu(conv6, name=
None)
# fc
x = fluid.layers.fc(input=conv6, size=
1024,name=
'discriminator_global_fc1')
return x
def local_discriminator(x):
# conv1
conv1 = fluid.layers.conv2d(input=x,num_filters=
64,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_lobal_conv1',data_format=
'NHWC')
conv1 = fluid.layers.batch_norm(conv1, momentum=
0.99, epsilon=
0.001)
conv1 = fluid.layers.relu(conv1, name=
None)
# conv2
conv2 = fluid.layers.conv2d(input=conv1,num_filters=
128,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_lobal_conv2',data_format=
'NHWC')
conv2 = fluid.layers.batch_norm(conv2, momentum=
0.99, epsilon=
0.001)
conv2 = fluid.layers.relu(conv2, name=
None)
# conv3
conv3 = fluid.layers.conv2d(input=conv2,num_filters=
256,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_lobal_conv3',data_format=
'NHWC')
conv3 = fluid.layers.batch_norm(conv3, momentum=
0.99, epsilon=
0.001)
conv3 = fluid.layers.relu(conv3, name=
None)
# conv4
conv4 = fluid.layers.conv2d(input=conv3,num_filters=
512,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_lobal_conv4',data_format=
'NHWC')
conv4 = fluid.layers.batch_norm(conv4, momentum=
0.99, epsilon=
0.001)
conv4 = fluid.layers.relu(conv4, name=
None)
# conv5
conv5 = fluid.layers.conv2d(input=conv4,num_filters=
512,filter_size=
5,dilation=
1,stride=
2,padding=
'SAME',name=
'discriminator_lobal_conv5',data_format=
'NHWC')
conv5 = fluid.layers.batch_norm(conv5, momentum=
0.99, epsilon=
0.001)
conv5 = fluid.layers.relu(conv5, name=
None)
# fc
x = fluid.layers.fc(input=conv5, size=
1024,name=
'discriminator_lobal_fc1')
return x
global_output = global_discriminator(global_x)
local_output = local_discriminator(local_x)
print(
'global_output',global_output.shape)
print(
'local_output',local_output.shape)
output = fluid.layers.concat([global_output, local_output], axis=
1)
output = fluid.layers.fc(output, size=
1,name=
'discriminator_concatenation_fc1')
return output
3. 损失函数
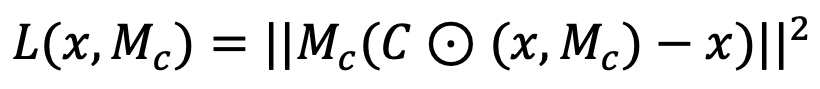
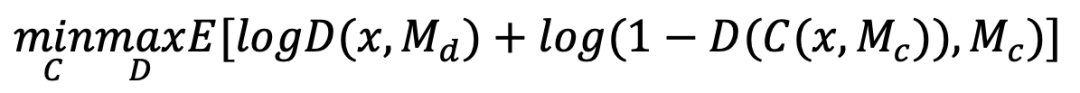
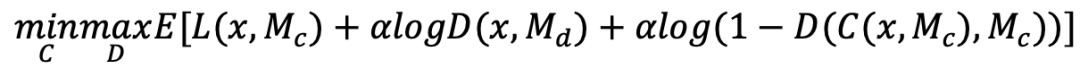
原文作者使用4个K80 GPU,使用的输入图像大小是256*256,训练了2个月才训练完成。
# 生成器优先迭代次数
NUM
_TRAIN_TIMES
_OF_DG = 100
# 总迭代轮次
epoch = 200
step
_num = int(len(x_train) / BATCH_SIZE)
np.random.shuffle(x_train)
for pass_id in range(epoch):
# 训练生成器
if pass
_id <= NUM_TRAIN
_TIMES_OF_DG:
g
_loss_value = 0
for i in tqdm.tqdm(range(step_num)):
x
_batch = x_train[i
* BATCH_SIZE:(i + 1) * BATCH_SIZE]
points
_batch, mask_batch = get_points()
# print(x_batch.shape)
# print(mask_batch.shape)
dg
_loss_n = exe.run(dg_program,
feed={'x': x_batch,
'mask':mask_batch,},
fetch
_list=[dg_loss])[0]
g
_loss_value += dg
_loss_n
print('Pass
_id:{}, Completion loss: {}'.format(pass_id, g
_loss_value))
np.random.shuffle(x_test)
x
_batch = x_test[:BATCH_SIZE]
completion
_n = exe.run(dg_program,
feed={'x': x_batch,
'mask': mask_batch,},
fetch_list=[
completion])[
0][
0]
# 修复图片
sample = np.array((completion_n + 1) * 127.5, dtype=np.uint8)
# 原图
x
_im = np.array((x_batch[0] + 1) * 127.5, dtype=np.uint8)
# 挖空洞输入图
input
_im_data = x
_im * (1 - mask_batch[0])
input
_im = np.array(input_im
_data + np.ones_like(x
_im) * mask_batch[0] * 255, dtype=np.uint8)
output
_im = np.concatenate((x_im,input_im,sample),axis=1)
#print(output_im.shape)
cv2.imwrite('./output/pass
_id:{}.jpg'.format(pass_id), cv2.cvtColor(output
_im, cv2.COLOR_RGB2BGR))
# 保存模型
save
_pretrain_model_path = 'models/'
# 创建保持模型文件目录
#os.makedirs(save
_pretrain_model_path)
fluid.io.save
_params(executor=exe, dirname=save_pretrain
_model_path, main
_program=dg_program)
# 生成器判断器一起训练
else:
g
_loss_value = 0
d
_loss_value = 0
for i in tqdm.tqdm(range(step_num)):
x
_batch = x_train[i
* BATCH_SIZE:(i + 1) * BATCH_SIZE]
points
_batch, mask_batch = get_points()
dg
_loss_n = exe.run(dg_program,
feed={'x': x_batch,
'mask':mask_batch,},
fetch
_list=[dg_loss])[0]
g
_loss_value += dg
_loss_n
completion
_n = exe.run(dg_program,
feed={'x': x_batch,
'mask': mask_batch,},
fetch_list=[completion])[0]
local
_x_batch = []
local
_completion_batch = []
for i in range(BATCH_SIZE):
x1, y1, x2, y2 = points_batch[i]
local
_x_batch.append(x_batch[
i][
y1:y2, x1:x2, :])
local
_completion_batch.append(completion_n[
i][
y1:y2, x1:x2, :])
local
_x_batch = np.array(local
_x_batch)
local
_completion_batch = np.array(local
_completion_batch)
d
_loss_n = exe.run(d_program,
feed={'x': x
_batch, 'mask': mask_batch, 'local
_x': local_x
_batch, 'global_completion': completion
_n, 'local_completion': local
_completion_batch},
fetch
_list=[d_loss])[0]
d
_loss_value += d
_loss_n
print('Pass
_id:{}, Completion loss: {}'.format(pass_id, g
_loss_value))
print('Pass
_id:{}, Discriminator loss: {}'.format(pass_id, d
_loss_value))
np.random.shuffle(x_test)
x
_batch = x_test[:BATCH_SIZE]
completion
_n = exe.run(dg_program,
feed={'x': x_batch,
'mask': mask_batch,},
fetch_list=[
completion])[
0][
0]
# 修复图片
sample = np.array((completion_n + 1) * 127.5, dtype=np.uint8)
# 原图
x
_im = np.array((x_batch[0] + 1) * 127.5, dtype=np.uint8)
# 挖空洞输入图
input
_im_data = x
_im * (1 - mask_batch[0])
input
_im = np.array(input_im
_data + np.ones_like(x
_im) * mask_batch[0] * 255, dtype=np.uint8)
output
_im = np.concatenate((x_im,input_im,sample),axis=1)
#print(output_im.shape)
cv2.imwrite('./output/pass
_id:{}.jpg'.format(pass_id), cv2.cvtColor(output
_im, cv2.COLOR_RGB2BGR))
# 保存模型
save
_pretrain_model_path = 'models/'
# 创建保持模型文件目录
#os.makedirs(save
_pretrain_model_path)
fluid.io.save
_params(executor=exe, dirname=save_pretrain
_model_path, main
_program = dg_program)

整个训练过程,花了9小时左右,共训练了100次补全网络+45次补全网络和鉴别网络。





登录查看更多
相关内容
Arxiv
3+阅读 · 2018年9月17日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年9月17日