Apache Spark实现可扩展日志分析,挖掘系统最大潜力

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
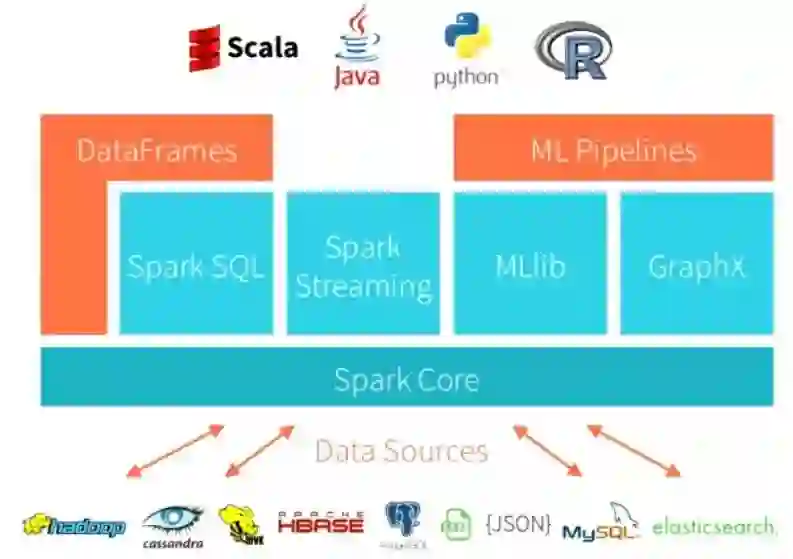
来源:Doug Henschen
在大数据、更好的分布式计算、大数据处理和 Spark 等开源分析框架的支持下,我们每天可以对潜在的数百万乃至数十亿条日志消息执行可扩展的日志分析。本教程面向案例研究,目的是采用一种实际操作的方法,展示如何利用 Spark 在半结构化日志数据上执行大规模日志分析。如果你对使用 Spark 的可扩展 SQL 感兴趣,请查阅 Spark 上的大规模 SQL(https://towardsdatascience.com/sql-at-scale-with-apache-spark-sql-and-dataframes-concepts-architecture-and-examples-c567853a702f)。
本文将主要探讨以下几个主题。
主要目标——NASA 日志分析
设置依赖项
加载和查看 NASA 日志
数据清理
Web 日志数据分析
尽管有很多优秀的开源框架和工具可以用于日志分析,包括 ElasticSearch,但本教程的目的是展示如何利用 Spark 对日志进行大规模分析。在现实世界中,你可以在分析日志数据时自由选择你的工具箱。让我们开始吧!
正如我们前面提到的,Apache Spark 是一个优秀的、理想的开源框架,用于结构化和非结构化数据清理、分析和建模——大规模的!在本教程中,我们的主要目标是关注业界最流行的案例研究之一——日志分析。通常,服务器日志是企业中非常常见的数据源,是常常包含可操作见解和信息的金矿。企业中的日志数据有许多来源,比如 Web、客户端和计算服务器、应用程序、用户生成的内容、平面文件。它们可以用于监视服务器、改进业务和客户智能、构建推荐系统、欺诈检测等等。

Spark 让你能以很低的成本将日志转储并存储在磁盘上的文件中,同时提供丰富的 API 来执行大规模的数据分析。这个实践案例研究将向你展示如何在 NASA 的实际生产日志上使用 Apache Spark,并学习数据清理和探索性数据分析中基本但强大的技术。在本案例研究中,我们将分析来自佛罗里达州 NASA 肯尼迪航天中心 Web 服务器的日志数据集。完整的数据集可以在这里(http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html)免费下载。
这两个数据集包含了佛罗里达州 NASA 肯尼迪航天中心 WWW 服务器上两个月内的所有 HTTP 请求。你可以到网站(http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html)下载以下文件(或直接点击以下链接)。
7 月 1 日到 7 月 31 日,ASCII 格式,gzip 压缩 20.7MB,未压缩 205.2MB:ftp://ita.ee.lbl.gov/traces/NASA_access_log_Jul95.gz
8 月 4 日到 8 月 31 日,ASCII 格式,gzip 压缩 21.8MB,未压缩 167.8MB:ftp://ita.ee.lbl.gov/traces/NASA_access_log_Aug95.gz
请确保这两个文件与包含教程的笔记本在同一个目录中,该教程可以从我的 GitHub(https://github.com/dipanjanS/data_science_for_all/tree/master/tds_scalable_log_analytics)上找到。
第一步是确保你能够访问 Spark 会话和集群。为此,你可以使用自己的本地设置或基于云的设置。通常,现在大多数云平台都会提供一个 Spark 集群,你还可以选择免费的 Databricks 社区版(https://community.cloud.databricks.com/)。本教程假设你已经安装了 Spark,因此我们不会花费额外的时间从头配置或设置 Spark。
通常,在启动你的 jupyter 笔记本服务器时,预配置的 Spark 设置已经预先加载了必要的环境变量或依赖项。在我的例子中,我可以在笔记本中使用以下命令来检查它们。
spark

这说明我的集群目前正在运行 Spark 2.4.0。我们还可以使用以下代码检查 sqlContext 是否存在。
sqlContext
#Output:
<pyspark.sql.context.SQLContext at 0x7fb1577b6400>
现在,如果你没有预先配置这些变量并得到一个错误,你可以加载它们并使用以下代码配置它们。除此之外,我们还加载了一些用于处理数据流和正则表达式的其他库。
# configure spark variables
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.sql.session import SparkSession
sc = SparkContext()
sqlContext = SQLContext(sc)
spark = SparkSession(sc)
# load up other dependencies
import re
import pandas as pd

来源:xkcd
正则表达式非常有效、非常强大,但有时也会让人不知所措或感到困惑。不过不用担心,通过更多的练习,你可以真正充分地利用它的潜力。下面的示例展示了在 Python 中使用正则表达式的一种方法。
m = re.finditer(r'.*?(spark).*?', "I'm searching for a spark in PySpark", re.I)
for match in m:
print(match, match.start(), match.end())
<_sre.SRE_Match object; span=(0, 25), match="I'm searching for a spark"> 0 25
<_sre.SRE_Match object; span=(25, 36), match=' in PySpark'> 25 36
让我们进入下一部分的分析。
假设我们的数据存储在下面提到的路径中(以平面文件的形式),让我们将其加载到一个 DataFrame 中。我们将分步骤来做。下面的代码获取磁盘中的日志数据文件名。
import glob
raw_data_files = glob.glob('*.gz')
raw_data_files
['NASA_access_log_Jul95.gz', 'NASA_access_log_Aug95.gz']
现在,我们将使用 sqlContext.read.text() 或 spark.read.text() 来读取文本文件。这将生成一个 DataFrame,其中只有一个名为 value 的字符串列。
base_df = spark.read.text(raw_data_files)
base_df.printSchema()
root |-- value: string (nullable = true)
这使我们能够看到日志数据的模式,它看起来很像我们将很快要检查的文本数据。你可以使用以下代码查看保存日志数据的数据结构类型。
type(base_df)
#Output: pyspark.sql.dataframe.DataFrame
我们将在整个教程中使用 Spark DataFrame。但是,如果需要,还可以将数据 DataFrame 转换为 RDD,即 Spark 的原始数据结构(弹性分布式数据集)。
base_df_rdd = base_df.rdd
type(base_df_rdd)
#Output pyspark.rdd.RDD
现在让我们看一下 DataFrame 中实际的日志数据。
base_df.show(10, truncate=False)
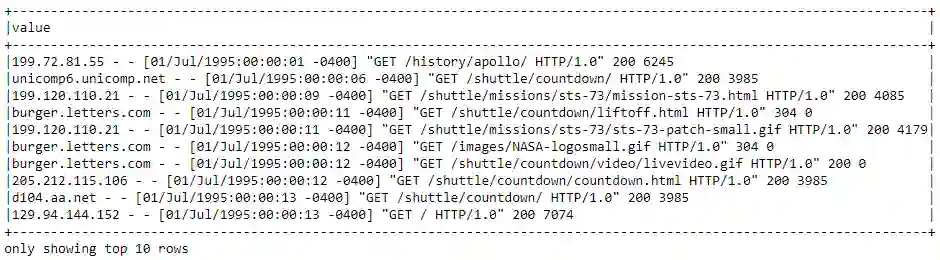
这看起来绝对像标准的服务器日志数据,它是半结构化的,在使用它们之前,我们肯定需要做一些数据处理和清理。请记住,从 RDD 访问数据略有不同,如下所示。
base_df_rdd.take(10)
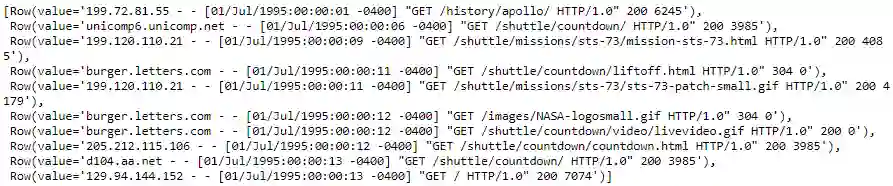
现在我们已经加载并查看了日志数据,让我们对其进行处理和清理。
在本节中,我们将尝试清理和解析日志数据集,以便真正从每个日志消息中提取包含有意义信息的结构化属性。
如果你熟悉 Web 服务器日志,你将认识到上面显示的数据是通用的日志格式(https://www.w3.org/Daemon/User/Config/Logging.html#common-logfile-format)。
字段包括:remotehost rfc931 authuser [date] "request" status bytes
| 字段 | 说明 |
|---|---|
| remotehost | 远程主机名(或 IP 地址,如果 DNS 主机名获取不到或 DNSLookup 未开启) |
| rfc931 | 用户的远程登录名(如果有的话)。 |
| authuser | 通过 HTTP 服务器验证的远程用户的用户名。 |
| [date] | 请求的日期和时间。 |
| "request" | 请求,与来自浏览器或客户端的请求完全相同。 |
| status | 服务器返回客户端的 HTTP 状态码。 |
| bytes | 传输到客户端的字节数(Content-Length)。 |
我们需要使用一些特定的技术来解析、匹配和提取日志数据中的这些属性。
接下来,我们必须将半结构化的日志数据解析为单独的列。我们将使用专门的内置函数 regexp_extract() 进行解析。此函数将针对具有一个或多个 捕获组 的正则表达式匹配列,并允许提取其中一个匹配的组。我们将对希望提取的每个字段使用一个正则表达式。
到目前为止,你一定已经听说或使用了大量正则表达式。如果你发现正则表达式令人困惑,并且希望了解更多关于正则表达式的信息,我们建议你访问 RegexOne 网站(http://regexone.com/)。你可能还会发现,Goyvaerts 和 Levithan 编写的 《正则表达式手册》 (http://shop.oreilly.com/product/0636920023630.do)是非常有用的参考资料。
让我们看下我们使用的数据集中的日志总数。
print((base_df.count(), len(base_df.columns)))
#Output (3461613, 1)
看起来我们总共有大约 346 万条日志消息。一个不小的数字!让我们提取并查看一些日志消息。
sample_logs = [item['value'] for item in base_df.take(15)]
sample_logs
让我们尝试编写一些正则表达式来从日志中提取主机名。
host_pattern = r'(^\S+\.[\S+\.]+\S+)\s'
hosts = [re.search(host_pattern, item).group(1)
if re.search(host_pattern, item)
else 'no match'
for item in sample_logs]
hosts
['199.72.81.55','unicomp6.unicomp.net','199.120.110.21','burger.letters.com',...,...,'unicomp6.unicomp.net','d104.aa.net','d104.aa.net']
现在让我们尝试使用正则表达式从日志中提取时间戳字段。
ts_pattern = r'\[(\d{2}/\w{3}/\d{4}:\d{2}:\d{2}:\d{2} -\d{4})]'
timestamps = [re.search(ts_pattern, item).group(1) for item in sample_logs]
timestamps
['01/Jul/1995:00:00:01 -0400','01/Jul/1995:00:00:06 -0400','01/Jul/1995:00:00:09 -0400',...,...,' 01/Jul/1995:00:00:14 -0400','01/Jul/1995:00:00:15 -0400','01/Jul/1995:00:00:15 -0400']
现在让我们尝试使用正则表达式从日志中提取 HTTP 请求方法、URI 和协议模式字段。
method_uri_protocol_pattern = r'\"(\S+)\s(\S+)\s*(\S*)\"'
method_uri_protocol = [re.search(method_uri_protocol_pattern, item).groups()
if re.search(method_uri_protocol_pattern, item)
else 'no match'
for item in sample_logs]
method_uri_protocol
[('GET', '/history/apollo/', 'HTTP/1.0'),('GET','/shuttle/countdown/','HTTP/1.0'),...,...,('GET', '/shuttle/countdown/count.gif', 'HTTP/1.0'),('GET', '/images/NASA-logosmall.gif', 'HTTP/1.0')]
现在让我们尝试使用正则表达式从日志中提取 HTTP 状态码。
status_pattern = r'\s(\d{3})\s'
status = [re.search(status_pattern, item).group(1) for item in sample_logs]
print(status)
['200', '200', '200', '304', ..., '200', '200']
现在让我们尝试使用正则表达式从日志中提取 HTTP 响应内容大小。
content_size_pattern = r'\s(\d+)$'
content_size = [re.search(content_size_pattern, item).group(1) for item in sample_logs]
print(content_size)
['6245', '3985', '4085', '0', ..., '1204', '40310', '786']
现在,让我们尝试利用前面构建的所有正则表达式模式,并使用 regexp_extract(…) 方法构建 DataFrame,所有日志属性都整齐地提取到各自的列中。
from pyspark.sql.functions import regexp_extract
logs_df = base_df.select(regexp_extract('value', host_pattern, 1).alias('host'),
regexp_extract('value', ts_pattern, 1).alias('timestamp'),
regexp_extract('value', method_uri_protocol_pattern, 1).alias('method'),
regexp_extract('value', method_uri_protocol_pattern, 2).alias('endpoint'),
regexp_extract('value', method_uri_protocol_pattern, 3).alias('protocol'),
regexp_extract('value', status_pattern, 1).cast('integer').alias('status'),
regexp_extract('value', content_size_pattern, 1).cast('integer').alias('content_size'))
logs_df.show(10, truncate=True)
print((logs_df.count(), len(logs_df.columns)))
缺失值和空值是数据分析和机器学习的祸根。让我们看看我们的数据解析和提取逻辑是如何工作的。首先,让我们验证原始数据框中有没有空行。
(base_df
.filter(base_df['value']
.isNull())
.count())
0
没问题!现在,如果我们的数据解析和提取工作正常,我们就不应该有任何可能存在空值的行。让我们来试试吧!
bad_rows_df = logs_df.filter(logs_df['host'].isNull()|
logs_df['timestamp'].isNull() |
logs_df['method'].isNull() |
logs_df['endpoint'].isNull() |
logs_df['status'].isNull() |
logs_df['content_size'].isNull()|
logs_df['protocol'].isNull())
bad_rows_df.count()
33905
哎哟!看起来我们的数据中有 超过 33K 的缺失值!我们能搞定吗?
请记住,这不是一个常规的 pandas DataFrame,你无法直接查询并获得哪些列为空。我们所谓的 大数据集 驻留在磁盘上,它可能存在于 Spark 集群中的多个节点上。那么我们如何找出哪些列有可能为空呢?
我们通常可以使用以下技术找出哪些列具有空值。(注意:这种方法是从 StackOverflow 上的一个 绝妙的回答(http://stackoverflow.com/a/33901312)改造而来的。)
from pyspark.sql.functions import col
from pyspark.sql.functions import sum as spark_sum
def count_null(col_name):
return spark_sum(col(col_name).isNull().cast('integer')).alias(col_name)
# Build up a list of column expressions, one per column.
exprs = [count_null(col_name) for col_name in logs_df.columns]
# Run the aggregation. The *exprs converts the list of expressions into
# variable function arguments.
logs_df.agg(*exprs).show()

看起来 status 列中有一个缺失值而其它的都在 content_size 列中。让我们看看能不能找出问题所在!
状态列解析使用的原始正则表达式是:
regexp_extract('value', r'\s(\d{3})\s', 1).cast('integer')
.alias( 'status')
是否有更多的数字使正则表达式出错?还是数据点本身的问题?让我们试着找出答案。
注意:在下面的表达式中,~ 表示“非”。
null_status_df = base_df.filter(~base_df['value'].rlike(r'\s(\d{3})\s'))
null_status_df.count()
1
让我们看看这条糟糕的记录是什么样子?
null_status_df.show(truncate=False)
看起来像一条有很多信息丢失的记录!让我们通过日志数据解析管道来传递它。
bad_status_df = null_status_df.select(regexp_extract('value', host_pattern, 1).alias('host'),
regexp_extract('value', ts_pattern, 1).alias('timestamp'),
regexp_extract('value', method_uri_protocol_pattern, 1).alias('method'),
regexp_extract('value', method_uri_protocol_pattern, 2).alias('endpoint'),
regexp_extract('value', method_uri_protocol_pattern, 3).alias('protocol'),
regexp_extract('value', status_pattern, 1).cast('integer').alias('status'),
regexp_extract('value', content_size_pattern, 1).cast('integer').alias('content_size'))
bad_status_df.show(truncate=False
看起来这条记录本身是一个不完整的记录,没有有用的信息,最好的选择是删除这条记录,如下所示!
logs_df = logs_df[logs_df['status'].isNotNull()]
exprs = [count_null(col_name) for col_name in logs_df.columns]
logs_df.agg(*exprs).show()
根据之前的正则表达式,content_size 列的原始解析正则表达式为:
regexp_extract('value', r'\s(\d+)$', 1).cast('integer')
.alias('content_size')
原始数据集中是否有数据丢失?让我们试着找出答案吧!我们首先尝试找出基本 DataFrame 中可能缺少内容大小的记录。
null_content_size_df = base_df.filter(~base_df['value'].rlike(r'\s\d+$'))
null_content_size_df.count()
33905
这个数值似乎与处理后的 DataFrame 中缺失的内容大小的数量相匹配。让我们来看看我们的数据框中缺少内容大小的前十条记录。
null_content_size_df.take(10)
很明显,糟糕的原始数据记录对应错误响应,其中没有发回任何内容,服务器为 content_size 字段发出了一个“-”。
因为我们不想从我们的分析中丢弃这些行,所以我们把它们代入或填充为 0。
最简单的解决方案是像前面讨论的那样,用 0 替换 logs_df 中的 null 值。Spark DataFrame API 提供了一组专门为处理 null 值而设计的函数和字段,其中包括:
fillna():用指定的非空值填充空值。
na:它返回一个 DataFrameNaFunctions 对象,其中包含许多用于在空列上进行操作的函数。
有几种方法可以调用这个函数。最简单的方法就是用已知值替换所有空列。但是,为了安全起见,最好传递一个包含 (column_name, value) 映射的 Python 字典。这就是我们要做的。下面是文档中的一个示例:
>>> df4.na.fill({'age': 50, 'name': 'unknown'}).show()
+---+------+-------+
|age|height| name|
+---+------+-------+
| 10| 80| Alice|
| 5| null| Bob|
| 50| null| Tom|
| 50| null|unknown|
+---+------+-------+
现在我们使用这个函数,用 0 填充 content_size 字段中所有缺失的值!
logs_df = logs_df.na.fill({'content_size': 0})
exprs = [count_null(col_name) for col_name in logs_df.columns]
logs_df.agg(*exprs).show()

看,没有缺失值了!
现在我们有了一个干净的、已解析的 DataFrame,我们必须将 timestamp 字段解析为一个实际的时间戳。通用的日志格式时间有点不标准。用户定义函数(UDF)是解析它最直接的方法。
from pyspark.sql.functions import udf
month_map = {
'Jan': 1, 'Feb': 2, 'Mar':3, 'Apr':4, 'May':5, 'Jun':6, 'Jul':7,
'Aug':8, 'Sep': 9, 'Oct':10, 'Nov': 11, 'Dec': 12
}
def parse_clf_time(text):
""" Convert Common Log time format into a Python datetime object
Args:
text (str): date and time in Apache time format [dd/mmm/yyyy:hh:mm:ss (+/-)zzzz]
Returns:
a string suitable for passing to CAST('timestamp')
"""
# NOTE: We're ignoring the time zones here, might need to be handled depending on the problem you are solving
return "{0:04d}-{1:02d}-{2:02d} {3:02d}:{4:02d}:{5:02d}".format(
int(text[7:11]),
month_map[text[3:6]],
int(text[0:2]),
int(text[12:14]),
int(text[15:17]),
int(text[18:20])
)
现在,让我们使用这个函数来解析 DataFrame 中的 time 列。
udf_parse_time = udf(parse_clf_time)
logs_df = (logs_df.select('*', udf_parse_time(logs_df['timestamp'])
.cast('timestamp')
.alias('time'))
.drop('timestamp')
logs_df.show(10, truncate=True)

一切看起来都很好!让我们通过检查 DataFrame 的模式来验证这一点。
logs_df.printSchema()
root
|-- host: string (nullable = true)
|-- method: string (nullable = true)
|-- endpoint: string (nullable = true)
|-- protocol: string (nullable = true)
|-- status: integer (nullable = true)
|-- content_size: integer (nullable = false)
|-- time: timestamp (nullable = true)
现在,让我们缓存 logs_df,因为我们将在下一部分的数据分析部分中大量地使用它!
logs_df.cache()
现在我们有了一个 DataFrame,其中包含经过解析和清理的日志文件,我们可以执行一些有趣的探索性数据分析(EDA),尝试获得一些有趣的见解!
让我们计算一些关于 Web 服务器返回内容大小的统计信息。特别是,我们想知道内容大小的平均值、最小值和最大值。
我们可以通过在 logs_df 的 content_size 列上调用 .describe() 来计算统计数据。该函数的作用是返回给定列的计数、平均值、stddev、最小值和最大值。
content_size_summary_df = logs_df.describe(['content_size'])
content_size_summary_df.toPandas()
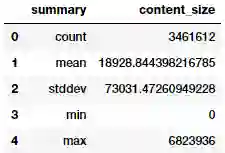
或者,我们可以使用 SQL 直接计算这些统计数据。你可以研究下 文档 中 pyspark.sql.functions 模块提供的许多有用的函数。
在应用 .agg() 函数之后,我们调用 toPandas() 来提取结果并将其转换为 panda DataFrame,该数据框在 Jupyter 笔记本上具有更好的格式。
from pyspark.sql import functions as F
(logs_df.agg(F.min(logs_df['content_size']).alias('min_content_size'),
F.max(logs_df['content_size']).alias('max_content_size'),
F.mean(logs_df['content_size']).alias('mean_content_size'),
F.stddev(logs_df['content_size']).alias('std_content_size'),
F.count(logs_df['content_size']).alias('count_content_size'))
.toPandas())

我们可以验证结果,并看到它们和预期相同。
接下来,让我们看看日志中出现的状态码值。我们想知道数据中出现了哪些状态码值以及出现了多少次。我们再次从 logs_df 开始,然后按 status 列分组,运用 .count() 聚合函数,并按 status 列排序。
status_freq_df = (logs_df
.groupBy('status')
.count()
.sort('status')
.cache())
print('Total distinct HTTP Status Codes:', status_freq_df.count())
Total distinct HTTP Status Codes: 8
看起来,我们总共有 8 个不同的 HTTP 状态码。让我们以频率表的形式看一下它们的出现情况。
status_freq_pd_df = (status_freq_df
.toPandas()
.sort_values(by=['count'],
ascending=False))
status_freq_pd_df
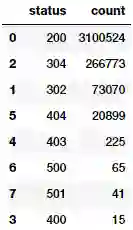
看起来,状态码 200 OK 是最常见的代码,这是一个很好的信号,说明大多数时候事情都运行正常。让我们将其可视化。
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
sns.catplot(x='status', y='count', data=status_freq_pd_df,
kind='bar', order=status_freq_pd_df['status']) 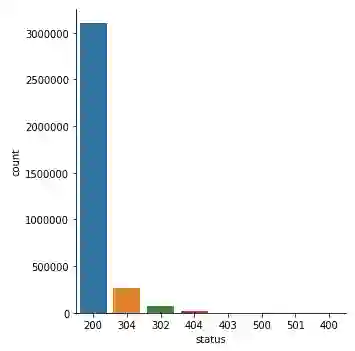
HTTP 状态码出现次数
不是太坏!但是由于数据存在巨大的差别,一些状态码几乎不可见。让我们做一个对数变换,看看情况是否有所改善。
log_freq_df = status_freq_df.withColumn('log(count)',
F.log(status_freq_df['count']))
log_freq_df.show()
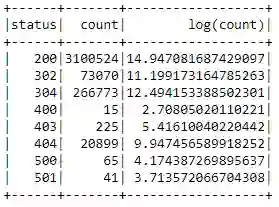
结果看起来很好,似乎已经处理了偏斜度,让我们通过可视化这些数据来验证一下。
log_freq_pd_df = (log_freq_df
.toPandas()
.sort_values(by=['log(count)'],
ascending=False))
sns.catplot(x='status', y='log(count)', data=log_freq_pd_df,
kind='bar', order=status_freq_pd_df['status'])
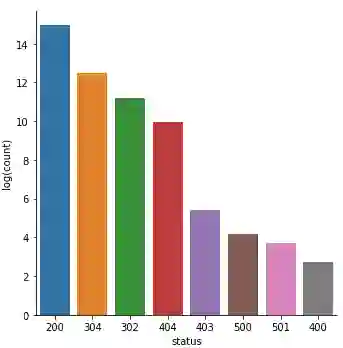
HTTP 状态码出现次数——对数变换
这看起来确实好多了,偏斜度不那么大了!
让我们看看频繁访问服务器的主机。我们将尝试获得每个主机的总访问数,然后根据这些数进行排序,并只显示访问频率排在前十位的主机。
host_sum_df =(logs_df
.groupBy('host')
.count()
.sort('count', ascending=False).limit(10))
host_sum_df.show(truncate=False)
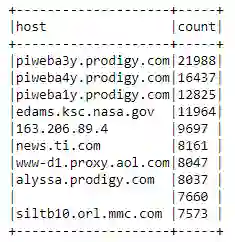
这看起来不错,但是让我们更仔细地检查下第 9 行中的空白记录。
host_sum_pd_df = host_sum_df.toPandas()
host_sum_pd_df.iloc[8]['host']
看起来,我们有一些访问最频繁的主机使用了空字符串作为主机名。这给我们上了宝贵的一课,不仅要检查 null,还要在数据清理时检查潜在的空字符串。
显示出现频率排名前20的端点
现在,让我们可视化日志中端点(URI)的访问次数。要执行这个任务,我们从 logs_df 开始,按 endpoint 列分组,按 count 聚合,并按降序排序,就像前面的问题一样。
paths_df = (logs_df
.groupBy('endpoint')
.count()
.sort('count', ascending=False).limit(20))
paths_pd_df = paths_df.toPandas()
paths_pd_df

毫不奇怪,GIF、主页和一些 CGI 脚本似乎是访问最多的资产。
返回代码不是 200 (HTTP 状态 OK)的次数排名前 10 的端点是什么?我们创建一个有序列表,其中包含端点和返回代码不是 200 的次数,并显示前十位。
not200_df = (logs_df
.filter(logs_df['status'] != 200))
error_endpoints_freq_df = (not200_df
.groupBy('endpoint')
.count()
.sort('count', ascending=False)
.limit(10)
)
error_endpoints_freq_df.show(truncate=False)
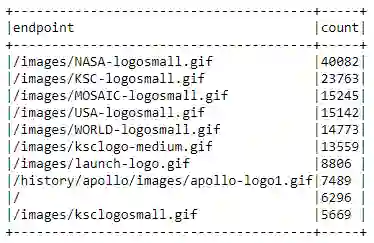
看起来 GIF(动画 / 静态图片)加载失败最多。你知道为什么吗?考虑到这些日志是 1995 年的,考虑到当时的互联网速度,我一点也不惊讶!
在这两个月里,访问 NASA 网站的不同主机的总数是多少?我们可以通过一些变换来确定。
unique_host_count = (logs_df
.select('host')
.distinct()
.count())
unique_host_count
137933
作为高级示例,让我们看看如何确定整个日志中每天中不同主机的数量。这个计算将为我们提供每天中不同主机的数量。
我们希望 DataFrame 中数据按照日期的升序排序,其中包括天和与那一天关联的不同主机的数量。
考虑一下你需要执行哪些步骤来计算每天发出请求的不同主机的数量。因为日志只包含一个月,所以可以忽略月份。你可能希望使用 pyspark.sql.functions 模块中的 dayofmonth 函数(函数模块我们已经导入为 F)。
host_day_df:一个包含两列的 DataFrame。

对于 logs_df 中的每一行,DataFrame 中都有一行。实际上,我们只是转换了 logs_df 的每一行。例如,对于 logs_df 中的这一行:
unicomp6.unicomp.net - - [01/Aug/1995:00:35:41 -0400] "GET /shuttle/missions/sts-73/news HTTP/1.0" 302 -
host_day_df 应该包含 unicomp6.unicomp.net 1。
host_day_distinct_df = (host_day_df
.dropDuplicates())
host_day_distinct_df.show(5, truncate=False)
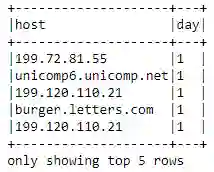
host_day_distinct_df:这个 DataFrame 具有与 host_day_df 相同的列,但是删除了重复的 (day, host) 行。
host_day_distinct_df = (host_day_df
.dropDuplicates())
host_day_distinct_df.show(5, truncate=False)
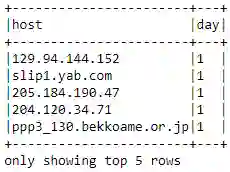
daily_unique_hosts_df:一个包含两列的 DataFrame。

def_mr = pd.get_option('max_rows')
pd.set_option('max_rows', 10)
daily_hosts_df = (host_day_distinct_df
.groupBy('day')
.count()
.sort("day"))
daily_hosts_df = daily_hosts_df.toPandas()
daily_hosts_df

这为我们提供了一个很好的 DataFrame,显示了每天不同主机的总数。让我们将其可视化!
c = sns.catplot(x='day', y='count',
data=daily_hosts_df,
kind='point', height=5,
aspect=1.5)
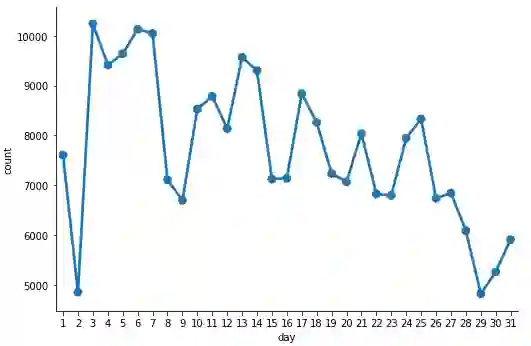
每天的不同主机数
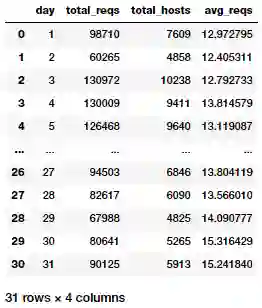
在前面的示例中,我们研究了一种方法,该方法可以逐日确定整个日志中不同主机的数量。现在,让我们试着根据我们的日志找出每个主机每天向 NASA 网站发出的平均请求数。我们想要一个 DataFrame,通过日期升序来排序,其中包括天和每个主机在这一天的平均请求数。
daily_hosts_df = (host_day_distinct_df
.groupBy('day')
.count()
.select(col("day"),
col("count").alias("total_hosts")))
total_daily_reqests_df = (logs_df
.select(F.dayofmonth("time")
.alias("day"))
.groupBy("day")
.count()
.select(col("day"),
col("count").alias("total_reqs")))
avg_daily_reqests_per_host_df = total_daily_reqests_df.join(daily_hosts_df, 'day')
avg_daily_reqests_per_host_df = (avg_daily_reqests_per_host_df
.withColumn('avg_reqs', col('total_reqs') / col('total_hosts'))
.sort("day"))
avg_daily_reqests_per_host_df = avg_daily_reqests_per_host_df.toPandas()
avg_daily_reqests_per_host_df
现在,我们可以可视化每台主机平均每天的请求数。
c = sns.catplot(x='day', y='avg_reqs',
data=avg_daily_reqests_per_host_df,
kind='point', height=5, aspect=1.5)
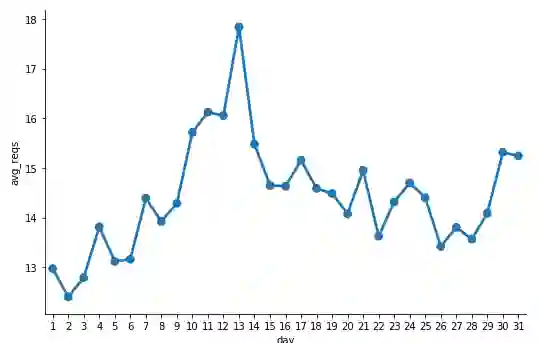
每台主机的平均日请求数
看来 13 号每台主机的请求数最大。
创建一个只包含 404 状态码(未找到)的日志记录 DataFrame。我们确保缓存 cache() 这个 not_found_df 数据框,因为我们将在下面的示例中使用它。你认为日志中有多少 404 记录?
not_found_df = logs_df.filter(logs_df["status"] == 404).cache()
print(('Total 404 responses: {}').format(not_found_df.count()))
Total 404 responses: 20899
使用只包含 404 响应代码的日志记录 DataFrame,我们现在将打印出产生最多 404 错误的前 20 个端点的列表。记住,这些端点应该是有序的。
endpoints_404_count_df = (not_found_df
.groupBy("endpoint")
.count()
.sort("count", ascending=False)
.limit(20))
endpoints_404_count_df.show(truncate=False)
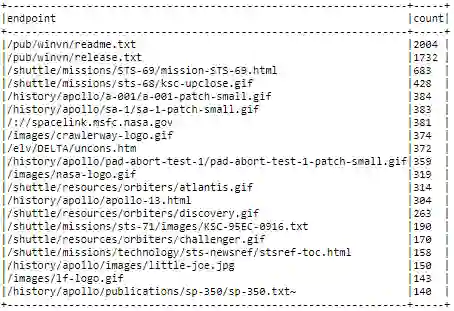
使用只包含 404 响应代码的日志记录 DataFrame,我们现在将打印出产生最多 404 错误的前 20 个主机的列表。记住,这些主机应该是按顺序排列的。
hosts_404_count_df = (not_found_df
.groupBy("host")
.count()
.sort("count", ascending=False)
.limit(20))
hosts_404_count_df.show(truncate=False)
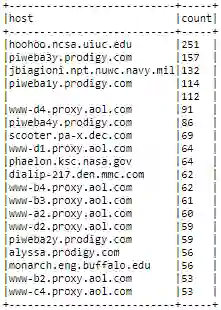
这让我们可以很容易了解,对于 NASA 的网页,哪台主机最终生成的 404 错误最多。
现在让我们临时(按时间)研究一下 404 记录。与显示每日不同主机数的示例类似,我们将按天划分 404 请求,并在 errors_by_date_sorted_df 中按天排序每日计数。
errors_by_date_sorted_df = (not_found_df
.groupBy(F.dayofmonth('time').alias('day'))
.count()
.sort("day"))
errors_by_date_sorted_pd_df = errors_by_date_sorted_df.toPandas()
errors_by_date_sorted_pd_df

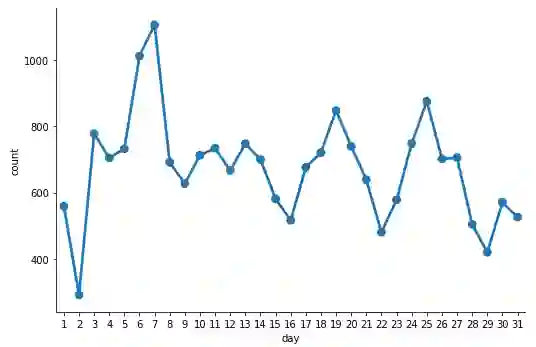
每天的 404 错误总数
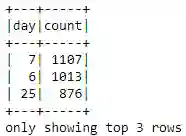
根据前面的图表,一个月中 404 错误最多的前三天是哪三天?为此,我们可以利用前面创建的 errors_by_date_sorted_df。
(errors_by_date_sorted_df
.sort("count", ascending=False)
.show(3))
使用我们之前缓存的 not_found_df 数据框,现在我们将按小时分组并按天排序,创建一个 DataFrame,其中包含一天中每个小时的 HTTP 请求的 404 响应总数(从 0 点到午夜)。然后,我们会从 DataFrame 构建可视化。
hourly_avg_errors_sorted_df = (not_found_df
.groupBy(F.hour('time')
.alias('hour'))
.count()
.sort('hour'))
hourly_avg_errors_sorted_pd_df = hourly_avg_errors_sorted_df.toPandas()
c = sns.catplot(x='hour', y='count',
data=hourly_avg_errors_sorted_pd_df,
kind='bar', height=5, aspect=1.5)
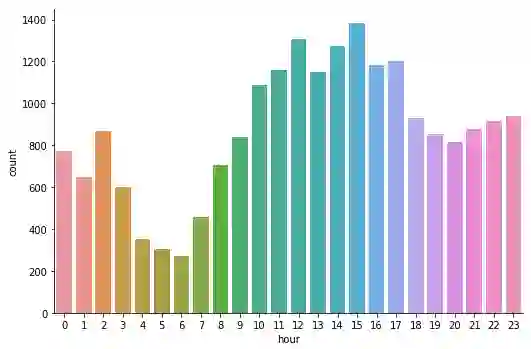
每小时的 404 错误总数
看起来,404 错误多发生在下午,早上最少。现在,我们可以将 panda 显示的最大行重置为默认值,因为我们之前已经将其更改为显示有限数量的行。
pd.set_option('max_rows', def_mr)
在一个非常常见但又非常重要的日志分析案例研究中,我们采用实操的方法探讨了大规模的数据清理、解析、分析和可视化。虽然我们在这里研究的数据从规模或数量的角度来看可能并不是传统意义上的“大数据”,但是这些技术和方法非常通用,可以扩展到更大的数据量。我希望这个案例研究能让你很好地了解像 Apache Spark 这样的开源框架,它们让你可以在很大的规模上使用结构化和半结构化数据!
本文附带的所有代码和分析都可以在我的 GitHub 存储库 (https://github.com/dipanjanS/data_science_for_all/tree/master/tds_scalable_log_analytics) 中找到。
这个 Jupyter 笔记本 (https://nbviewer.jupyter.org/github/dipanjanS/data_science_for_all/blob/master/tds_scalable_log_analytics/Scalable_Log_Analytics_Spark.ipynb) 中提供了详细的步骤。
原文链接:
https://towardsdatascience.com/scalable-log-analytics-with-apache-spark-a-comprehensive-case-study-2be3eb3be977

你也「在看」吗?👇



