机器学习标准教科书PRML的Python实现:最佳读书伴侣
| 全文共2585字,建议阅读时2分钟 |
选自:GitHub
参与:蒋思源
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
机器学习神书之一的 PRML(模式识别与机器学习)是所有机器学习读者或希望系统理解机器学习的读者所必须了解的书籍。这本书系统而全面地论述了模式识别与机器学习领域的基本知识和最新发展,而该 GitHub 项目希望实现这本书的所有算法与概念,是非常优秀的资源与项目。
GitHub地址:https://github.com//ctgk/PRML
PRML 这本机器学习和模式识别领域中经典的教科书不仅反映了这些年该领域的最新发展,同时还全面而系统地介绍了模式识别和机器学习领域内详细的概念与基础。这本书主要针对高级本科生或研究生,以及人工智能相关的研究人员和从业人员。如果读者以前没有模式识别或机器学习相关的概念或知识,我们可能需要熟悉一些多元微积分和基本的线性代数等数学基础。此外,我们本科学的概率论与数理统计也需要复习一些,但这本书包含了对基本概率论的介绍,所以也可以借由这些章节进行复习。

PRML 适用于机器学习、统计学、计算机科学、信号处理、计算机视觉、数据挖掘和生物信息学等课程。它也为广大的读者提供了丰富的支持,例如书籍官网提供了 400 多个详细的练习资源,且根据难度分级。以下提供了该书籍的中英文资源,但我们还是建议读者查阅原版的英文书籍。此外,我们在 GitHub 上也能找到非常多的学习资源,例如中文翻译项目、Matlab 实现项目或各种读书笔记等。本文主要介绍了一个新的 GitHub 项目,该项目希望能实现 PRML 这本书籍的各种算法与概念。
PRML 实现地址:https://github.com//ctgk/PRML
PRML 书籍资源:http://pan.baidu.com/s/1skRgcjF 密码:cquc
该 GitHub 项目主要是希望使用 Python 代码实现在 Bishop 书籍「Pattern Recognition and Machine Learning」中介绍的算法。其中代码可以分为两部分,即实现各章节具体算法的 Python 代码文件和有助于理解各章节具体内容的 Jupyter Notebook 文件。在本文中,机器之心将简要介绍描述各章节的 Notebook,而各个算法的具体实现就需要读者朋友自行深入了解该项目了。
该 GitHub 项目所需要的编程语言为 Python 3,其它科学计算库还需要 NumPy 和 SciPy。若我们需要阅读各章节的 Notebook 文件,就需要安装 Jupyter,若希望在 Notebook 上绘制结果曲线或其他图表,我们需要安装 Matplotlib。此外,若我们希望馈送数据进行训练,还需要安装 sklearn 包。
在各章节具体算法的 Python 代码中,其罗列了聚类方法、特征抽取、线性模型、核方法、马尔科夫模型、概率分布模型、采样方法和神经网络方法等主题的实现。如下展示了线性模型文件夹下所包含的具体算法:
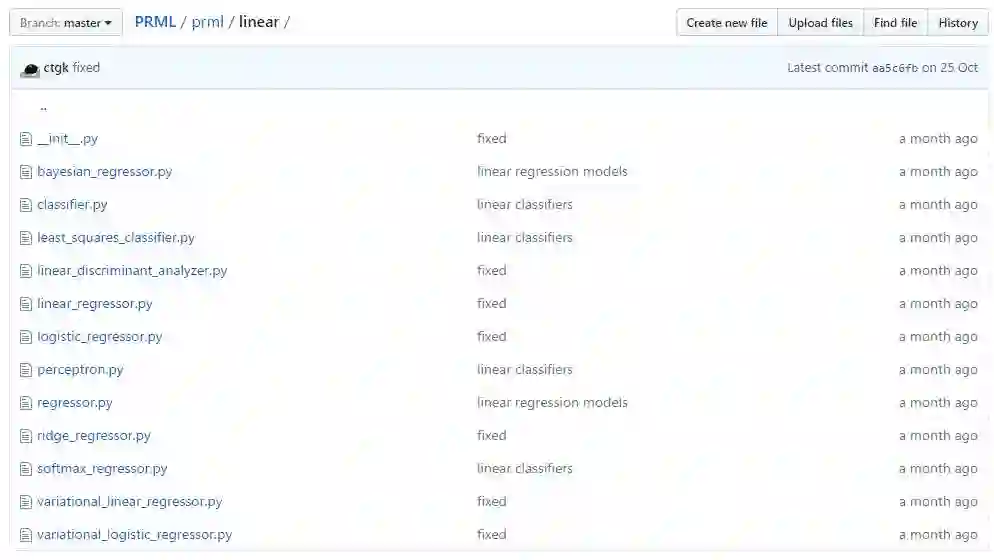
而对于 Notebook 部分来说,该项目展示了 PRML 各章节的辅助内容与实现代码,这一部分的内容目录如下:
ch1. 简介
ch2. 概率分布
ch3. 线性模型和回归
ch4. 线性模型和分类
ch5. 神经网络
ch6. 核方法
ch7. 稀疏核机器
ch9. 混合模型与 EM 算法
ch10. 近似推断
ch11. 采样方法
ch12. 连续隐变量
这些章节都是根据原书章节进行展示的,例如在简介章节中,该项目重点展示了多项式曲线拟合和贝叶斯曲线拟合。如在多项式拟合中,我们希望用以下形式的多项式拟合数据:
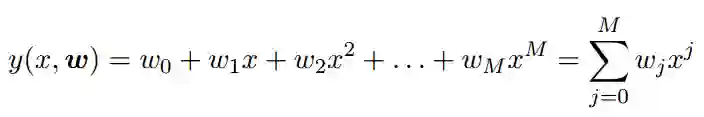
其中 M 为多项式的阶数,多项式系数 w_0, . . . , w_M 可以整体表示为向量 w。这些多项式系数可以通过梯度下降等方法调整多项式曲线拟合数据的情况。该 GitHub 项目先导入前面定义的具体模型,然后如下所示,再在 Notebook 部分展示模型的结果:
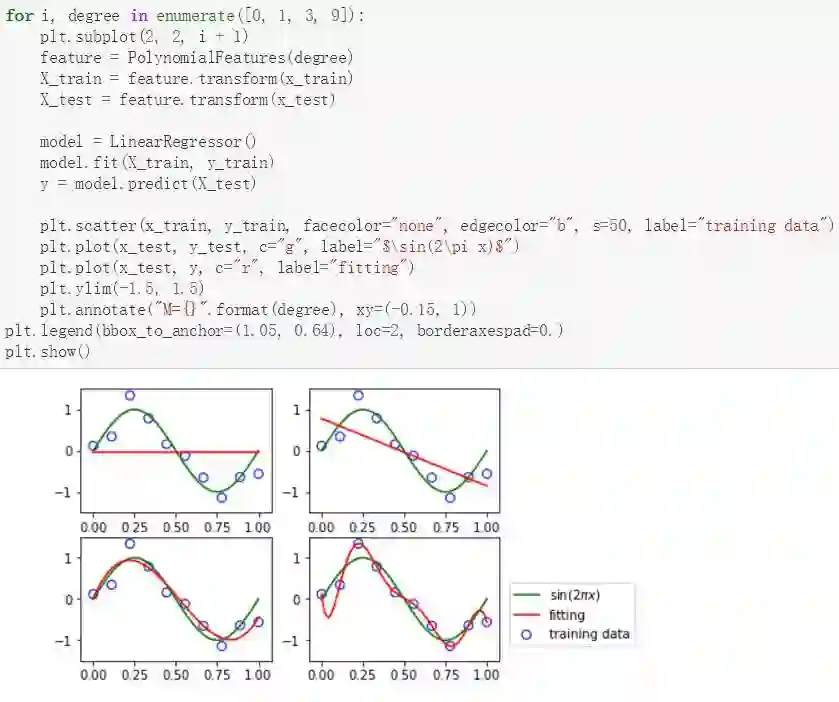
这和原书中的结果是非常相似的,我们甚至可以进一步调整不同的多项式复杂度以查看不同的拟合效果。因为增加了实践过程,这样的实现非常有助于我们理解原书中的概念与算法。此外,如果我们对算法的理解有什么疑惑,也可以查看具体的代码加深理解。
前面展示的案例是简介部分非常简单的多项式拟合方法,而对于更复杂一些的模型与方法,该项目也有非常好的实现与展示。例如在第七章中,PRML 主要介绍了稀疏核机器(Sparse Kernel Machines),包括最大间隔分类器、相关向量机(Relevance Vector Machines/RVM)等方法。如下所述,该项目对这一部分的内容也有非常好的辅助作用。
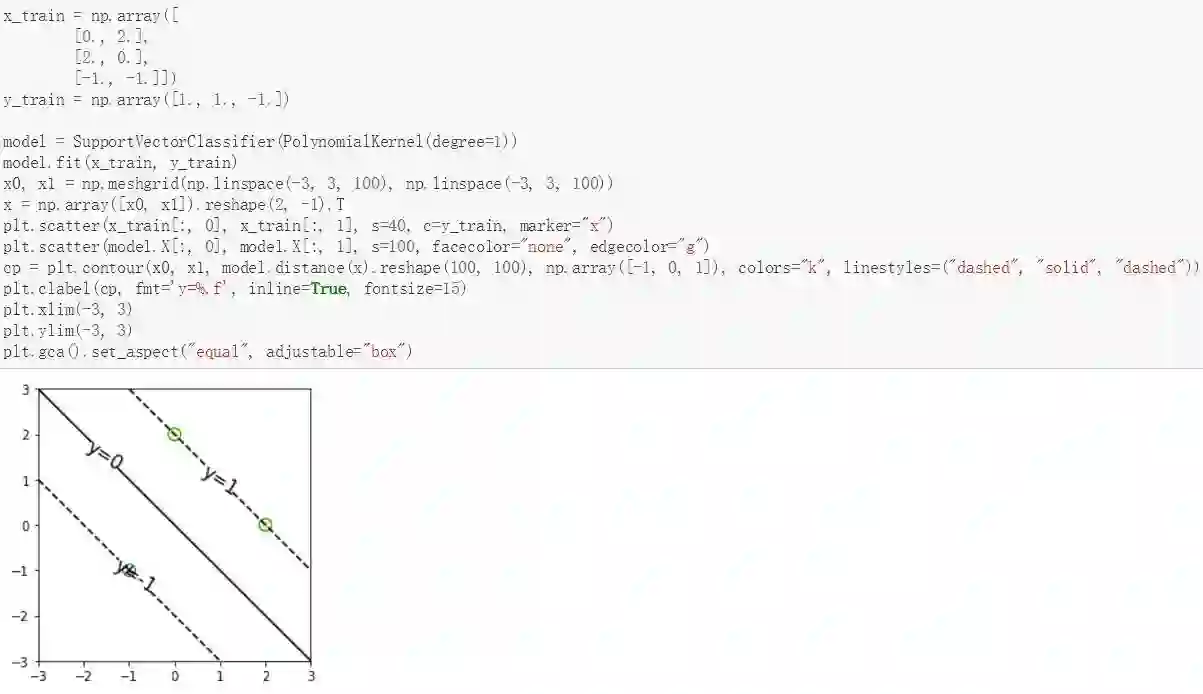
例如在最大间隔分类器或支持向量机中,我们假设训练数据集在特征空间中是线性可分的。因此根据定义,存在至少⼀个 参数 w 和 b 的选择方式,使得对于 t_n = +1 的点,线性模型 y(x) = w*φ(x) + b 都满足y(x_n) > 0,而对于 t_n = -1 的点,都有 y(x_n) < 0。因此对于所有训练数据点,我们有 t_n*y(x_n) > 0。
但是这种分类的情况会有很多,我们可以选择最稳妥的分类方法,即决策边界尽可能地处于所分类别的中间。支持向量机解决这个问题的方法是:引入间隔(margin)的概念,这 个概念被定义为决策边界与任意样本之间的最小距离,如原书第七章图 7.1 所示。
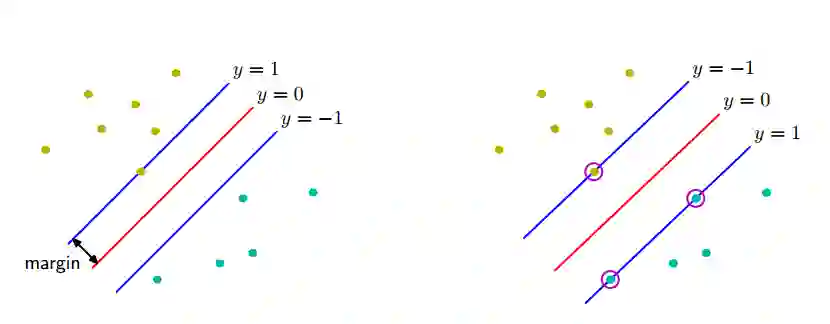
如左图所示,间隔被定义为决策边界与最近的数据点之间的垂直距离。最大化间隔会生成对决策边界的一个特定的选择,如右图所示。这个决策边界的位置由数据点的一个子集确定,被称为支持向量,用圆圈表示。
在该 GitHub 项目中,其展示的代码与绘图如下所示:
若我们应用和方法将这种大间隔分类的方法应用核技巧,将原本线性不可分的数据投影到线性线性可分的特征空间中,那么我们就能将这种具有大间隔或具有更强泛化能力的分类器推广到非线性分类中。如下展示了该项目这种扩展的支持向量机模型:

当然,本项目还有更多的模型与方法案例,我们可以按照 README 文件中所给出的 Notebook 文档加强对 PRML 这本权威教材的理解。该项目目前还在进一步完善,也希望各位 PRML 的读者能共同完善它,为我们自己提供更加优秀的学习资源。
有缘的人终会相聚,慕客君想了想,要是不分享出来,怕我们会擦肩而过~
《【调查问卷】“屏幕时代,视觉面积与学习效率的关系“——你看对了吗?》





