IBM研究院提出Graph2Seq,基于注意力机制的图到序列学习
介绍
Seq2Seq(序列到序列)及其变体在机器翻译、自然语言生成、语音识别、新药发现之类的领域表现非常出色。大多数Seq2Seq模型都属于编码器-解码器家族,其中编码器将输入序列编码为固定维度的连续向量表示,而解码器则解码向量得到目标序列。
然而,Seq2Seq有一个限制,它只能应用于输入表示为序列的问题。而在许多问题中,输入为更复杂的结构,比如图(graph)。对于这类图到序列(graph-to-sequence)问题,如果要应用Seq2Seq,就需要将图转换为序列。然而,将图精确地转换为序列是一项艰巨的挑战,因为在将图这种比较复杂的结构数据转换为序列时,难免会损失不少信息,特别是当输入数据本身适合用图表示的时候。最近的一些研究尝试在输入数据中提取句法特征,例如句子的词组结构(Tree2Seq),或将注意力机制应用于输入集(Set2Seq),或将句子递归地编码为树(Tree-LSTM)。在特定类别问题上,这类方法取得了充满希望的结果,然而,这类方法大多难以推广。
为此,IBM研究院的Kun Xu、Lingfei Wu等提出了Graph2Seq,一个端到端的处理图到序列问题的模型。
Graph2Seq采用与Seq2Seq相似的编码器-解码器架构,包括一个图编码器和一个序列解码器。图编码器部分,通过聚合有向图和无向图中的相邻信息,学习节点嵌入。然后根据学习到的节点嵌入,构建图嵌入。序列解码器部分,论文作者设计了一个基于注意力机制的LSTM网络,使用图嵌入作为初始隐藏状态,输出目标预测。注意力机制用于学习节点和序列元素的对齐,以更好地应对大型图。整个Graph2Seq的设计是模块化的,可扩展性很好。比如,编码器可以换成图卷积网络,解码器可以换成普通的LSTM。
Graph2Seq模型
在上一节的末尾,我们已经简单介绍了Graph2Seq的架构。这一节我们将具体介绍Graph2Seq模型。下面是Graph2Seq的整体架构示意图。
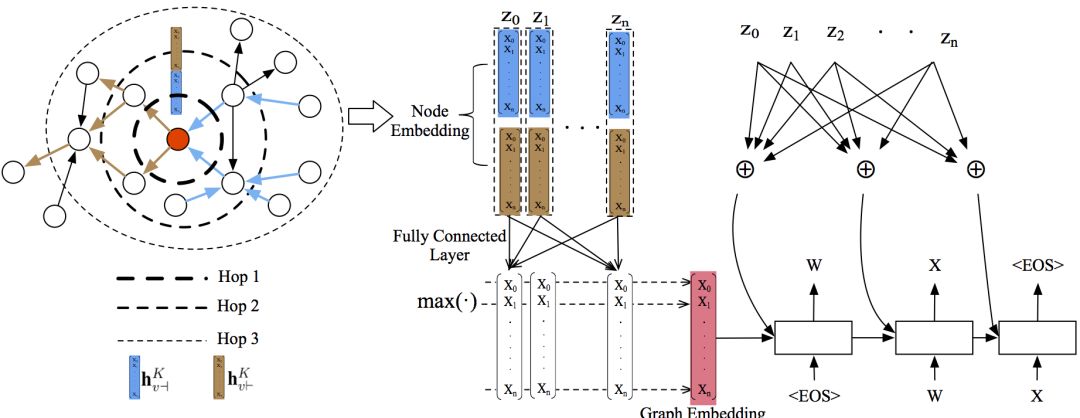
节点嵌入生成
如前所述,节点嵌入中包含了节点的相邻信息。具体的嵌入生成过程如下:
通过查询嵌入矩阵We,将节点v的文本属性转换为一个特征向量av。
根据边的方向,将v的邻居分类为前向邻(forward neighbor)N|-(v)和反向邻(backward neighbor)N-|(v)。
将v的前向邻的前向表示
聚合为单个向量
其中k为迭代索引。注意,在迭代k时,聚合仅仅使用k-1时生成的表示。每个节点的初始化前向表示为其特征向量。
我们将v的当前前向表示(k-1)和新生成的前向聚合向量(k)连接。连接所得的向量传入一个带非线性激活的全连接层,从而更新v的前向表示,在下一次迭代中使用。
将上述过程应用于反向表示。
重复前向表示聚合与反向表示聚合过程K次,连接最终的前向表示和反向表示,作为v的最终表示。
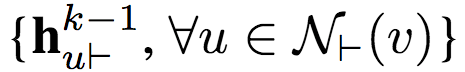
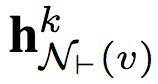
用伪代码表示以上节点嵌入生成过程:

上面我们提到了聚合前向表示和反向表示,却没有提到具体的聚合方法。实际上,论文作者尝试了3种不同的聚合方法。
均值 这是最简单直接的聚合方式,取分素均值(element-wise mean)。
LSTM 使用LSTM处理节点邻居的单个随机排列(无序集)。
池化 将每个邻居向量传入一个全连接网络,然后应用分素最大池化(element-wise max-pooling)。
其中,σ为非线性激活函数。
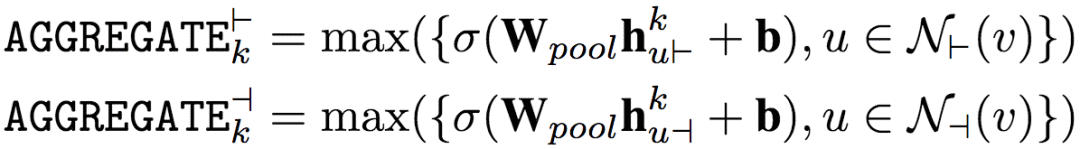
经论文作者试验,总体而言,最简单的均值聚合效果最好。
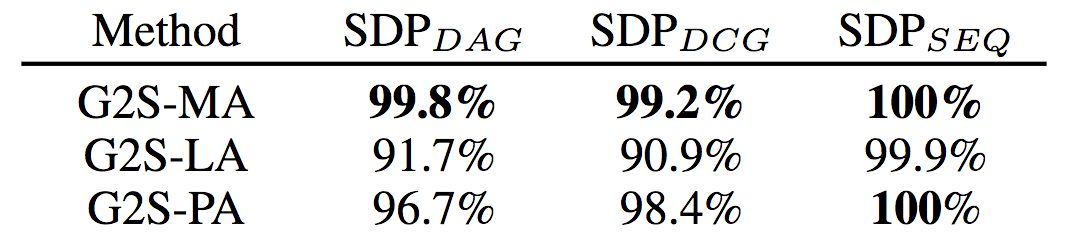
均值(MA)、LSTM(LA)、池化(PA)聚合在3个合成SDP数据集(有向无环图、有向有环图、序线图)上的精确度
图嵌入生成
论文作者引入了两种基于节点嵌入构造图嵌入的方法。
基于池化的图嵌入。类似上面基于池化的聚合,论文作者将节点嵌入传给一个全连接神经网络,然后分素应用池化方法。论文作者共试验了三种池化方法,最大池化、最小池化、平均池化,最后发现三种池化方法没有显著差别。因此,论文作者最后选用了最大池化作为默认的池化方法。
基于节点的图嵌入。这一方法加入了一个超(super)节点vs至输入图,使图中的所有其他节点指向vs。我们使用之前提到的节点嵌入生成算法生成vs嵌入,因而vs嵌入捕获了所有节点的信息,可视为图嵌入。
经论文作者试验,总体而言,基于池化的图嵌入表现较好。
基于注意力的解码器
序列解码器是一个基于注意力的LSTM网络,根据给定的y1,...,yi-1,隐藏状态si(i表示时刻),以及上下文向量ci,预测下一个token,即yi。其中,上下文向量ci取决于前述图编码器根据输入图生成的节点表示集合(z1,...,zv)。具体而言,上下文向量ci通过节点表示的加权和计算得出:
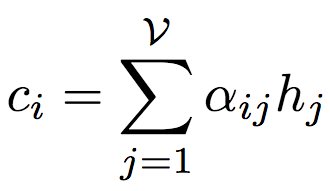
相应的权重aij由下式计算得出:
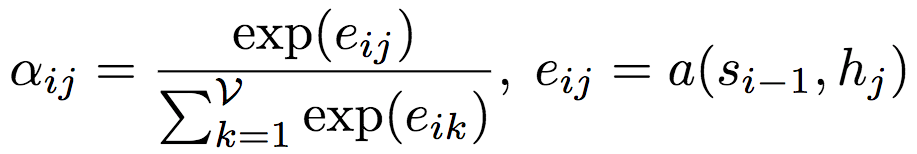
其中,a为对齐模型(alignment model),为j处的输入节点和i处的输出的匹配程度评分。评分基于LSTM的隐藏状态si-1和输入图的第j个节点表示。对齐模型a为前馈神经网络,和系统的其他部分一起训练。
试验
试验设定
论文作者使用了Adam优化,mini-batch大小为30,学习率为0.001,解码器层dropout率为0.5(避免过拟合)。norm大于20时裁剪梯度。图编码器部分,默认跳(hop)大小为6,节点初始特征向量为40,非线性激活函数为ReLU,聚合器的参数随机初始化。解码器为单层,隐藏状态大小为80. 如前所述,使用了表现最佳的均值聚合和基于池化的图嵌入生成。
试验结果
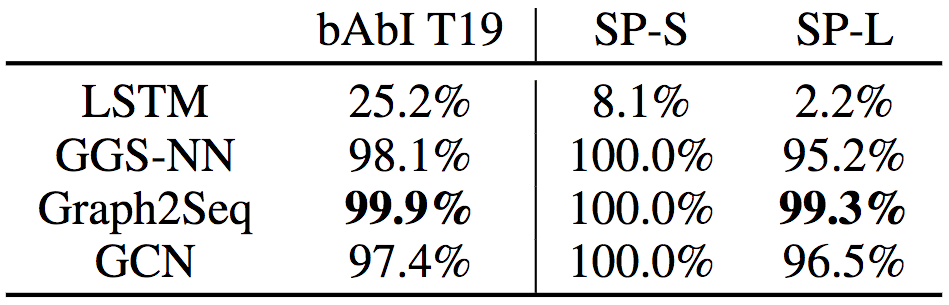
从上表可以看到,在bAbI Task 19上,LSTM失败了,而Graph2Seq的表现是最好的,超过了GGS-NN和GCN。
而在最短路径任务(Shortest Path Task)上,LSTM同样失败了。尽管GGS-NN、GCN、Graph2Seq在小数据集上(SP-S,节点尺寸=5)上都达到了100%的精确度,但在大数据上(SP-L,节点尺寸=100),得益于解码器部分注意力机制的应用,Graph2Seq的表现超过了GGS-NN和GCN。
最后,论文作者在自然语言生成(Natural Language Generation)任务上评估了Graph2Seq的表现。具体而言,这一任务根据SQL查询语句,生成描述其含义的自然语言。论文作者使用的是WikiSQL数据集,该数据集包含87726对手工标注的自然语言查询问题,SQL查询,以及相应的SQL表。WikiSQL原本是为评测问题回答任务而创建的,这里论文作者逆向使用该数据集,将SQL请求视作输入,将生成正确的英语问题视作目标。WikiSQL的SQL请求分割为训练、验证、测试集,分别包含61297、9145、17284个请求。
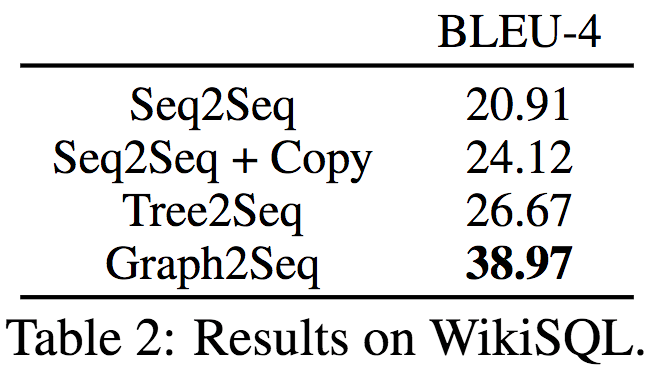
从上表可以看出,Graph2SQL的BLEU-4评分显著高于Seq2Seq、Seq2Seq + Copy、Tree2Seq。





