“世界最美机器人之父”陈小平:机器人灵巧性可解决不确定性问题

中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元 · AI WORLD 2017
演讲嘉宾:陈小平
【新智元导读】新智元AI WORLD 2017 世界人工智能大会,中国科技大学教授陈小平教授做了以《机器人灵巧性——人工智能的新挑战》为题的分享。他介绍了以AlphaGo为代表的AI新进展、传统工业机器人的发展、当前智能机器人面临的新挑战和机器人灵巧性技术。提出现有突破重点在于:在确定性问题领域中,智能系统建造的工程可行性得到了显著提升。对于非确定性问题领域,人工智能和机器人仍然存在巨大的理论和工程挑战,机器人灵巧性是解决不确定性领域问题的一条新途径。

日前,波士顿动力发布机器人Atlas的最新视频。这个会后空翻的机器人在网络上引起了热议。在此前的新智元AI WORLD 2017 世界人工智能大会,中国科技大学教授陈小平教授做了以《机器人灵巧性——人工智能的新挑战》为题的分享。
以下是陈小平教授的演讲。
陈小平:非常高兴有这个机会,和大家分享一些思考。我演讲的主题是《机器人灵巧性——人工智能的新挑战》。

主要从四个方面讨论:第一个部分解读以AlphaGo为代表的人工智能的新进展。第二部分回顾传统工业机器人的成功经验和局限。这两部分讲清楚以后,我们就会提出一个问题:人工智能有非常大的进展,而传统工业机器人从1961年开始就进行了大规模的产业化应用,为什么至今智能机器人还没有进入产业化的阶段?第三部分是分析我们面临的挑战。在分析基础上我们提出一个新的想法,就是要建立以灵巧性为核心的新的机器人技术体系,来应对当前智能机器人面临的新挑战。

第一部分,以AlphaGo为代表的进展到底是什么?为此,首先要说明围棋有多复杂。计算机科学中通常用两个指标来衡量问题的复杂度,人工智能也用这两个指标。第一个指标叫状态空间复杂度,直观说就是衡量棋子在棋盘上有多少种不同的合法摆法。经过严格测算,总共有2.08*10^170个摆法。第二个指标是博弈树复杂度,指围棋可能下出多少盘不同的棋。总数约为10^300。


这张图非常重要,叫做围棋的博弈树,就是把所有可能下出来的棋画在一个图里。按照规则黑棋先行,图中第一行中的那个节点代表黑棋的第一步走法,共有361种不同的选择,所以这个节点下面的第二行有361个节点,每个节点代表黑棋第一步的一种走法。对其中黑棋的任何一个走法,白棋的第一步有360种选择,所以在第三行总共产生361*360个节点,每个节点代表一个棋局。下面又轮到黑棋,每一个棋局中黑棋的第二步有259种选择,于是博弈树的第四行有361*360*359个节点。这样一直画下去,得到一棵“树”。到了最后一层,每个节点称为终止状态,表示棋已经下完了,分出胜负了。所以最底下一层有多少个节点,就表示有多少种不同的棋局。经过推算,总数约为10^300种。这样一个博弈树,不是代表具体的一盘棋是怎么走的,而是表示围棋里所有可能走出来的棋。围棋规则决定了这棵博弈树,下面很多讨论都是基于这样一个观察。
人工智能怎么下围棋?要做计算建模。计算建模有很多种,我讲一种理论上最清晰的办法。AlphaGo也是用这个模型,即围棋的决策论模型,由四个部分构成。第一个要素叫状态,就是符合围棋规则的棋盘上的格局,也就是合法的棋子摆法,每一种合法的摆法叫一种状态,一共有大约10^170种。第二个要素叫行动,也就是每一个合法的走步,黑方或者白方落一个子,符合规则就可以了。黑棋第一步有361种走法。这个数字其实非常大,国际象棋大概平均是35种走法。第三个要素,叫做回报Reward,围棋里指结束状态的“效用”,也就是这盘棋的输赢。第四个要素是博弈树的深度。根据现代围棋规则,一盘棋一天以内一定要下完。按照现在规则和走子的最少时间,可以算出一盘棋最多走多少步,这个数字是有限的。在这四个要素的基础上,就可以建模了。这个模型建出来,和经典决策论模型有所不同,因为AlphaGo计算模型里没有概率转移函数。
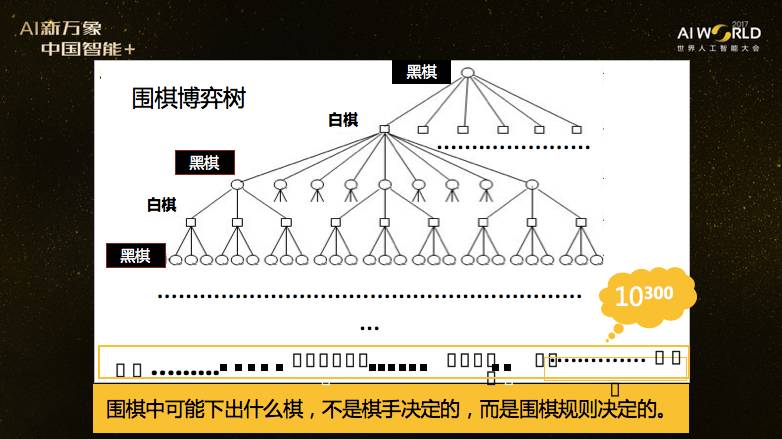

下面我们要提到围棋规则的“良定义性”,指的是围棋规则决定了围棋决策论模型的以下几个特性:第一个特性是模型中状态的良定义性。即每个棋盘格局是不是“合法的棋局”,这是唯一确定并由规则决定的。第二个特性是模型中行动的良定义性,每个走步是不是“合法的”是确定的,并且由围棋规则决定。第三个特性,模型中回报函数的准良定义性,就是每一个结束状态的效用是唯一确定的,并由规则决定的。

拥有这三个特性,围棋规则就有良定义性,并且是一个完全信息的确定性博弈。那么,AlphaGo有什么创新?分两个方面,一个是工程创新。最近发布的AlphaGo Zero有三个核心技术:强化学习、残差模型、MCTS。由于围棋的良定义性和强化学习技术的应用,决定了围棋策略具有可自学性。强化学习只需要结束状态的回报,而围棋规则决定了结束状态是有回报的,这两个因素的结合,使得在围棋决策论模型中就能学习下棋的策略,也就是围棋策略的可自学性。第二个重要的工程创新,是深层神经网络的应用,用这种网络来重组强化学习得到的围棋知识。这个知识不是来自于人类,而是程序自学出来的,用一个神经网络重组这些知识。第三个技术,引入残差模型,从而保证深层的神经网络是有效的。深层网络过去无效是因为传递函数复合层数多了以后,无法区分不同节点的差别。孙剑博士团队2015年提出残差模型,做出了非常大的贡献。AlphaGo三代就用了这个技术。这些是工程上的创新。

另一方面是理论创新。AlphaGo的理论创新是“绕过”概率转移函数。AlphaGo是基于决策论模型的,但是它不用概率转移函数,而是直接学习值函数和策略,到三代时它又将这两个部分结合起来。我们看一下经典决策论模型,这个模型中概率转移函数即T函数是少不了的。另一方面,人类研究决策论模型,研究了几十年,从来没有得到过一个大规模实用的概率转移函数。到了AlphaGo,直接用值函数和最优策略的一种优化表示,到三代又把这两个组合了,这是它的理论创新。

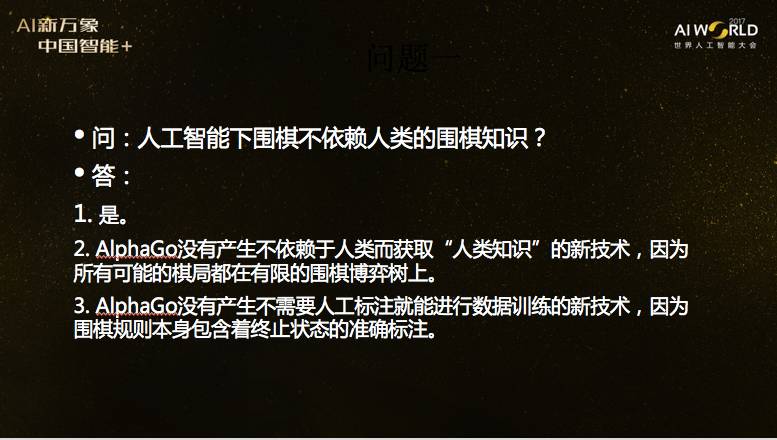
下面我们回答三个大家都非常关注的问题。第一个问题是,人工智能下围棋可以不依赖于人类的围棋知识吗?回答是不依赖。但是这样说没有完全回答问题,其实我们想问的是下面两个问题。第一个是,AlphaGo有没有产生不依赖于人类而获取人类知识的新技术?答案是没有,因为所有可能棋局都在有限的围棋博弈树上,人下棋是在博弈树上走了一部分,AlphaGo也在上面走,它就能获取围棋策略知识,所以它没有产生不依赖于人类而获取人类知识的新技术。另一个问题是,AlphaGo有没有产生不需要人类标注就能够进行数据训练的新技术?答案是也没有。因为围棋规则本身包含着终止状态的准确标注,也就是终止状态的回报。所以,AlphaGo不像一些人想象的那么可怕,也不像有些人想象的那么无能。
第二个问题,很多人关心,AlphaGo三代的自学能力能不能用于别的场合?第一个回答,对于确定性的问题,原则上AlphaGo技术都可以应用。第二个回答,对于非确定性问题,我们现在不知道能不能用,估计直接用是不行的。在这方面,深层神经网络的知识重组能力和泛化能力是远远强于其他人工智能技术的。比如说,1997年深蓝就打败了国际象棋世界冠军,但那套技术用来做围棋就不行,它的知识表达方法不一样。这说明深层神经网络的重组能力和泛化能力非常强。进一步我们观察到,对于常见的非确定性问题,AlphaGo这套技术不见得行,还需要更多的创新。

第三个问题,人工智能的学习能力是不是比人强?对于确定性的问题,回答是肯定的,人工智能可以用更少的训练量获得比人类更好的学习结果。第二个回答,人类下过的棋局,相对于围棋博弈树而言,其实非常有限。

我们推算一下。目前全世界现役的围棋九段不到200人。我们假设世界所有现役的围棋高手1000人,假设历史上任何一个年代和当代有同样多的围棋高手,就是任何一个年代都有1000名围棋高手,他们能发明新的围棋知识。这些围棋高手每人每天平均下3局,有人说快棋能下很多局,但是快棋很难发现新知识,所以不考虑快棋。另外,围棋历史有多长?有确切证据的估计是一千多年,最大胆的估计是4400多年,那我们就算4400年。把这些数据整合起来,得到一个推算:历史上人类围棋高手总共下过大约50亿局棋,还不到10的10次方。那围棋博弈树上总共有多少种可能的棋局呢?有10的300次方。这个差距有多大,很难想象。我举个例子,我们对比一下,全世界海水有多少?这个有比较准确的估算,有大约13亿8600万立方千米,换算一下就是7×10^34滴水。而一瓶500毫升的矿泉水包含2.5×10^4滴水。这是什么概念呢?一瓶矿泉水和全世界大海里的水,在直观上是不可比的,但转换到幂指数上,只不过是4与34的比较。人类下过的棋局数和按照规则可能下出的棋局数的比较,转换到幂指数上,却达到惊人的10与300的比较。这样看来,似乎人类下过的棋局是非常有限的。
我们进一步提出疑问:中国古人为什么发明这么复杂的棋,以至于下了几千年都没有下出多少棋,这说明什么?这个问题的回答放到后面。

第二部分,简单回顾工业机器人的成功与局限。工业机器人说起来很简单,它的硬件由关节和连杆结构构成,用运动学计算、控制所有关节角度,使得末端达到指定位置,重复精度可以达到亚毫米级。主流的控制策略,我们列了几个,而控制原理就是两种,一种就是决策论,实际上无法得到概率转移函数,计算效率也太低。另一种经典控制原理——模糊控制,其原理也总结为一句话,在这个框里面。它面临的问题是类似的,也就是在实际中很难得到模糊度。

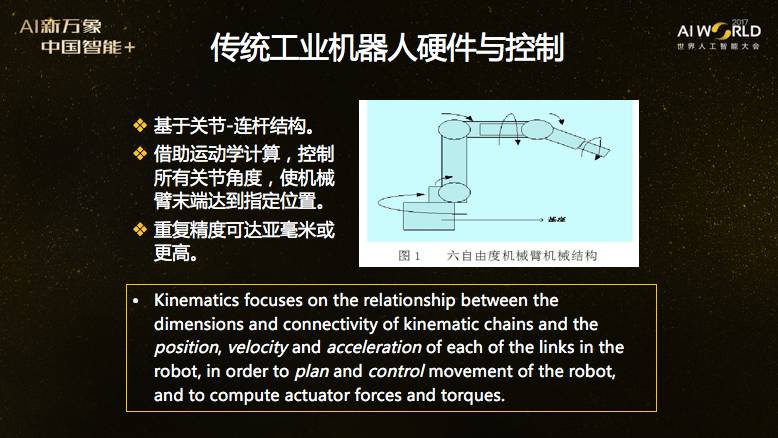


所以,实用的控制方法是运动学,有时候也用动力学,用它们简化决策论模型,最终实现了精确性,但丧失了灵巧性。由此导致在大量实际场景中的应用受到限制,而且工程部署的代价非常高。


技术是怎么落地的?看一下机器人产业的“真相”。图中左上部灰色部分是一个夹具,蓝色的是工件,用夹具将工件夹住,并通过精确测量,让夹具和机械臂之间的相对位置保持不变。事实上,工业机器人不是只靠机械臂,还要把整个生产过程都精确化。过去认为,工业机器人的精确性就是机械臂的精确性,这个观点是不对的。正确的认识是:工业机器人的精确性等于机械臂的精确性加上环境的精确性。

当前人工智能挑战在哪?我举几个例子。由于现在还没有实际应用,学术界和产业举办了家庭服务机器人比赛,图中有人摔倒了,机器人要找到他还要帮助他。第二个例子是救援应用,更复杂,如图的场景中,动了一块砖瓦,可能整个废墟又塌了。第三个例子是智能装配,过去生产线都是固定的,但是将来生产线是灵活变化的,同一条生产线可以生产不同的产品。还有其他一些应用场景,如农业等等。





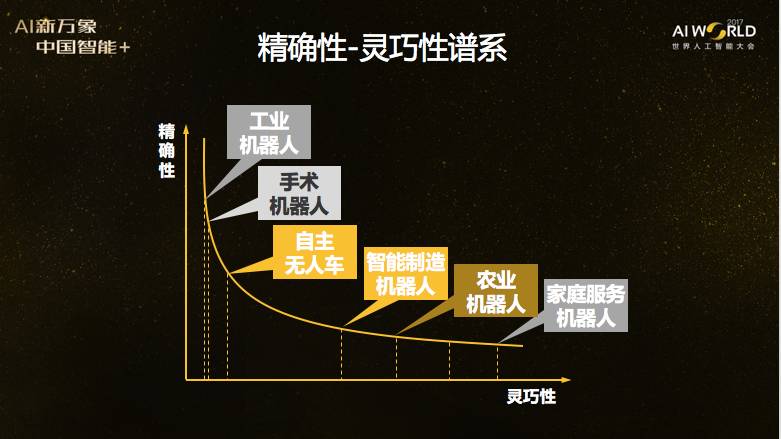
总结所有这些场景后发现,过去成功的应用主要靠精确性。比如工业机器人精确性非常高,但是灵巧性很少。手术机器人精确性很高,灵巧性也很少(人工操纵)。在理想情况下,交通规则被严格遵守,交通设施保存完好,无人车很容易应用,现在的技术条件下就能上路,因为可以依靠精确性,不需要太多灵巧性。但在中国,这两条往往都不满足,因此无人车会非常有挑战性,难度超过农业机器人。家庭服务机器人需要更多灵巧性,救援机器人的挑战就更大了,我在图里都没有列出来。
总结一下,新挑战是什么?传统机器人依靠精确性,新的人工智能AlphaGo依赖确定性。机器人新的应用挑战,要求我们用灵巧性处理不确定性。

下面用一个简单例子来说明灵巧性概念。


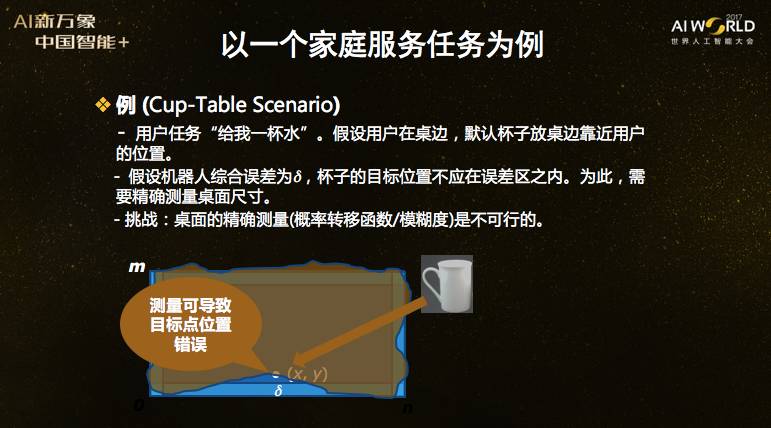
假设我们有一个任务:要机器人放一杯水在桌面上尽量靠边的位置。当然,桌面测量有一定误差,机器人传感器也有误差,所以桌面边缘的“误差区”里不能放杯子,要放到靠里面的“安全区域”中,比如那个白点的位置,叫做“目标位置”。但实际上,精确测量整个桌面的边缘是不可行的,所以依靠精确模型的操作往往会失败。怎么办?
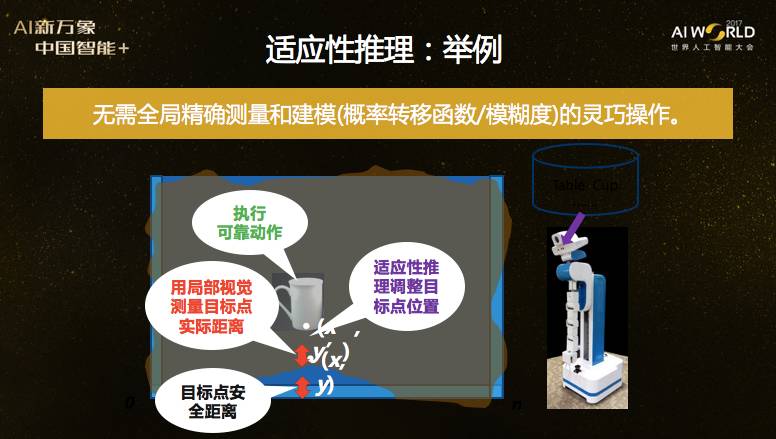
我们提出的解决方法是,全局规划只用粗略模型。这样规划出的放置杯子的目标位置可能是不对的,于是我们再增加办法,用局部视觉测量全局规划得到的目标位置,就测这一点,而不是整个桌子,这是可行的。通过现场适应性推理,调整目标位置,再把杯子放到调整的目标位置。这套方法不需要全局精确测量和全局精确建模,不需要概率转移函数,不需要模糊度,就能实现不确定环境中的灵巧操作。
这是中科大做的可佳机器人,可佳能做什么?她能够自主操作微波炉,完成加热食品的全过程。第一次做出来是在2010年,刚才大家看的视频版本是2011年的。这个工作在国际上得了一些奖。
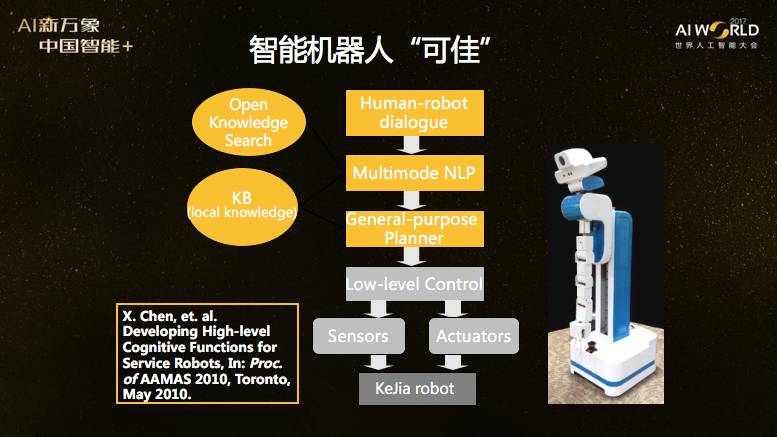

为什么做了这么多年,还没有做产品?我们做了以后发现,在一个固定的环境中,只要把机器人参数调好了,就可以跑的很好。但是不可能每进入一个家庭,我们都去调机器人的参数。肯定是在实验室调好一组参数,能进千家万户。恰恰这一点是我们做不到的。研究后发现,根本原因是依靠精确性不能解决问题,要靠灵巧性解决不确定性。我们认为这是未来的发展方向。
最后小结一下。人工智能正在取得重大进展,但主要还是在确定性问题的领域,面向这种领域的应用,建造大型智能系统的工程可行性得到了显著提升,这对发展产业非常有用。但是,非确定性应用场景是更加广阔的,市场空间和市场价值大得多。对于非确定性问题,还有巨大的理论和工程挑战,我们提出以灵巧性作为一种新途径。因此,无论是人工智能威胁论或者人工智能智障论,我觉得都不对,应该客观理性看待现有的成果和挑战。


未来会怎么样?这就回到刚才没有回答的问题:中国古人为什么发明围棋这么复杂的博弈?我觉得这说明一个事实:作为世界文明的优秀代表之一,中国文化胸怀广阔,气势恢弘,潜力深不可测,前途不可限量。随着中国加入全球人工智能的主战场,未来人工智能的发展会呈现出全新的面貌,给人类带来全新的机遇。谢谢大家!







