教程 | 如何使用Elixir语言实现深度学习?剖析多层神经网络的构建和训练
选自automating the future
机器之心编译
参与:Jane W、吴攀
在这篇文章中,作者们使用 Elixir 编程语言创建一个标准的 3x3 深度学习神经网络。希望读者能通过阅读本文而对先进的遗传编程(genetic programming)和 Elixir 中新的人工智能技术有更深的理解。
开篇语
研究深度学习如从事巫术般疯狂。人们必须花费相当多的时间理解技术,同时在创造真正自动化的东西时考虑其优点和缺点,还要在半夜醒来时担心自动化将对我们的社会造成多大的颠覆。
创建你的第一个神经网络是比较简单的,在过程中你可以看到如何用少量的代码来自动完成一项给定的任务。
在这篇文章中,我们将使用 Elixir 编程语言创建一个标准的 3x3 深度学习神经网络。希望读者能通过阅读本文而对先进的遗传编程(genetic programming)和 Elixir 中新的人工智能技术有更深的理解。
用途
现在的大数据需要未来的自主深度学习系统。为了掌握这些系统工作的原理,我们将构建一个标准的神经网络来学习一个小的问题集。
我发现用 Elixir 从头开始设计和构建这些类型的系统时,有三件事是有帮助的。读者可以参考以下链接作为辅助:
1. 对 Elixir 和 Erlang OTP 生态系统的基本了解:http://elixir-lang.org/getting-started/introduction.html
2.Numerix(一种基于 Elixir 的机器学习库,由 Safwan Kamarrudin 编写):https://github.com/safwank/Numerix
3.Matrix(用于计算矩阵的有用的库,由 Tom Krauss 编写):https://github.com/twist-vector/elixir-matrix
还有其它的 Elixir 包(如 Tensor)允许 Elixir 开发者做出一些复杂的东西,但这里我们将只介绍 Matrix 和 Numerix。
范式
正如前面讨论的,未来的神经网络自动化解决问题的方式与传统训练的编程模型解决问题的方式有很大的不同。这些系统通过样本进行学习。训练者提出所期望的目标或系统实现的目标,并且给系统提供训练样本,直到系统学习如何达到想要的目标(target)。
如果通过人类语言沟通,计算机很难理解生活的细微差别,以及我们想要和需要什么。然而,如果机器通过数字和浮点整数表示实际的数据和问题,那么奇迹般地,它们可以开始解决问题并理解人类!
对于新的软件系统,由过程/对象(procedural/object)驱动的编程现在开始转变为由统计数学/数据(statistical-mathematical/data)驱动的方法。这种新的模式转变是至关重要的,以鉴别读者是否计划在技术行业保持相关性。自从 2011 年 Jeopardy 节目上 WATSON 的到来,老的编程和解决问题的方式已经死了。拥抱这种数据驱动的统计模式的公司将最终领导整个技术行业。
并没有明确的程序指示 WATSON 在那晚的节目上做什么。事实上,WATSON 甚至不知道它会得到什么问题。它所拥有的只是数据、学习算法和多层神经网络。
我们在这里将构建的神经网络不会像 WATSON 那样复杂,但能够说明多层网络的概念以及工作的原理。
问题
假设我们有一个数字序列,它可以表示特定问题空间中的任何东西。让我们假设这个数字序列是 1、0 和 0。这会组成一个看起来像 [1,0,0] 的列表(list)。
但是,这个列表是一个问题。我们想要实现一个都是 1 的序列。该列表表示为 [1,1,1]。这个数字列表可以当作我们的目标。
我们的问题空间,简而言之,列在下表中:
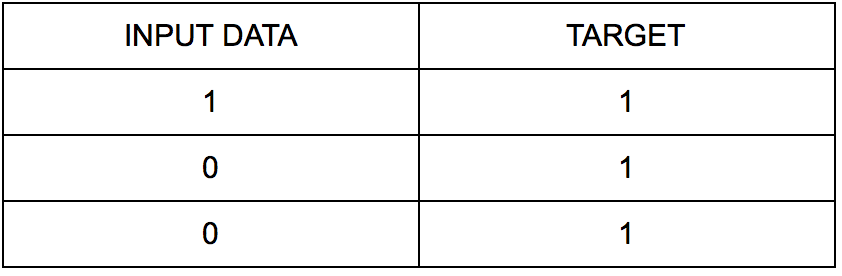
我们将输入与希望得到的目标一起列出。
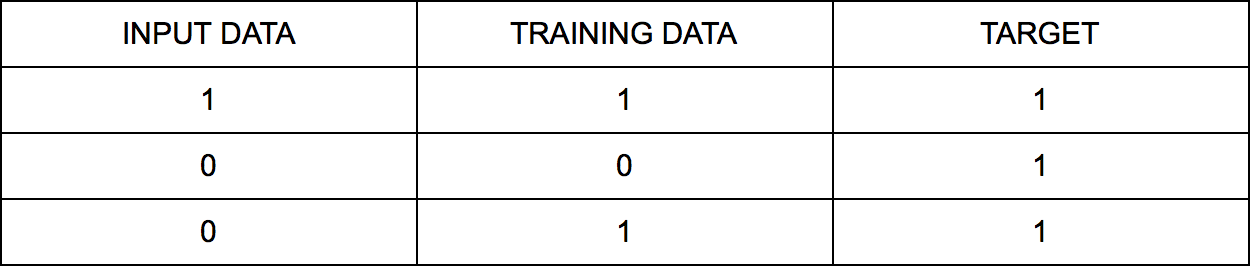
我们希望系统能够区分输入数据与目标数据,因此我们还需要一个随机数据集,以便与目标进行比较。该随机数据集被称为训练集。神经网络用这个训练集来学习如何得到预测结果。加入新增的训练集数据,我们的图表变成下图:
设计
在计算机中表示神经网络的最佳方式是通过矩阵。矩阵是线性代数的有用工具,它允许我们对数字向量进行操作。
从图表中可以看出,有 3 列和 3 行。此图表可表示一个 3x3 的矩阵!
主体的神经网络模型表示为线性代数矩阵列表。数组(array)中的每个元素可以被认为是一个节点/神经元。每个神经元负责计算和生成输出,输出又会影响整个神经网络系统。
多层神经网络分为三部分。第一部分称为输入层。第二层称为隐藏层。最后一部分称为输出层。非常复杂的网络有多个隐藏层,但是对于本文的例子,我们只有一个隐藏层。
当我们从左到右显示数据流时,我们神经网络的图片看起来像这样:
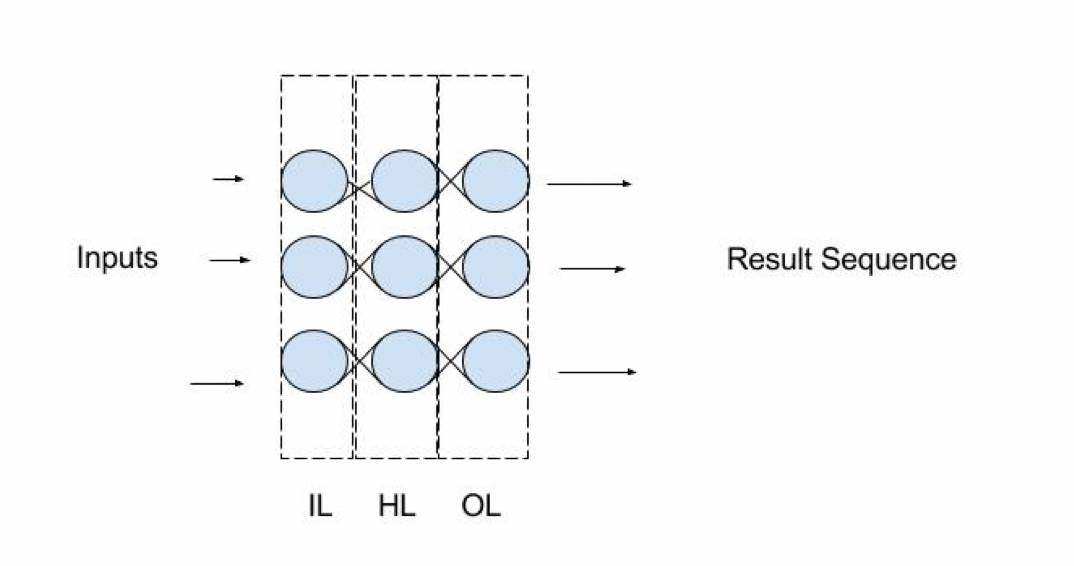
数据流从左到右
IL 代表输入层(Input layer),HL 代表隐藏层(hidden layer),OL 代表输出层(output layer)
每个神经元在网络内表示。我们建立一个 3x3 的网络,因此有 9 个神经元。
如果我们将图表变成这样的架构,它的可视化看起来如下:
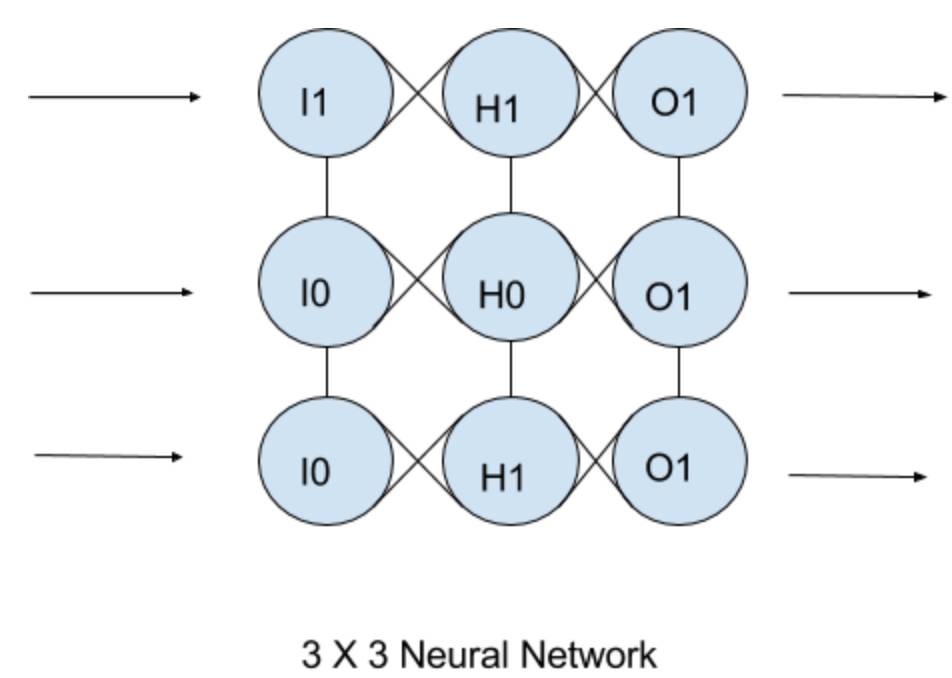
I= 输入,h 表示隐藏,而 o 表示输出。每个数字对应于上面数据图表上列出的数字。
这是我们希望神经网络做的。我们需要它来计算输入,并将其变成我们想要的输出!
代码
现在我们要做的第一件事是创建 Elixir 项目。我决定叫它「DEEPNET」。我们想要一个 Supervisor 让这个项目能更自动化启动,所以我们使用命令:
mix new deepnet --sup
这条命令创建了一个带有 supervisor 的 Elixir 项目。
加载相关包
接下来要做的是加载所需的相关包。我上面提到了 Numerix 和 Matrix,我也加载了 sfmt,以确保我们的随机权重确实是随机的。
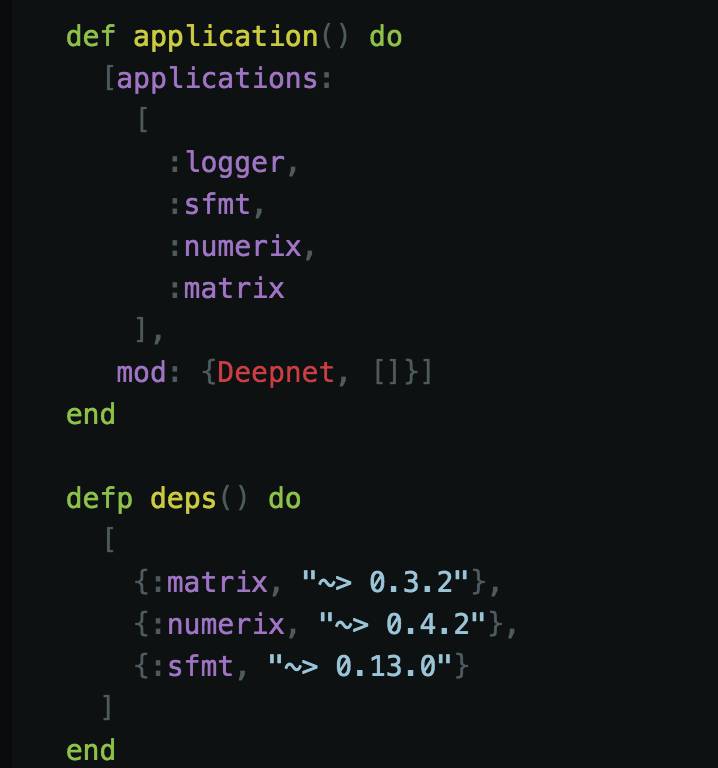
开始应用
我们需要一种方法让 Supervisor 自动启动我们的神经网络。因为想要一个 3x3 的架构,我们需要创建 9 个神经元。这意味着每层都需要有 3 个神经元。这些神经元可以在启动时创建。我们编写一个启动函数来告诉 Supervisor 这样做。
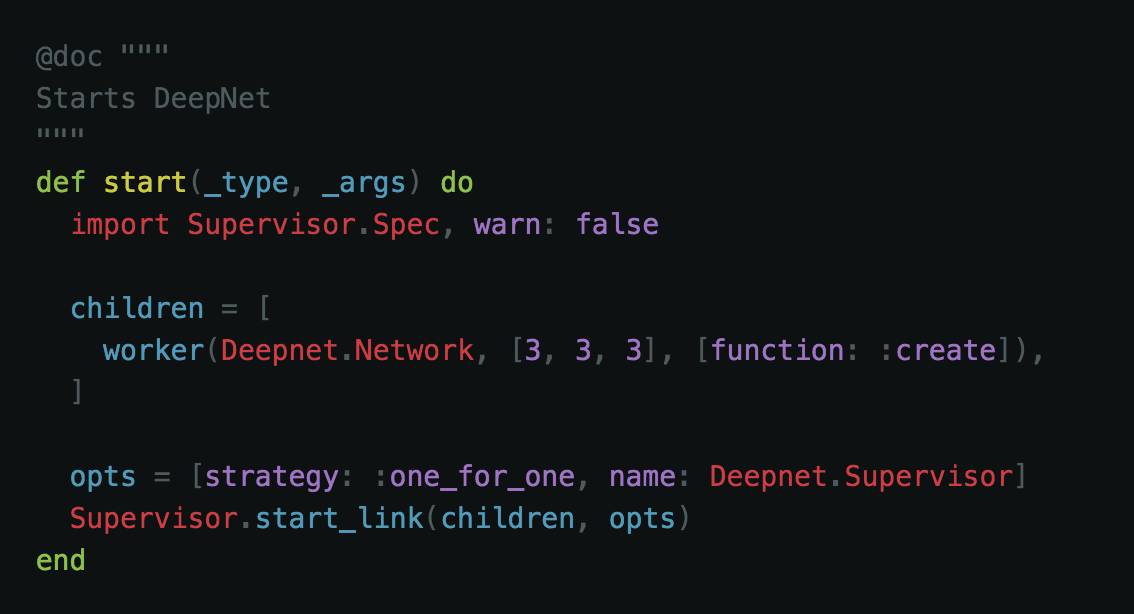
应用的 Supervisor 引用了 Deepnet.Network 模块(我们将在下面介绍)。我们还需要设定神经网络在每一层创建的节点数。
创建网络
我们在这里引用一个 create 函数。这将有助于 Supervisor 下面的工作。create 函数将处理这些数字列表。因为这些数字代表层中的神经元。将初始状态(state)存储在 Elixir 代理(agent)中可能比较明智。
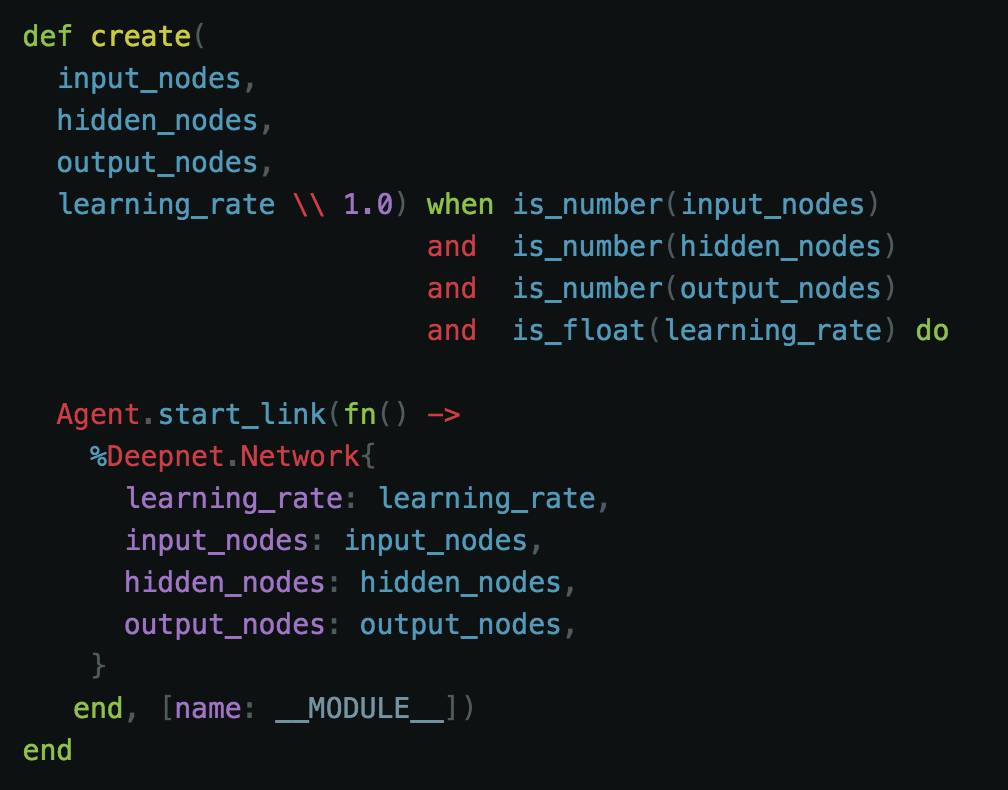
每个参数对应于层中的多个节点。第 4 个参数是学习速率(learning rate),默认为 1.0。这将在后面进一步阐释。
初始化随机权重
如果你一直在学习 ATF,你可能会记得所有神经元都需要与其相关的权重。我们希望权重尽可能随机。这种随机化使我们相信我们在训练期间已经收敛到正确的解决方案。神经网络的训练重点是找到适合于当前特定问题的适当权重。对于每个神经元,我们需要一个函数来创建 9 个不同的权重。我们的计算也需要考虑偏差(bias)。这个函数如下:
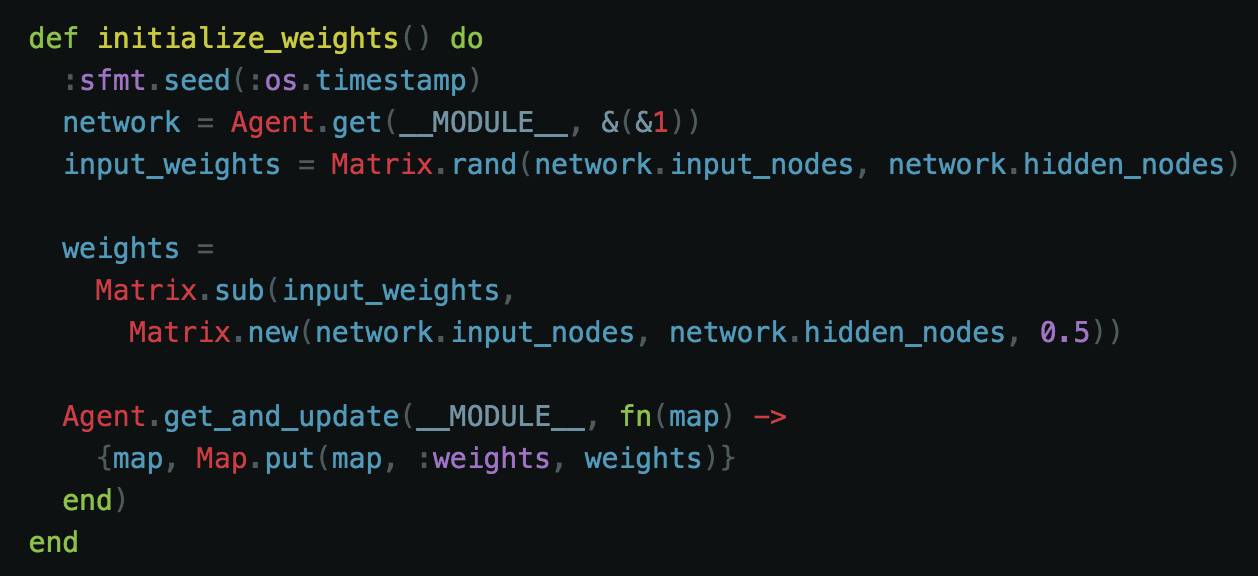
首先,我们利用 sfmt 来播种我们的时间戳以帮助确保我们获得随机权重。接下来我们为输入生成随机权重。但是,我们不想止于此。这会有助于增加新的偏差以便真正平衡我们的权重,随意从一个 0.5 的矩阵减去我们的输入权重将能给我们一个很好的随机化的权重分类以开始。最终,我们使用这些初始化的权重对网络进行了更新。我们的 9 个权重应该看起来像这样:

网络中所有神经元所对应的随机权重。
它的优点在于有一个负权重和正权重的组合
现在我们马上能够得到权重了。让我们先看看矩阵的大小。

现在我们有 3x3 的初始化权重结构。我们的整个神经网络现在看起来像这样

我们的神经网络被表示为 Elixir Struct。除错误率和目标(我们将在下一步探索)之外,我们已经设置好所有的数值。
计算误差
神经网络需要不断地反馈预测性能。这个反馈是通过我们所说的错误率(error rate)收集的。有不同的计算错误率的方法,其方法完全取决于个人。在本文中,我们将使用 MSE,即均方误差(Mean Squared Error)。
神经网络在训练期间的工作是不断的将其输出与训练期间给出的目标输出进行比较。我们需要一种方法来计算并存储神经网络的错误,以便我们监控训练的效果。这个函数的形式很明确:
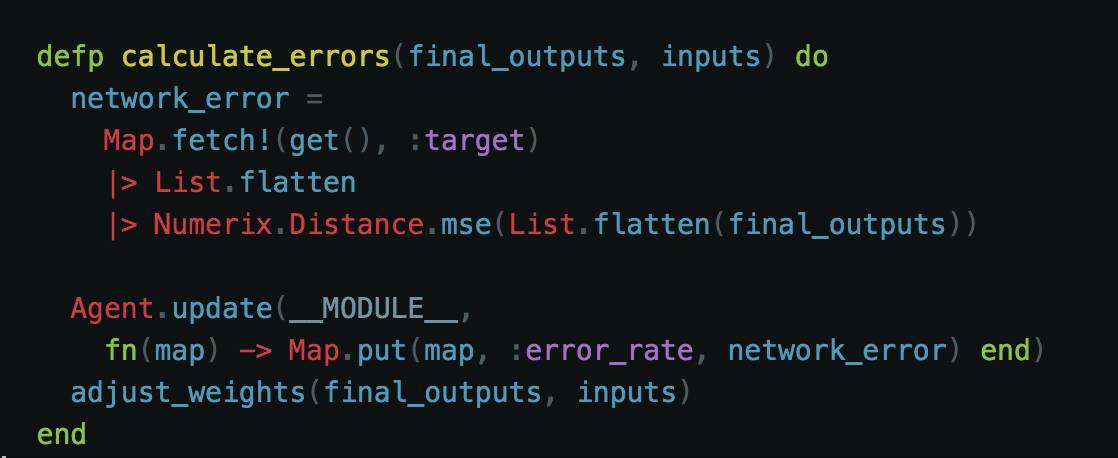
我们取得神经网络的最终输出和初始输入。
然后将整个网络的最终输出与目标进行比较,以便我们可以计算均方误差。
我们引用了 List.flatten/1 函数,旨在将我们的多维列表改为单个列表,使计算更加容易。
最后,我们通过使用神经网络新的错误率来更新代理。
调整网络权重
在上面函数的最后一行你可能已经注意到对 Deepnet.Network.adjust_weights/2 函数的引用。这个步骤很重要。在训练期间,如果神经网络发现与训练的目标发生偏离,它需要一种方法来改进。刚才我提到了学习速率常数。这就是改进神经网络要用到的。让我们来探索 Deepnet.Network.adjust_weights/2 函数:
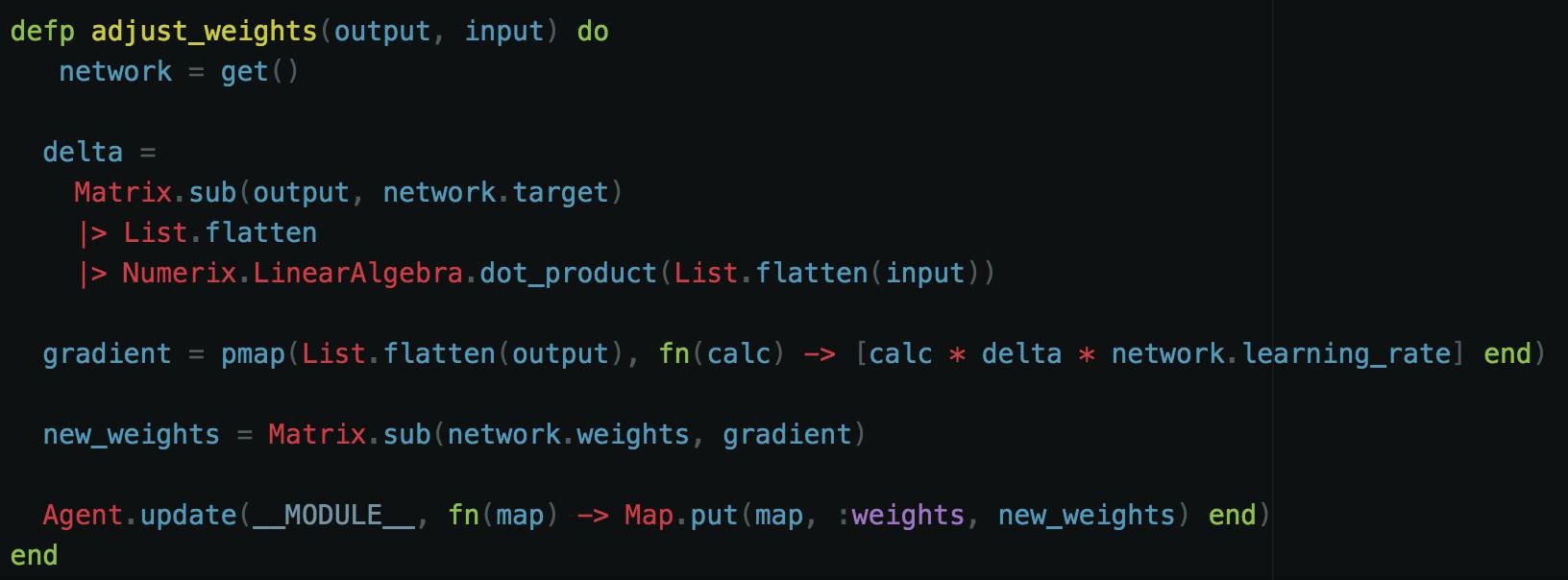
用 adjust_weights 函数接受图层的输出和初始输入
接下来要做的是计算 delta(增量)。这里我们得到目标与输出的差异,并计算该结果的点积。这儿需要单独的计算,即 delta(或小变化)计算。
接下处理梯度(gradient),这是我们能做的使我们更接近最终目标的最小幅变化。因为我们可以处理许多输出,我们将并行(parallel)映射(map)所有输出的梯度计算。梯度计算定义为:输出 x delta x learning_rate(学习速率)
这个学习速率可以是从 1.0 到 3.0 的任何值。也有人用其它的值域。它取决于神经网络的创建者以及需要多快的学习进度。在我们的例子中,我将使用 1.0,因为这个问题并不重要。
最后,取当前的权重,并从梯度中减去它们得到新权重。然后为网络更新新权重。
计算神经元输出
你可能想知道如何产生连续传入函数的输出。我们需要一种方法来计算每个神经元的输出。这里有一篇博客来帮助你复习神经元如何计算其输出(http://www.automatingthefuture.com/blog/2016/10/2/the-power-of-activating-the-artificial-neurons)。
对于我们的特定问题集,我们将使用 sigmoid 函数作为我们的激活函数(activation function)。记住,神经元内部的数据信号经过 3 个阶段。第一阶段是计算输入和权重的总和或点积。下一阶段是使用激活函数。最后一个阶段是加入偏差。我们已经在初始化权重时计入了偏差,所以我们的函数不需要有那个部分。那么我们所有要做的事是阶段 1 和 2。
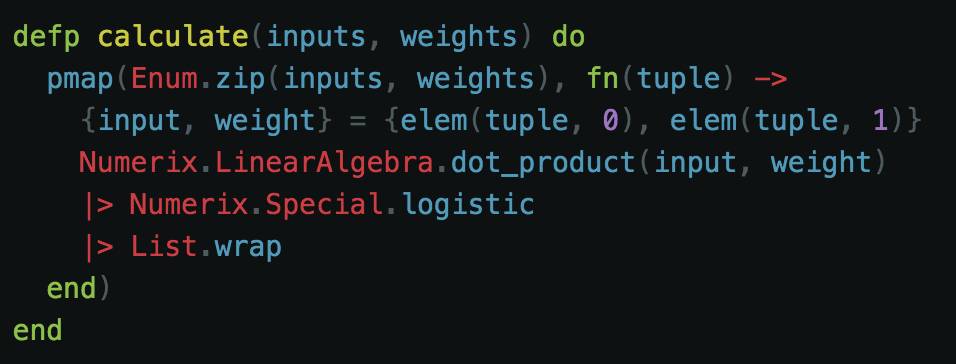
这里我们取输入和权重并做并行映射。每个权重对应一个输入,所以在 Elixir 中我们可以将它们压缩成元组(tuple)。元组的第一个元素是输入,第二个元素是权重。对于每个输入和权重,我们计算:点积(dot_product)/总和 summation。接下来,我们使用 Numerix.Special.logistic/1 函数,它本质上是另一个名称的 sigmoid 函数。
因为我们需要将每一个计算中结果作为一个列表,我们然后打包结果以形成适当形式的输出。
我们现在可以计算、神经元的输出。但是,在完成之前还需要一个步骤。我们需要一种将数据从一层移动到下一层的方法。将数据从上一层移动到下一层的这个过程被称为前馈(feed-forward)。由于我们将数据从输入层前馈到隐藏层,然后将隐藏层的输出传送到输出层,因此我们基本上将数据前馈两次。幸运的是,我们可以很容易的通过 Elixir 的模式匹配做到这一点。
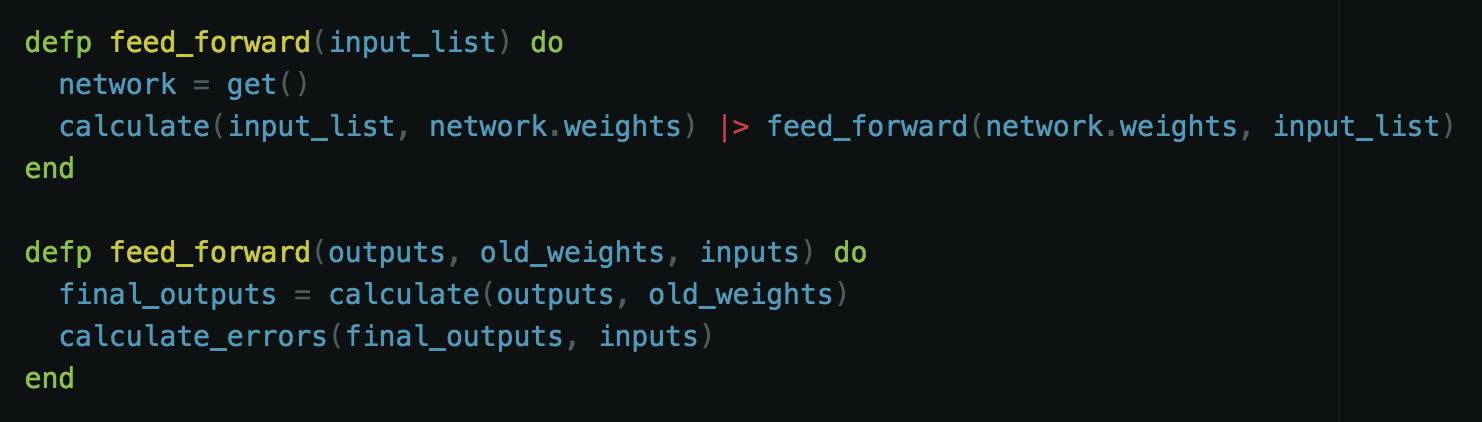
第一个前馈仅接受输入列表,并计算输入层与隐藏层相连接的输出。然后将该结果传递到第二个前馈函数。
第二个前馈函数接收前一层的输出以及前一层的旧权重和原始输入。然后计算最终输出。至此整个神经网络的计算结束。在这里,通过计算网络中的错误率,我们可以看到得到的结果有多好。
过程
学习是一个重复的过程。如果我们的网络没有得到正确的解决方案,它必须再次重复整个过程,直到得到正确结果。每次神经网络将对其自身进行小幅调整,直到达到其最终目标。可以认为这个过程是一个巨大的学习循环。
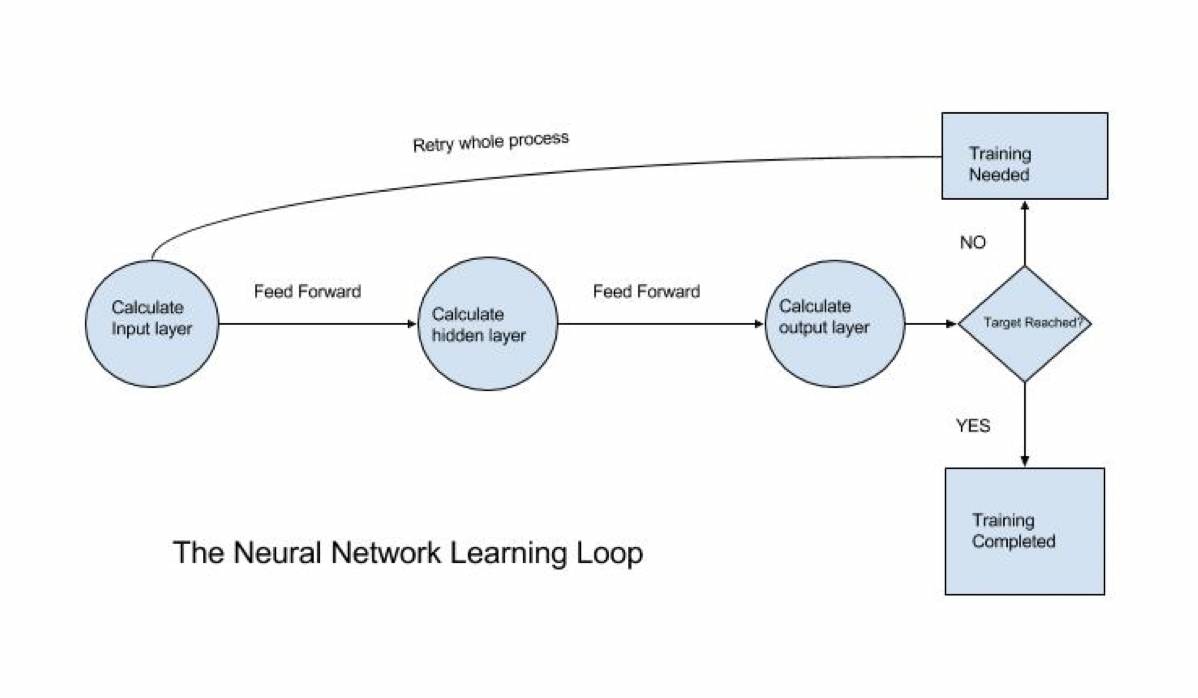
每次循环完成并且网络再次启动以便最小化错误时,我们将该过程称为反向传播(back propagation)。这是因为误差通过网络传播以进行重新调整。这就是现代系统与传统系统的区别。传统系统不得不等待人类来解决存在的错误。现代系统想要最大限度地减少它们的错误率,并力求完美从而减轻工程师的维护负担。从解决问题的角度,希望你开始看到这种好处!
训练自动化
对于神经网络,自动化训练过程总是一个好办法。有时候,对特定问题集的训练可能需要几个小时甚至几天。手动执行这个过程是不明智的,所以我们将编写一个函数来处理这个过程。
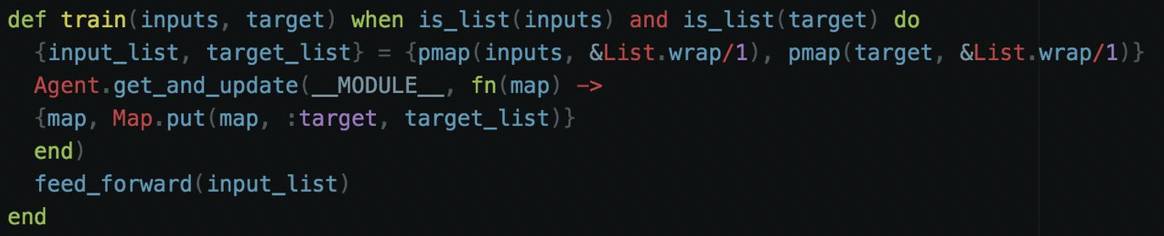
首先,我们取输入列表和目标列表。然后,我们将输入和目标都转换成二维列表。然后我们用目标更新我们的代理,使它不再为零。最后,我们开始前馈过程。
学习自动化
如前所述,学习过程是一个循环。Elixir 是一种功能语言,这使得我们能够使用函数来处理循环。在我们的循环中,我们需要收集输入和目标,并将其传入到网络中。网络训练数据并计算错误率。我们希望得到的错误率最小。因此我希望网络训练的误差率低于 0.02。如果发现其错误率高于 0.02,那么它必须继续训练。这就是学习过程。神经网络必须经历重复循环,直到学习的任务几乎没有错误。我们可以通过模式匹配(pattern matching)实现:
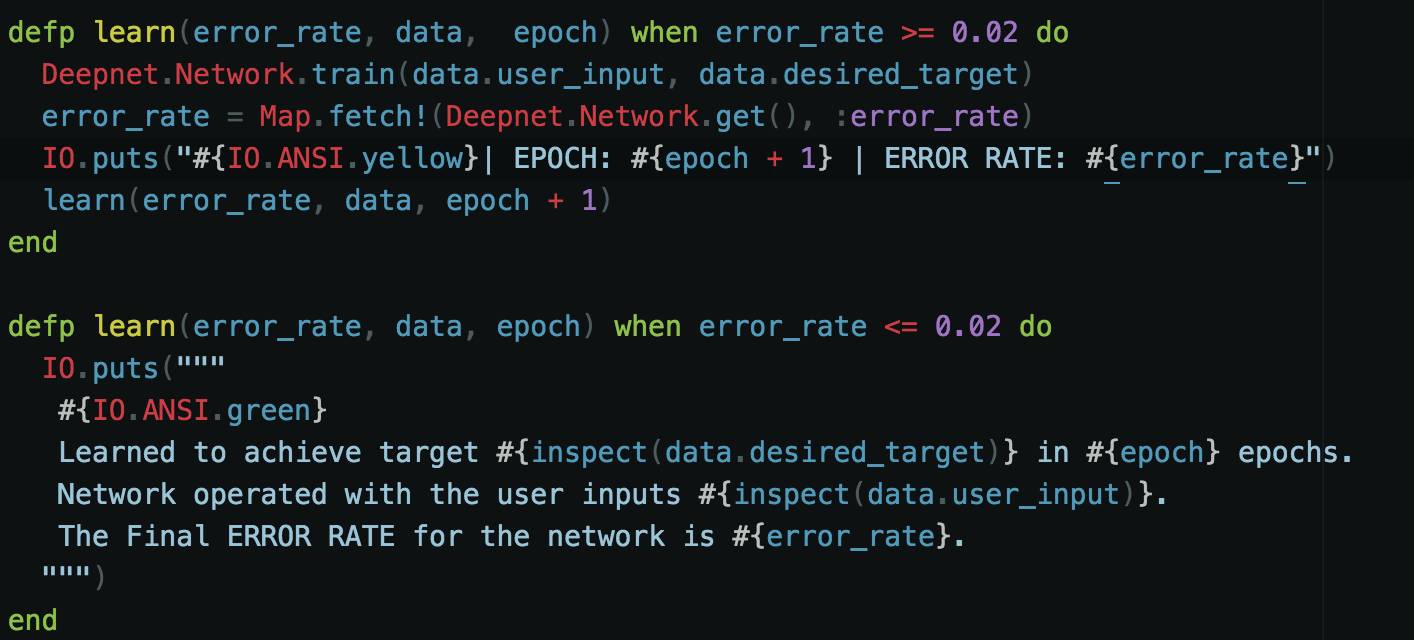
第一个学习函数接收网络的错误率、用户数据和 epoch。epoch 是神经网络迭代一次的周期。你可以认为一个 epoch 就是一个网络的时间长。此函数仅在我们的错误率高于 0.02 时被调用。调用该函数将向系统表明它需要更多的训练。每次训练循环后 epoch 的数值增加 1。如果错误率小于 0.02,则提取错误率并传入最终的学习函数。如果不是,我们称它为当前的学习函数。
第二个学习函数采用相同的参数,但它被当作停止函数(stopping function)。当训练完成并且达到可以接受的错误率时使用此函数。它表明我们的系统已经完全训练了数据集,并准备好进行测试。
最后我们需要做的是为我们的用户输入和目标创建数据结构(data struct)。然后,这个信息将传递给一个能够启动整个过程的学习函数。
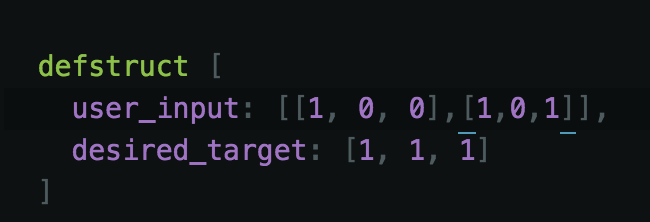
我们原始的数据表定义为一个结构。
现在我们通过最终函数来启动整个过程:
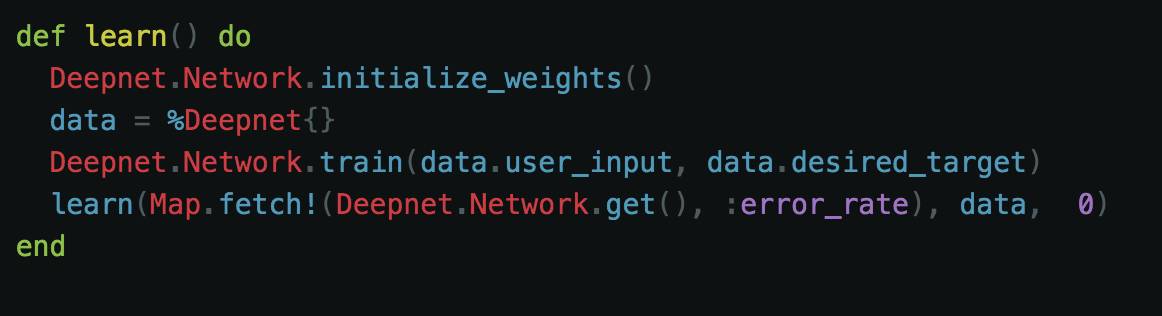
这里我们初始化随机权重,并将我们的用户数据和我们想要的目标传递给网络。接下来,我们通过传入错误率、用户数据和我们网络的 epoch(第一次启动的初始值为 0)来调用我们的学习函数。
现在,我们的网络已经完全建成了。当我们启动程序时会发生什么?
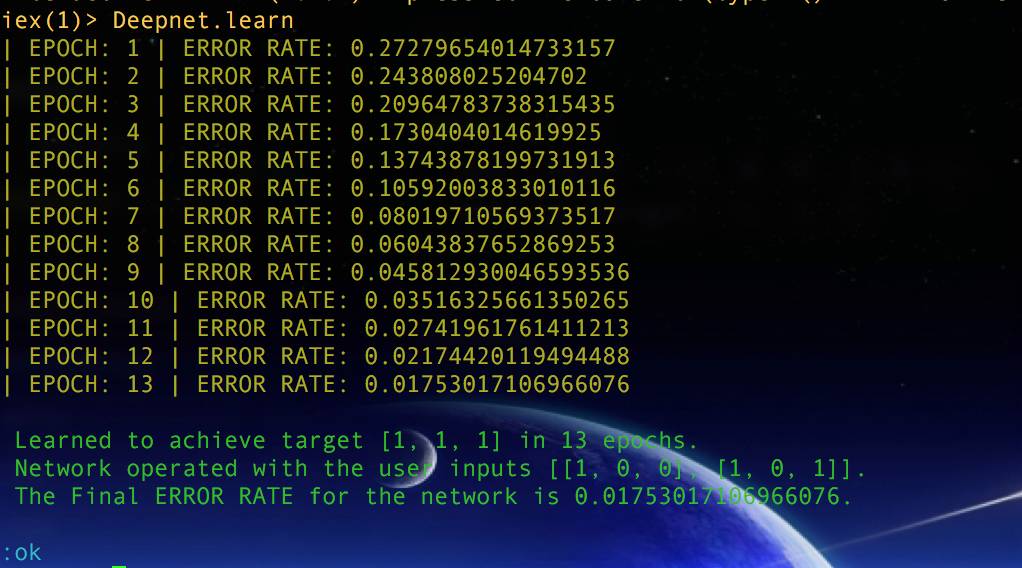
成了!我们可以看到用了 13 个 epoch 来完成训练。我们的网络终于达到我们的目标列表 [1,1,1],并且有低于 0.02 的错误率!这非常令人吃惊。
结论
你可能会想,这有什么意义?如何在实际中使用它?机器学习的重要性对于下一个技术时代是至关重要的,它允许工程师处理大量的数据,同时训练系统来得到洞察或预测结果,并解决我们可能无法得到线索的问题。正如我们刚才见到的,我们可以看到这些系统如何擅长最小化错误,这在现实中是无价的。
神经网络的美丽之处在于,我们可以用不同的方式构建它们,在我们的软件系统中创建类似人类的智能。在本文中,我们没有介绍所有的算法和这些网络架构不同的方式。未来的自动化目标是继续为 Elixir 社区提供如何使用神经网络解决各种各样的问题的精彩例子。
现在我们知道如何设计一个基本的多层神经网络,我们可以应用到一些真正自动化软件系统的优秀的案例项目,以便学习和解决我们未来遇到的不同类型的问题。我将相关 Deepnet 代码放在了 GitHub 上,有兴趣可以查阅 https://github.com/TheQuengineer/deepnet。你可以 fork、实验和更改代码。这个帖子可以作为 Elixir 社区的一个例子,作为从头开始学习设计深度学习网络的一种方式!

原文链接:http://www.automatingthefuture.com/blog/2017/2/20/deep-learning-building-and-training-a-multi-layered-neural-network-in-elixir
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




