一文梳理推荐系统中的多任务学习
© 作者|杨晨
机构|中国人民大学
研究方向|推荐系统
本文聚焦推荐系统中的一个研究方向 —— Multi-Task Recommendation,整理近五年内的研究工作,进行分类总结,并针对22年最新相关论文进行精读,不足之处还望大家进行批评和指正。(更加详细的论文列表可参照 https://github.com/flust/MTL-Rec-paper_list)
1. 什么是多任务学习 (Multi-Task Learning)
2. 与其他学习范式的区别和联系
参考论文[1],MTL与机器学习中的其他几种学习范式具有一定的相关性,比如 transfer learning,multi-label learning 和 multi-view learning,他们之间也有一些核心的区别。
2.1 MTL vs. transfer learning
在多任务学习中,各项任务的地位没有显著差异,知识流向为各任务之间相互流动,最终目标为提高所有任务的效果。而在迁移学习中,最终目标是提高目标任务的效果,源任务只是用来提供信息和知识,知识单方向从源任务流向目标任务。
2.2 MTL vs. multi-label learning
在多标签学习中,每个数据与多个标签相关联,如果把每个标签都当成一个任务,那么其可以一定程度上看作多任务学习,多标签学习在训练和测试阶段共享同样的数据。而多任务学习中,不同任务的数据可以是不一样的。
2.3 MTL vs. multi-view learning
在多视角学习中,每一条数据都具有不同的视角,不同的视角下具有不同的特征,所有视角下的信息都用来服务于一个最终目标,可以理解为多组特征下的单任务学习。
3. 参数共享方式分类
推荐系统中的MTL面临的主要挑战是 学习不同任务间合适的共享参数,并避免信息负迁移现象。参考论文[8],推荐系统中的MTL按照参数共享方式可以分为以下几类:
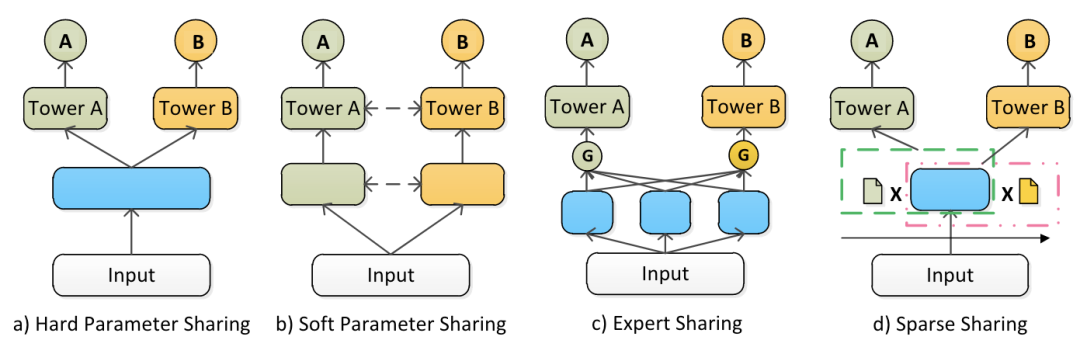
Hard Parameter Sharing:核心思路是所有任务共享同样的底层参数,而顶层的参数相互独立,针对特定的任务独立训练。这种共享方式对于高相关度的任务表现更有效。[2][4]
Soft Parameter Sharing:并不强制要求每个任务共享同样的网络参数,每个任务通过一个独立的模型进行优化,除此之外,每个模型可以获取其他模型的信息。这种方式对于相关性小的任务表现更好。[9]
Expert Parameter Sharing:MoE网络通过一个控制激活模块来组合多个专家模块,MMoE方法进一步被提出针对特定的任务采取不同的控制激活。可以对每个任务使用同一个模型而不是不同模型。[6][7]
Sparse Sharing:自动提取任务子网,子网部分重叠,首先通过训练去决定哪些参数进行共享,然后针对固定好的共享部分进行训练。需要两阶段训练,不够高效。[5]
4. MTL in Recommendation
作为一个应用性很强的研究领域,推荐系统中很自然的有多种任务存在,多任务学习 (MTL) 被广泛应用在现实的推荐系统中,去预测不同类型的用户反馈及其他任务。下面按照任务的不同对近五年的MTL推荐系统论文进行分类整理并对其研究方向和内容进行简要概括,更加详细的论文列表可以参考github库。(各类别下按照时间顺序排序)
4.1 准确性与可解释性
Why I like it: multi-task learning for recommendation and explanation. RecSys 2018
分别使用矩阵分解与生成对抗模型进行评分预测和评论生成,共享用户和物品向量。
Explainable recommendation via multi-task learning in opinionated text data. SIGIR 2018
使用多个张量分解进行偏好预测和观点生成,共享用户、物品、特征和观点向量。
Co-attentive multi-task learning for explainable recommendation. IJCAI 2019
设计了一个编码-选择-解码器结构和一个分层注意力选择器做评分预测和评论生成。
4.2 多种用户行为
Rank and rate: multi-task learning for recommender systems. RecSys 2018
将排名和打分视作一个事件的两个阶段,先预测排序,再预测打分。
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. KDD 2018
MMoE,跨任务共享专家子模型,通过门控网络对每个任务进行优化。
Multiple relational attention network for multi-task learning. SIGKDD 2019
基于attention机制建立三种关系模式:任务-任务 / 特征-特征 / 特征-任务。
Recommending what video to watch next: a multi-task ranking system. RecSys 2019
架构为 Wide & Deep,利用 MMoE 进行两任务部分参数共享。
Predicting different types of conversions with multi-task learning in online advertising. SIGKDD 2019
架构为 FwFM 因子分解机,模型共享特征向量,针对任务增加特定参数并分别优化。
Cross-Task Knowledge Distillation in Multi-Task Recommendation. AAAI 2022
对所有任务两两分组进行任务增强,利用增强后的任务进行知识蒸馏。
MetaBalance: Improving Multi-Task Recommendations via Adapting Gradient Magnitudes of Auxiliary Tasks. WWW 2022
控制不同任务的梯度下降幅度以更好服务于目标任务。
4.3 CTR CVR
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. SIGIR 2018
提出新任务CTCVR,构建全空间多任务模型,解决选择偏差(训练CVR只在点击数据上进行)问题。
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. RecSys 2020
在MMoE的基础上,显式区分共享和任务特有expert,缓解多任务学习的跷跷板问题。
LT4REC: A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System. arxiv 2021
首次提出在神经元粒度上的参数共享方式。
A Contrastive Sharing Model for Multi-Task Recommendation. WWW 2022
在神经元粒度上进行参数共享,通过对比学习提升掩码下子网络的学习效果。
5. 最新研究进展精读
5.1 A Contrastive Sharing Model for Multi-Task Recommendation. WWW 22
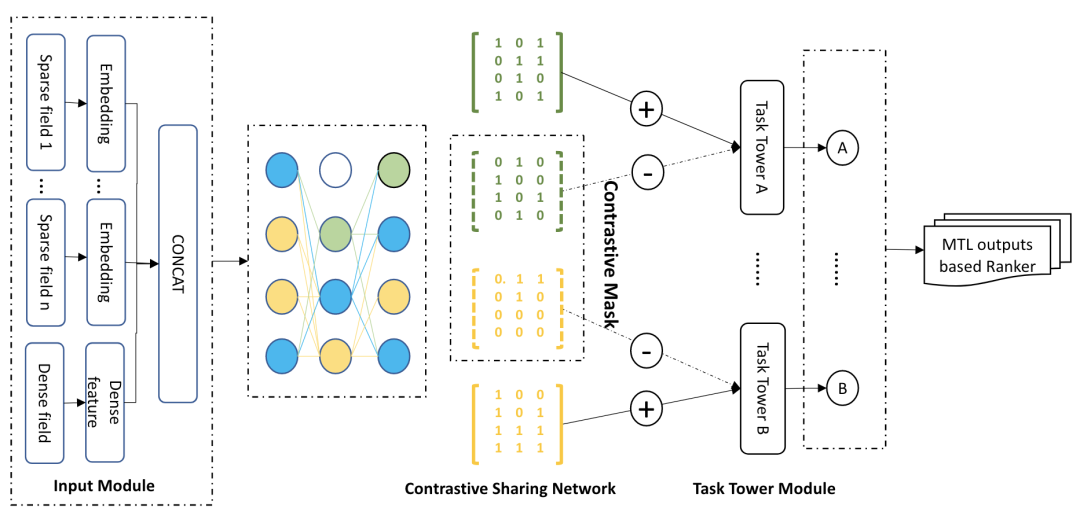
Motivation:不同任务之间会引入噪声,造成 Negative transfer 问题
Main idea:检测每个参数对于每个任务的影响程度,参数根据受影响大的任务更新
Model: 对比共享网络 (Contrastive Sharing Network),输入输出部分很容易理解不做解释,网络结构为多层MLP,核心在于对于每个任务,设置一个可学习的参数掩码,其作用为对网络结构进行mask,最终不同任务的网络结构因此不同。
参数掩码更新:随机初始化,然后不断进行剪枝操作。
对比损失:初始设定好的子网为正,生成多个负子网,在子网层面构建 pairwise 损失函数,有点像网络结构层面的数据增强。
(ps:有点像对每个任务固定一个dropout,利用它设计一些自监督信号来增强模型效果)
5.2 MetaBalance: Improving Multi-Task Recommendations via Adapting Gradient Magnitudes of Auxiliary Tasks. WWW 22
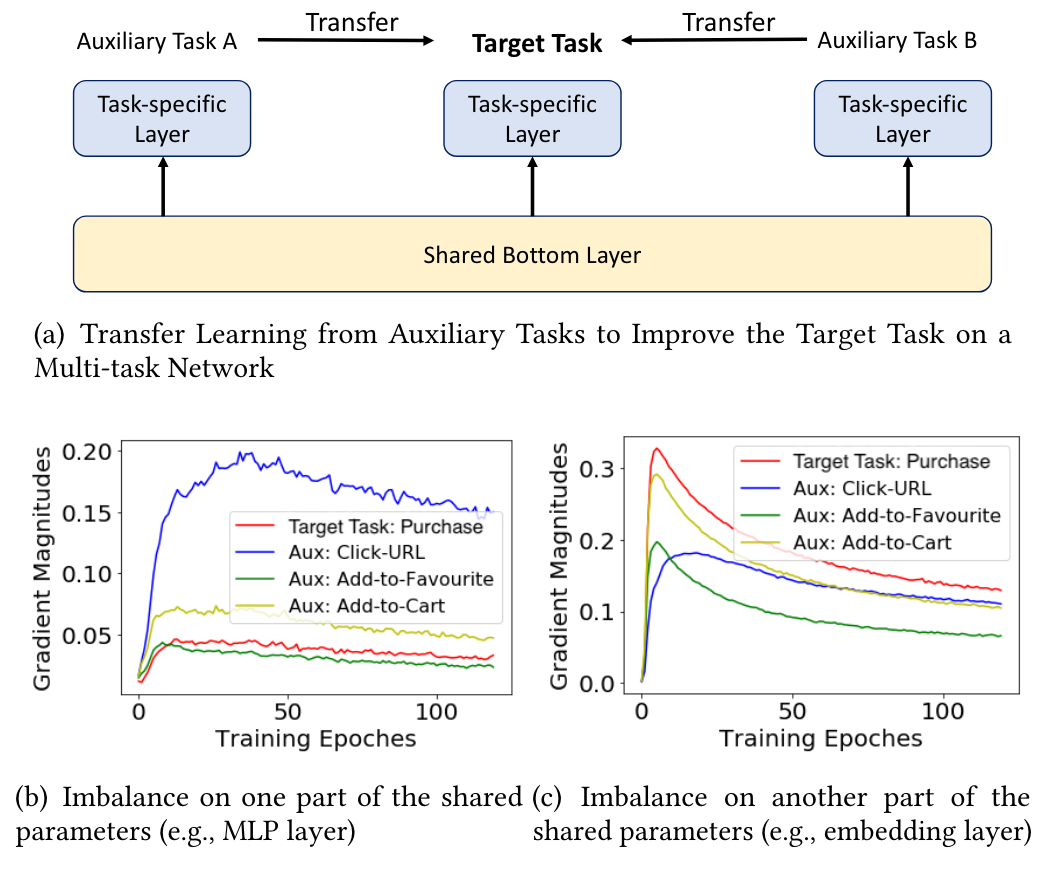
Motivation:目前利用辅助任务的方法会导致优化不平衡问题(有些梯度大,有些梯度小)。
Main idea:控制不同任务的梯度下降幅度以更好服务于目标任务。
Model:提供了一个灵活的框架,从梯度幅度的角度更好地改进目标任务。
强化目标任务的主导地位:减小过大的辅助梯度
增强弱辅助任务的知识传递:放大过小的辅助梯度
通过一个松弛因子灵活控制。
(ps:其最终只关注目标任务,严格来讲是 transfer learning,而不是MTL)
5.3 Cross-Task Knowledge Distillation in Multi-Task Recommendation. AAAI 22
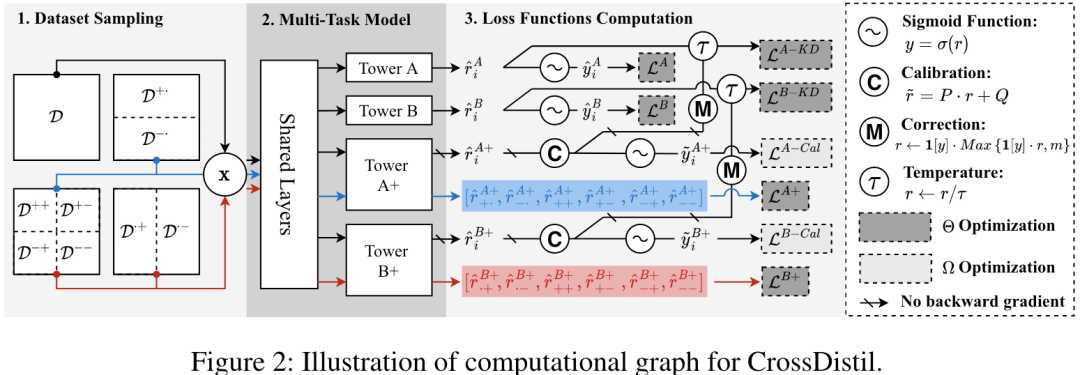
Motivation:现有的多任务学习算法效果不足(某任务中真实标签相同的物品不能准确排序),"Buy:0, Like:1"和"Buy:0, Like:0",只看 Buy 任务的标签,二者一样,但前者应该排序更靠前。
Main idea:利用其他任务中的信息指导目标任务的学习。
Model:包括三部分:1.任务增强,2.知识蒸馏,3.训练和纠错机制。利用两个任务设计新任务,将新任务视为teacher,以此进行知识传递。
任务增强:先将多个任务(均为二分类任务)两两分组,每个样本两个标签,此时样本可以标记为++/+-/-+/--。考虑第一个标签,则存在偏序关系 ++ > +- > -+ > --。对于第二个标签同理。此时,每两个任务即可构造两个增强任务。(如图中利用A和B任务构造任务A+和B+)
对于teacher模型:在增强任务上利用偏序关系构造 pairwise 损失。
对于student模型:知识蒸馏,利用增强后的任务学习出的teacher模型标签训练student模型,例如图中,利用 Tower A+ 的预测值训练 Tower A。
训练:参数分为两类(图中深灰色和浅灰色),每次迭代交替训练。
(ps:原文评测指标是auc,没有做评分融合,实际应用场景下大概率需要排序。模型预测 "Buy:1, Like:0" 和 "Buy:0, Like:1",如何排序这个问题依然没有解决)
部分参考文献
[1] A Survey on Multi-Task Learning TKDE 2021
[2] Why I like it: multi-task learning for recommendation and explanation. RecSys 2018
[3] Explainable recommendation via multi-task learning in opinionated text data. SIGIR 2018
[4] Recommending what video to watch next: a multitask ranking system. RecSys 2019
[5] Learning Sparse Sharing Architectures for Multiple Tasks. AAAI 2020
[6] Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. RecSys 2020
[7] Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. KDD 2018
[8] A Contrastive Sharing Model for Multi-Task Recommendation WWW 22
[9] Cross-stitch networks for multi-task learning. CVPR 2016
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

