重磅 | PyTorch 0.4.0和官方升级指南来了!

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
作为 Facebook 人工智能团队(FAIR)提供支持的深度学习框架,PyTorch 自 2017 年 1 月推出以来立即成为了一种流行开发工具。其在调试、编译等方面的优势使其受到了学界研究者们的普遍欢迎。这个月月初,Caffe2 代码并入 PyTorch 的消息也在业界引起热烈的讨论。
今天,PyTorch 官方在 GitHub 上重磅发布了 0.4.0 版本,这一次更新从 0.3.1 到 0.4.0 有非常多的改进,最重要的就是, PyTorch 现在正式支持 Windows! 在没有官方支持前,广大炼丹师们在 Windows 上安装 PyTorch 需要借助其它开发者发布的第三方 Conda 包,现在官方为 Python 3.5 和 3.6 提供预编译的 Conda 二进制文件和 pip wheels。不过 Windows 上的 PyTorch 不支持分布式训练,可能比 Linux/OSX 慢一点,因为 Visual Studio 支持较早版本的 OpenMP。
与往常一样,你可以使用 http://pytorch.org 上的命令在 Windows 上安装 PyTorch。
这里有一个常见问题解答,可以解答你在 Windows 上可能遇到的大多数问题:
http://pytorch.org/docs/stable/notes/windows.html
除了 Windows 支持外,0.4.0 版的 PyTorch 还重点权衡了计算中的内存、支持多种概率分布、优化数据类型和修正张量等。
以下为本次版本更新目录:
Tensor/Variable 合并
零维张量
数据类型
迁移指南
Tensors:
全面支持高级索引
快速傅立叶变换
神经网络:
计算时的存储权衡
bottleneck,识别代码中热点(hotspots)的工具
torch.distributions
24 个基础的概率分布
增加 cdf、方差、信息熵、困惑度等
分布式训练
易于使用的 Launcher utility
NCCL2 后端
C++ 拓展
Windows 支持
ONNX 改进
RNN 支持
为了帮助老版本用户更轻松地将代码转换为新的 API 和 Style,也为了吸引更多的新用户,PyTorch 团队还编写了一份迁移指南。AI 前线对该迁移指南完整编译如下,如果你想要快速升级以前版本的 PyTorch 代码,请接着往下看!
PyTorch 0.4.0 带来了很多令人兴奋的新特性和一些重要的 Bug 修复,旨在为用户提供更好、更干净的接口。在这篇升级指南中,我们将介绍在从旧版本 PyTorch 升级到最新版本时需要做出哪些重要的改动:
Tensor 和 Variable 已合并
支持零维度(标量)Tensor
弃用 volatile 标志
dtype、device 和 Numpy 风格的 Tensor 创建函数
编写具有设备无关性的代码
torch.Tensor 和 torch.autograd.Variable 现在合并到同一个类中。更确切地说,torch.Tensor 可用于跟踪历史,并具有与旧 Variable 一样的行为。Variable 基本不变,只是返回类型变成了 torch.Tensor。这意味着我们不再需要在代码中使用 Variable 包装器。
需要注意的是,Tensor 的 type() 无法反映出数据类型,可使用 isinstance() 或 x.type() 代替:

requires_grad 是 autograd 的主要标志,现在变成 Tensor 的一个属性。之前用于 Variables 的规则同样适用于 Tensor。只要某个操作的输入 Tensor 包含了 require_grad=True 时,autograd 就会开始跟踪历史记录。例如:

除了可以直接设置这个属性之外,还可以通过 my_tensor.requires_grad_() 来就地更改这个标志,或者如上例所示,在创建 Tensor 时将它作为参数传递进去(默认为 False),例如:

.data 是从 Variable 中获取底层 Tensor 的主要方式。在合并后,仍然可以继续使用 y=x.data 这种方式,它的语义保持不变。所以,y 是一个与 x 共享相同数据的 Tensor,与 x 的计算历史无关,并且它的 requires_grad 值为 False。
但是,在某些情况下,.data 可能不安全。对 x.data 的任何更改都不会被 autograd 跟踪到,如果在逆推中需要用到 x,那么计算出的梯度可能不正确。更安全的方法是使用 x.detach(),它会返回一个共享数据的 Tensor(requires_grad=False),但如果在逆推中需要用到 x,autograd 将会跟踪到它的变化。
之前,索引一个 Tensor 向量(1 维 Tensor)会得到一个 Python 数字,而索引一个 Variable 向量会得到(有时候也不一定)一个大小为(1,)的向量!reduction 函数也存在类似的情况,例如 tensor.sum() 将返回一个 Python 数字,但是 variable.sum() 会返回一个大小为(1,)的向量。
幸运的是,新版本适当引入了对标量(0 维 Tensor)的支持!可以使用新的 torch.tensor 函数来创建标量(这将在后面更详细地解释)。现在我们可以做这样的事情:

以广泛使用的模式 total_loss+=loss.data [0] 为例,在 0.4.0 之前,损失是一个 Variable,包装了大小为(1,)的 Tensor,而在 0.4.0 中,损失是一个零维度的标量。索引标量是没有意义的(现在会给出一个警告,但在 0.5.0 中将变成一个错误)。我们可以使用 loss.item() 从标量中获取 Python 数字。
请注意,如果在累积损失时未将其转换为 Python 数字,可能会消耗大量内存。这是因为上面表达式的右侧之前是一个 Python 浮点数,而现在变成了一个零维度的 Tensor。因此,总损失是 Tensor 和它们的梯度历史累积起来的,这可能会使 autograd 图保留更长的时间。
volatile 标志现在已经被弃用。之前,autograd 不会跟踪任何包含 volatile=True 的 Variable 计算。现在可以通过一组更灵活的上下文管理器来实现相同的功能,包括 torch.no_grad()、torch.set_grad_enabled(grad_mode)等。

在以前的版本中,我们需要指定数据类型(float 还是 double?)、设备类型(cpu 还是 cuda?)和布局(dense 还是 sparse?)作为“Tensor 类型”。例如,torch.cuda.sparse.DoubleTensor 表示驻存在 CUDA 设备上具有 COO sparse 布局的 double 数据类型。
在新版本中,我们引入了 torch.dtype、torch.device 和 torch.layout 类,可通过 NumPy 风格的创建函数更好地管理这些属性。
torch.dtype
以下是可用的 torch.dtype(数据类型)及其相应 Tensor 类型的完整列表。
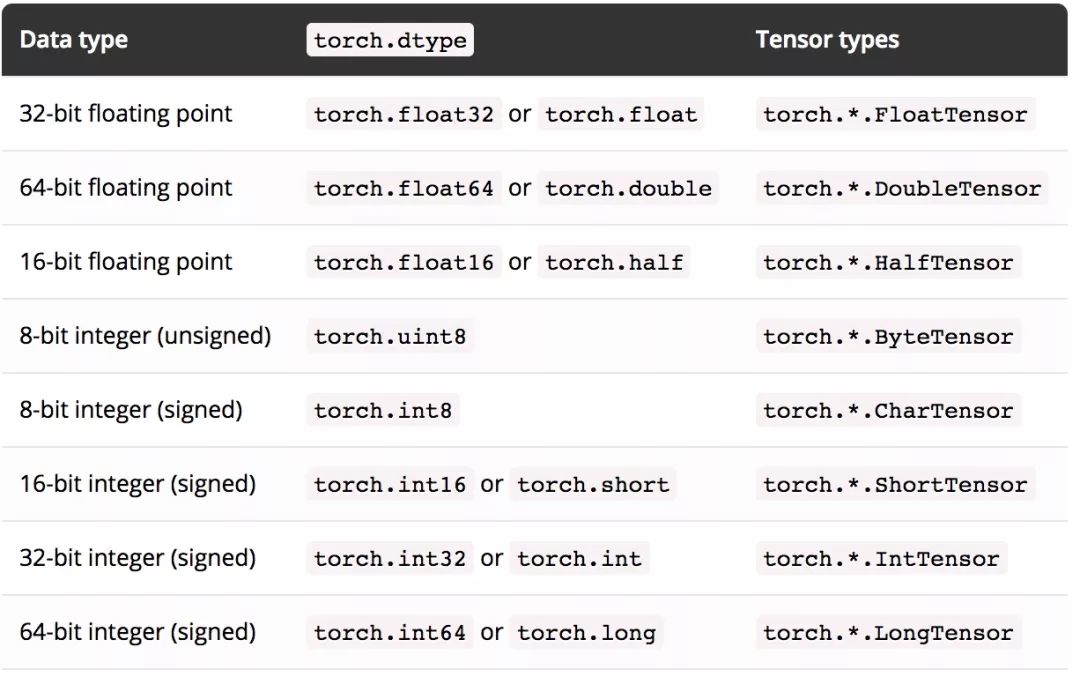
现在可以通过访问 Tensor 的 dtype 属性获取到它的 dtype 数据类型。
torch.device
torch.device 包含设备类型(cpu 或 cuda)和可选的设备序号(id)。它可以通过 torch.device('{device_type}')或 torch.device('{device_type}:{device_ordinal}')进行初始化。
如果设备序号不存在,则表示是当前设备。例如,torch.device(’cuda')等同于 torch.device('cuda:X'),其中 X 是 torch.cuda.current_device() 返回的结果。
现在可以通过访问 Tensor 的 device 属性获取它的设备类型。
torch.layout
torch.layout 表示 Tensor 的数据布局,目前可以支持 Currentlytorch.strided(密集 Tensor,默认值)和 torch.sparse_coo(具有 COO 格式的稀疏 Tensor)。
现在可以通过访问 Tensor 的 layout 属性获取它的数据布局。
现在在创建 Tensor 时还可以通过指定 Tensor 的 dtype、device、layout 和 requires_grad 选项。例如:

torch.tensor(data, ...)
torch.tensor 是新引入的一个 Tensor 创建方法,将各种数组风格的数据复制到新 Tensor 中。如前所述,torch.tensor 等同于 NumPy 的 numpy.array 构造函数。与 torch*Tensor 创建方法不同的是,我们可以通过这种方式创建零维度 Tensor(也称为标量)。而且,如果没有给出 dtype 参数,它会推断出合适的 dtype。在基于已有数据(如 Python 列表)创建 Tensor 时,我们推荐使用这种方法。例如:

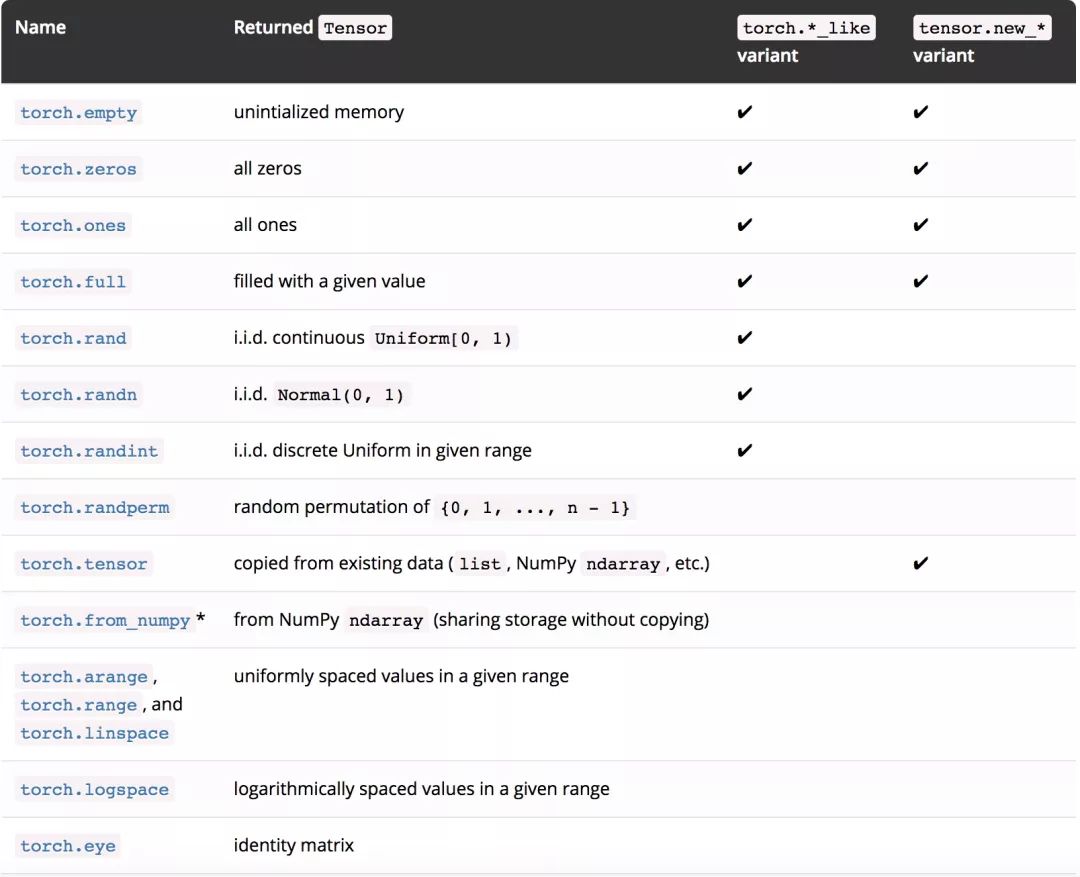
我们还添加了更多创建 Tensor 的方法,其中一些还具有 torch.*_like 和 tensor.new_ * 的变种。
1.torch.*_like 接收 Tensor 作为输入,而不是 shape。 除非另有说明,否则它默认返回一个与输入 Tensor 具有相同属性的 Tensor:

2.tensor.new_ * 也可以用于创建与 tensor 具有相同属性的 Tensor,但它需要一个 shape 输入参数:

在大多数情况下,如果要指定 shape,可以使用元组(例如 torch.zeros((2,3)))或可变参数(例如 torch.zeros(2,3))。
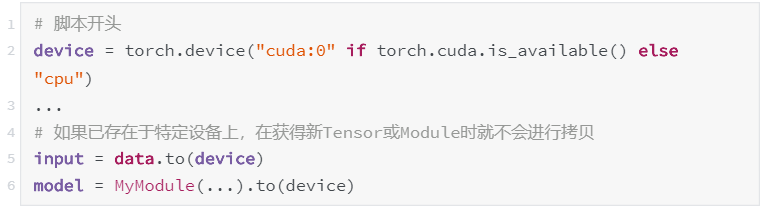
在之前的版本中,编写具有设备无关性的代码十分困难(设备无关性是指在不需要做出修改的情况下可同时运行在 CUDA 和 CPU 设备上)。
PyTorch 0.4.0 通过两种方式实现了设备无关性:
通过 device 属性获得所有 Tensor 的 torch.device(get_device 仅适用于 CUDA Tensor)
Tensor 和 Module 的 to 方法可用于将对象轻松移动到不同的设备(而不必调用 cpu() 或 cuda())
我们推荐以下这种方式:
为了了解 0.4.0 的整体变化,我们通过常见代码的示例来比较 0.3.1 和 0.4.0 的不同:
0.3.1(旧版本)

0.4.0(新版本)

迁移指南原文:
http://pytorch.org/2018/04/22/0_4_0-migration-guide.html
关于新版本的更多更新细节,请参考 PyTorch 的 GitHub 页面:
https://github.com/pytorch/pytorch/releases/tag/v0.4.0
今日荐文
点击下方图片即可阅读

中兴遭封杀 1周盘点:中美贸易战没有赢家!
如果你对人工智能感兴趣,推荐关注《AI技术内参》。用一年时间,为你精讲人工智能国际顶级学术会议核心论文,系统剖析人工智能核心技术,解读技术发展前沿与最新研究成果,分享数据科学家以及数据科学团队的养成秘笈。
新注册用户,立减 30元。欢迎点击图片试读。

点「阅读原文」,免费试读或订阅。


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!




