干货|从Facebook AI Research开源fastText谈起文本分类:词向量模性、深度表征和全连接

来源:云栖社区
摘要:本文主要介绍了Facebook AI Research在16年开源的一个文本分类器fastText,并从深度学习的角度:词向量模型(Embedding)、深度表征(Deep representation)和全连接(Fully connected part)介绍文本分类方法。
文本分类(text classification)是机器学习的一个主要任务,通常用作垃圾邮件检测、新闻/文章主题生成、多义词正确词义选择等。之前,Statsbot团队已经分享了《如何检测垃圾邮件/信息/用户评论》https://blog.statsbot.co/data-scientist-resume-projects-806a74388ae6?spm=5176.100239.blogcont128589.12.qKLMek&utm_source=blog&utm_medium=post&utm_campaign=text_classifier。本文主要介绍少数几个广义上的文本分类算法及相关案例,同时也提供了一些有用的教程和工具。
文本分类基准(Benchmarks)
目前,搞文本挖掘的人通常会使用很多小技巧和工具,比如TF-IDF特征,线性SVM(Linear SVMs)和词向量模型(如word2vec),然后在一些有名的数据集上,就同一问题,比较自己的方法和别的方法孰优孰劣。比如下面这些有名的用于文本分类的语料库:
AG’s news articles
Sogou news corpora
Amazon Review Full
Amazon Review Polarity
DBPedia
Yahoo AnswersYelp
Review Full
Yelp Review Polarity
传送门:下载地址(需翻墙)
https://drive.google.com/drive/folders/0Bz8a_Dbh9Qhbfll6bVpmNUtUcFdjYmF2SEpmZUZUcVNiMUw1TWN6RDV3a0JHT3kxLVhVR2M?spm=5176.100239.blogcont128589.13.qKLMek
深度学习VS.浅层学习(shallow learning)
简单和复杂模型在这些数据集上都能表现的很好。为了说明这一点,请参考下面两篇论文:
Character-level Convolutional Networks for Text Classification by Yann LeCun et al
https://arxiv.org/abs/1509.01626?spm=5176.100239.blogcont128589.14.qKLMek&file=1509.01626
A Bag of Tricks for Efficient Text Classification by Tomas Mikolov et al
https://arxiv.org/abs/1607.01759?spm=5176.100239.blogcont128589.15.qKLMek&file=1607.01759
两篇论文采用了相同的数据集,实验结果在准确度(precision)方面大致相等。但是训练时间却相差甚远。第一篇文章中的模型如图1所示,它需要花费数小时训练,而第二个型中提出的fastText模型(和word2vec中的CBOW架构类似,因为作者都是Facebook科学技术Tomas Mikolov,如图3所示)如图2所示,却只需要几秒。
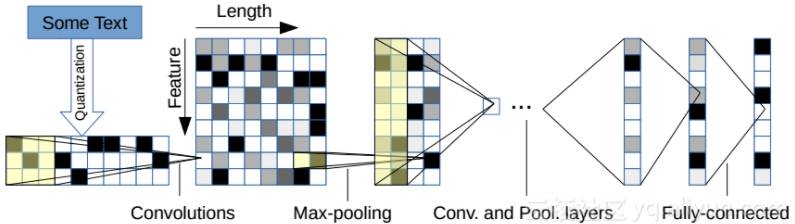
图1. 论文1模型架构
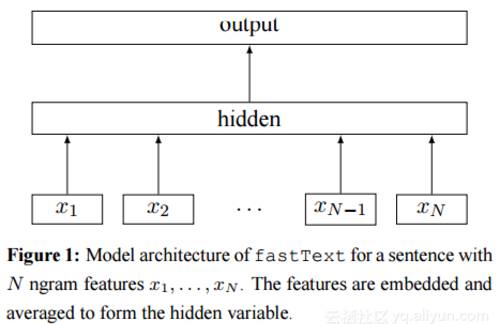
图2. 论文2模型架构
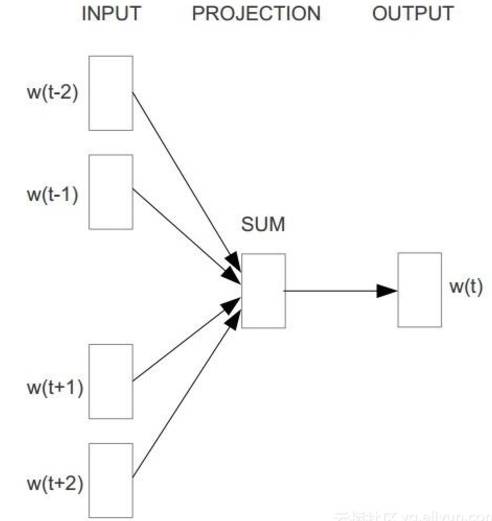
图3. CBOW架构
第二篇论文中的更轻量级的模型fastText不需要GPU加速,在单颗CPU上运算更快。与“深层”的CNN模型相比,fastText的模型结构是“浅层”的。它由一个联合向量层(joint embedding layer)和一个softmax分类器组成,原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接入softmax 层。
如果你有仔细注意过Kaggle比赛中一些获胜方案的话,你会发现复杂的集成类方法占据主导地位。比如最近的 Quora Question Pairs competition:https://www.kaggle.com/c/quora-question-pairs?spm=5176.100239.blogcont128589.16.qKLMek和 DeepHack.Turing:https://inclass.kaggle.com/c/human-or-machine-generated-text?spm=5176.100239.blogcont128589.17.qKLMek,其中顶级的方案总是由不同的模型组成:梯度提升方法,RNNs和CNNs。
基于神经网络的文本分类器通常包含相同的线性元结构:词向量模型(Embedding)、深度表征(Deep representation)和全连接(Fully connected part)。
词向量模型
词向量层(Embedding layers)以词序列为输入,输出对应的词向量。这个函数很简单,本文并不关心这些向量的实际语义,剩下的问题就是初始化这些权重的最好方法是什么,如图4所示。
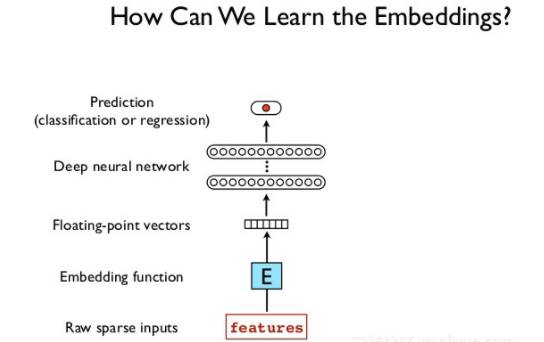
图4. 如何训练词向量
在这个问题中,答案可能和直觉思维“先人工生成标签,然后用word2vec训练,再用来初始化词向量层”相反。但是考虑到实际目标,你可以在具体的模型中使用预训练(pre-trained)的词向量集合并不断调整(fine-tune)它。很可能最后的词向量并不会表现出和普通的word2vec模型同样的效果:
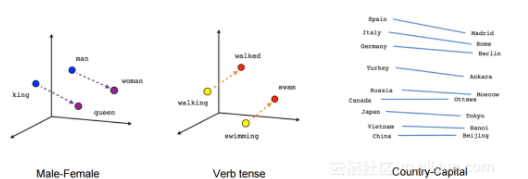
图5. 根据词向量得到的词之间的关系
但在这个案例中这并不是重点,关键在于使用预训练的word2vec词嵌入模型,并且在嵌入层使用更低的学习率(一般的学习率乘以0.1)。
深度表征
深度表征(deep representation)部分的主要目的是在输出中压缩(condense)所有相关信息,同时禁止(suppressing)导致识别出单个样本的部分。因为大容量的网络有可能会在某些样本上过拟合,在测试集上表现很差。
循环神经网络(Recurrent neural network,RNN)
当问题变成预测给定文档是否是垃圾文档时,最简单可靠的架构是应用于循环网络隐状态的多层全连接文本分类器(multilayer fully connected text classifier)。这个状态的语义被认为是不相关的,且整个向量被看作是文本的一种压缩描述。
下面是一些有用的资源:
how to use LSTMs for text classification
http://deeplearning.net/tutorial/lstm.html?spm=5176.100239.blogcont128589.20.qKLMek
LSTM Tutorial for PyTorch
http://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html?spm=5176.100239.blogcont128589.21.qKLMek
Understanding LSTM Networks by Chris Olah
http://colah.github.io/posts/2015-08-Understanding-LSTMs/?spm=5176.100239.blogcont128589.22.qKLMek
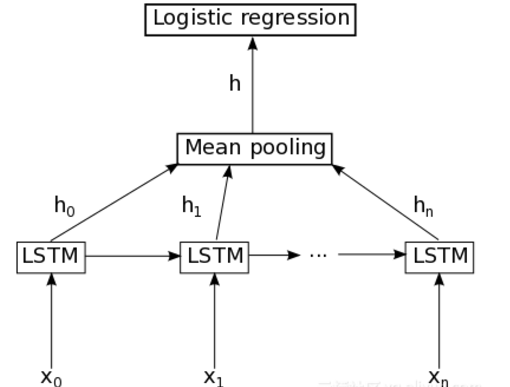
图6. 基于RNN的分类器基础结构
如图6所示,其原理在于:每个word经过词向量表示之后,进入LSTM层,这里LSTM是标准的LSTM,然后经过一个时间序列得到的n个隐藏LSTM神经单元的向量,这些向量经过mean pooling层之后,可以得到一个向量h,然后紧接着是一个简单的logistic回归层(或者一个softmax层)得到一个类别分布向量。
由于主要工作都是在在循环层(recurrent layer)进行,确保它仅捕获到相关信息相当重要。在高层要做两件事情:
使用双向LSTM(Bidirectional LSTMs)。这是一个很好的主意,因为他可以捕获每个词的上下文,而不只是按顺序“阅读”;
为词向量使用过渡层(transitional layer)。LSTMs学会区分一个序列重要和不重要的部分,但我们并不能确定来自词向量层的表征是否是最好的输入,特别是当我们并没有调整词向量的时候。给每个词向量添加独立的一层可以提高你的结果,就像一个简单的attention 层。
卷积神经网络(Convolutional neural network,CNN)
一种可替代的方法是使用卷积网络训练深度文本分类器。通常,给定一个足够大的感受野(卷积神经网络的每一层输出的特征图(Feature map)上的像素点在原图像上映射的区域大小),你可以得到和使用attention层相同的结果。如图7所示,开始会保持大量的feature map,然后按指数级减少他们的数量,这将有助于避免学到不相关的模式。
你可以在查看一个基于PyTorch的CNN分类器的简单实现:https://github.com/Shawn1993/cnn-text-classification-pytorch?spm=5176.100239.blogcont128589.24.qKLMek,其中展示了如何用他自己的词向量层训练和评估一个卷积分类器。
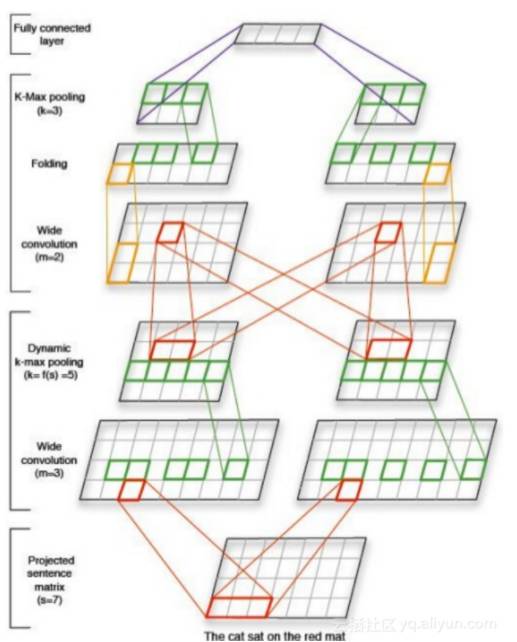
图7. 基于CNN的分类器架构
密集训练器(Dense Classifier)
全连接部分(fully-connected part)在深度表征上进行一系列变化,最后输出每个类的分数。最好的实现就是应用如下变化:
全连接层
批量归一化(Batch normalization)
非线性变化(可选)
Dropout
文中的文本分类算法也可以通过一些复杂的方法增强,这将帮助你构建更好的模型和更快达到收敛。另外下面还有些分类和表征学习的工具。
A collection of tools and implemented ready-to-train text classifiers (PyTorch)
https://github.com/facebookresearch/InferSent?spm=5176.100239.blogcont128589.26.qKLMek
FastText, a library for efficient text classification and building word representations
https://github.com/facebookresearch/fastText?spm=5176.100239.blogcont128589.27.qKLMek
Skip-gram tutorial:
part 1:http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/?spm=5176.100239.blogcont128589.28.qKLMek
part 2:http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/?spm=5176.100239.blogcont128589.29.qKLMek
CNN text classifier in TensorFlow
https://github.com/dennybritz/cnn-text-classification-tf?spm=5176.100239.blogcont128589.30.qKLMek
RNN Sentence classification tutorial in Keras
http://machinelearningmastery.com/sequence-classification-lstm-recurrent-neural-networks-python-keras/?spm=5176.100239.blogcont128589.31.qKLMek







