EMNLP2021 | 东北大学提出:一种基于全局特征的新型表填充关系三元组抽取模型

作者 | 张龙辉
论文链接:https://arxiv.org/pdf/2109.06705.pdf
作者简介:张龙辉,共同一作。目前为东北大学知识图谱研究小组的在读硕士,导师是任飞亮老师。在EMNLP,CIKM,NLPCC均有论文发表。研究领域为信息抽取。
个人主页:https://zlh-source.github.io/
导师主页:http://faculty.neu.edu.cn/renfeiliang
基于表填充的关系三元组抽取方法由于其良好的性能和从句子中提取复杂三元组的优秀能力而受到越来越多的研究者关注。然而,这类方法远远没有发挥其全部潜力,因为它们大多只关注局部特征,而忽略了三元组间的全局关联,这使得模型在三元组抽取过程中会忽略某些重要信息。为了克服这一缺陷,我们提出了一种基于全局特征的关系三元组抽取模型,该模型可以充分捕获三元组间的全局特征。
具体而言,我们首先为每个关系生成一个与之对应的表特征。接着,我们将从这些表特征中挖掘关系间的全局交互特征、以及token pairs之间的全局交互特征。下一步,这两类全局交互特征将进一步融合到各个关系对应的表特征中。以上“生成—挖掘—融合”的过程会执行多次,以便使每个关系对应的表特征逐步精细化。最后,根据这些表特征,我们可以对每个关系对应的表进行填充,并根据填充结果而得到具有相应关系的各个三元组结果。我们在多个benchmark数据集上对相应方法进行了评估,实验结果显示,我们方法的结果明显优于多个最新三元组抽取方法。
三元组一般以(subject, relation, object)的形式表示客观存在的一个知识。比如,(中国,首都,北京)可以表示“中国的首都是北京”这一事实。在三元组中,subject和object均为实体,relation为关系。相应地,三元组抽取任务是在给定输入文本(一般以句子为单位)的条件下,从中自动地抽取出文本所包含的三元组信息。显然,三元组抽取任务对于知识图谱自动构建等下游任务而言至关重要。
在各类三元组抽取方法中,基于表填充的方法是目前广受关注的一类方法。该类方法的主要特点包括以下两点。
1)在给定输入的条件下,该类方法为每一个关系设定一个对应的表,表的大小为L*L,其中L为输入文本中包含的token数。换句话说,如果预先定义了n个关系,那么,对于每一个输入文本,将会有对应的n个L*L的关系表。
2)关系表中的元素可以称为对应模型所定义的label集,主要用来提示对应的一个token pair所具有的可以提示其是否具有对应关系的各类提示信息。比如,我们可以用”HH”来表示某个token_i和token_j均为对应关系的头实体(即subject实体)中的token。
显然,如果每个关系的对应表信息都可以准确的获得,那么,就可以基于这些表准确地推导出输入文本中所具有的三元组信息。因此,基于表填充的三元组抽取方法的关键是有效地进行关系表填充。
目前,一些基于表填充的方法在多个基线数据集上都取得了SOTA的结果。然而,这些已有方法在进行表填充过程中都是以使用下面两类局部特征为主:
1)在确定某个表元素时,使用该元素所对应的token pair信息;
2)在确定某个表元素时,使用已完成填充的历史表元素信息。
显然,这些方法忽略了token pairs之间的全局关联信息以及关系间的全局关联信息。而这两类全局特征可以较好的揭示关系和token pairs之间的差异,既可以通过多方面相互验证而提高三元组抽取的准确率,又可以通过帮助推导出新的三元组而提高三元组抽取的召回率。
比如,给定输入句子“Edward Thomas and John are from New York City, USA.”,从全局的角度来看,我们可以很容易获得下面两类全局信息。首先,三元组(Edward Thomas, live_in, New York)有助于三元组(John, live_in, USA)的提取,反之亦然。这是因为这两个三元组的(subject, object)对具有类似的属性,均是以(人名,地名)的形式出现,而相同类型的实体对显然更容易具有相同或类似的关系。换句话说,根据三元组中实体对信息的属性可以对获得到的三元组进行进一步的验证以提升准确度。其次,通过上面两个三元组有助于推导出新的三元组(New York, located_in, USA)。这是因为:
(1)locate_in关系要求其对应的两个实体均与locations相关;
(2)locate_in与live_in在语义上具有一定的相关性;
(3)live_in关系要求其对应的object实体为locations。
这样,在已知的两个三元组和未知的三元组之间可以确立一条清晰的推导路径。显然,这两类重要的全局特征信息不可能被现有方法中使用的局部特征所包含。受此启发,本文的方法主要是通过挖掘、使用上面提到的两类全局特征进行三元组抽取。
通过前面的介绍我们可以知道,在基于表填充的三元组抽取模型中,首要任务就是为关系表定义合适的label集,每个label均用来表示一个token pair(这里记为(wi,wj))所在某个关系对应的表中所具有的和三元组相关的某些属性。
在本文中,我们定义的label集为:{"N/A", "MMH", "MMT", "MSH", "MST", "SMH", "SMT", "SS"}。其中标签{"MMH", "MMT", "MSH", "MST", "SMH", "SMT"}等均由三个字母组成,第一个字母为M或S时,代表单词对中wi是subject中的某个单词,并且subject是由多个单词或单个单词组成的实体。第二个字母与第一个字母类似,只是该字母是关于object和wj的相关信息的描述。第三个字母H或T代表该单词对分别是subject和object的开头或结尾。而”SS”标签表示该单词对就是实体对,即为两个实体均只有一个单词。N/A标签即为其它情况。
和已有的表填充方法相比,本文设计的label集的一大特点是可以大幅减少模型需要填充的元素个数(详细情况可以参考论文中对应的分析部分)。
模型结构
我们模型的结构如下图1所示,主要包含4个模块:Encoder模块、表特征生成模块、全局特征挖掘模块、以及三元组生成模块。
给定一个输入句子,我们首先对其进行编码,抽取出句子特征。
之后,句子特征被输入进表特征生成模块中,生成初始的表特征。
接着全局特征挖掘器利用max pooling和transformer进行表格和句子的交互,用以捕获全局特征,并将全局特征和句子特征进行信息融合作为下一次迭代时的句子特征输入进表特征生成模块。至此,整个迭代过程形成了一个闭环。
经过多次迭代后,每个表对应的特征将被逐渐细化,我们依据最后一次迭代生成的表特征使用三元组抽取器进行表填充和表解码以得到最终的三元组结果。
这里,我们忽略了各个模块中的具体过程,读者可通过阅读原文获取详细信息。

图1.模型结构图
表解码策略
对于每一个关系,当完成对其对应的表填充后,需根据填充结果进行解码,以得到具有该关系的三元组结果。当对所有关系的表解码完成后,输入句子所具有的所有三元组信息也相应的获取完成。
在本文中,我们主要通过确定实体对的开始和结束位置来进一步确定所有的关系三元组。同时,为了应对实体嵌套的问题,在该阶段我们设计了三种解码策略:正向搜索,反向搜索和“SS”标签的搜索(分别对应下面图2中的红线,绿线和蓝线)。

图2.表的填充和解码示意图
论文使用NYT29,NYT24和WebNLG数据集进行性能测试。整体实验结果和消融实验结果如表1所示。结果显示,相较于之前的最佳三元组抽取模型,本文提出模型的性能在三个数据集上均有明显提升。其中,在WebNLG上的提升幅度最为明显,我们认为,这主要是因为WebNLG数据集中包含更多种关系,这也意味着三元组之间的全局特征也更多。因而,该数据集可以使我们的方法发挥更大功效。
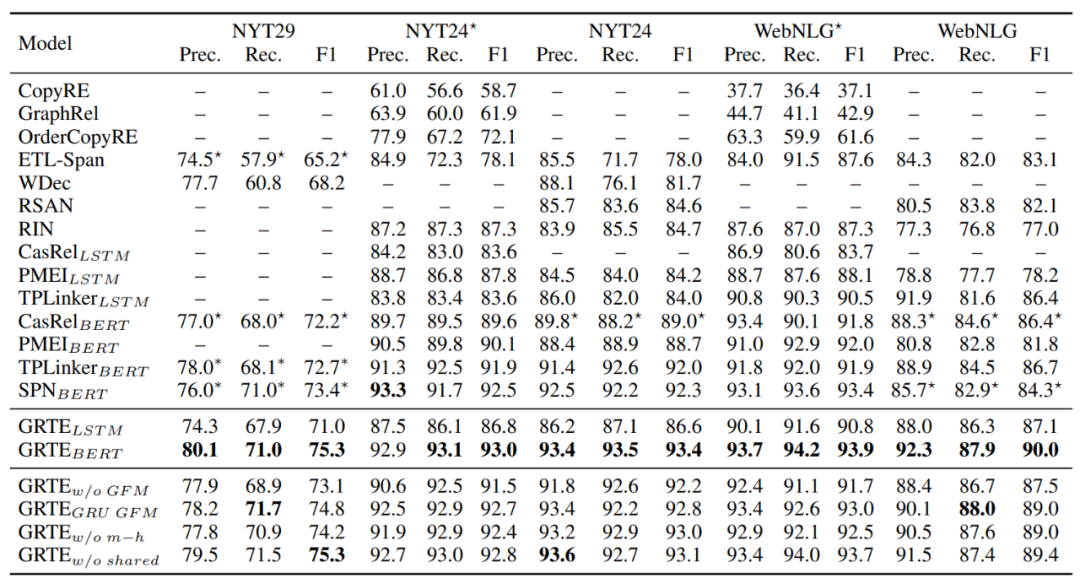
表1.整体实验及消融实验结果
在本文所提的模型中,存在一个迭代过程,因而研究者会担心其效率。为此,我们进行了两部分实验来评估其执行效率。
首先,我们对模型的性能与迭代次数的关联进行了评估,结果如图3所示。从中我们可以发现两个重要的结论。
(1)在一定范围内,随着迭代次数的增多,模型性能也会逐渐上升,并且在模型在迭代两次时,性能涨幅最大,而此时正是全局特征首次参与运算。因此,这个实验结果证明了捕获全局特征的重要性。
(2)通过该实验结果,我们可以清晰的看到,模型仅需迭代较少的次数就可以达到最佳性能。比如,在相对简单的NYT*和WebNLG*数据集上,只需迭代两次即可达到最佳性能;而在其它相对复杂的数据集上,也仅需迭代3、或4次即可得到最佳性能。更重要的是,从中可以看出,即使只迭代2次,本文模型所对应的性能也超过了之前所有的模型。
这些结果显示,本文方法中的迭代环节不会成为模型运行的负担。
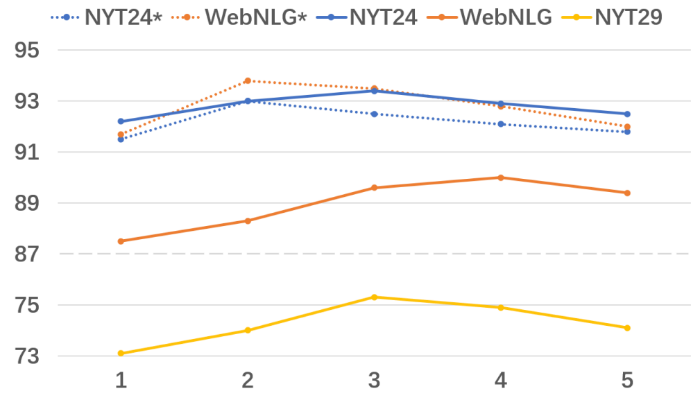
图3.迭代次数与模型性能的关联
首先,我们比较了一些当前最佳模型的参数效率,结果如下表2所示。从中可以看出,与同样使用Transformer的SPN模型相比,我们的模型具有更少的参数。而且,从encoder参数所占的比例来看,我们模型的迭代部分并没有引入更多的参数。因此,从该实验结果我我们可以得出结论,本文所提的模型具有极强的参数效率:可以在较少的参数条件下达到更好的性能。此外,本文模型的另外一个优势在于其可以在较短的时间内完成训练。因为本文模型的epoch设置为50,而其它所有对比模型的epoch均设置为100。而从表2的推导时间可以看出,不同模型的推导时间基本接近。而模型训练时间与推导时间存在一定的正向关联,因而,较少的epoch意味着更快的训练速度。
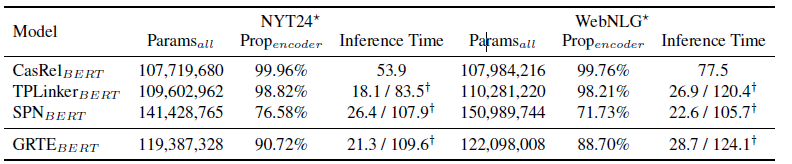
表2.参数效率比较
通过上面两类实验,我们可以得出结论,虽然本文模型中有迭代环节,但并没有因此而导致效率低下,相反,通过有效地进行全局特征挖掘,本文方法可以在较少的迭代次数下获取最佳的实验性能。
在本文中,我们提出一个基于两类全局特征的表填充三元组抽取模型。实验结果显示,这两类全局特征对于提升模型的准确率、召回率均有较大帮助。相应地,本文所提出的模型在多个基线数据集上均取得了最佳性能。并且,本文所提模型还具有参数量适中、参数效率高的特点,是一种高效的三元组抽取模型。
还有疑问?点击视频观看详细讲解:


由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。




