技术详解 | 如何用GAN实现阴影检测和阴影去除?
作者 | 江亦凡
最近两天刚看到的论文,写一篇文章当做笔记,论文原文取自https://arxiv.org/abs/1712.02478
继去年底Phillip Isola, Jun-Yan Zhu等人提出pix2pix框架以来,image translation的应用引起了大家的重点关注,相应的github仓库更是获得了高达4000+的star。至此,GAN在image to image translation, semantic segmentation, image style transfer等众多领域都达到了state-of-the-art的效果,本文介绍的ST-CGAN在pix2pix框架的基础上做出改进,分别构建两个生成器和两个判别器从而实现了阴影检测和阴影去除,与之前的模型相比取得了更好的效果。
生成对抗网络GAN(Generative adversarial network)由Goodfellow于2014年提出,16年DCGAN在图像领域取得了十分惊艳的效果,之后便接连出现GAN的许多变体(pix2pix, WGAN, SRGAN, CycleGAN等等),原始GAN提出了一个minimax game,由生成器不断生成fake data去欺骗判别器,而判别器不断学习如何鉴别fake data和real data,生成器和判别器在不断博弈的过程中互相提升,最终达到收敛。
对GAN(Generative adversarial network)不太了解的同学可以先看看 @郑华滨 写的令人拍案叫绝的Wasserstein GAN,文中描述了原始GAN的发展和问题。
首先让我们先来看一看为什么pix2pix能取得如此惊艳的效果

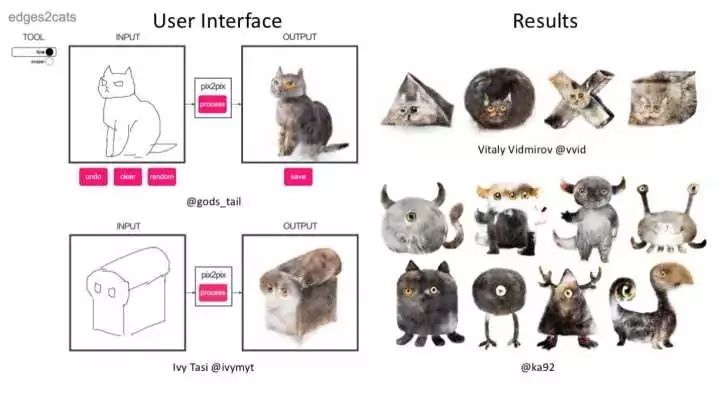
在pix2pix之前已经有许多GAN的变种(DCGAN, CGAN),这些GAN在当时都取得了不错的效果,虽然在某种程度上还存在着不稳定,多样性差,生成图像分辨率不高等问题。博主认为这些GAN的变种是以生成看起来真的图像作为目标,缺乏实际的应用场景。pix2pix模型借用conditional GAN的思想,将整张原图直接输入,并提出了pair的概念,让判别器同时判断两个pair的真假,从而建立了图片与图片之间的联系,实现image-to-image translation。
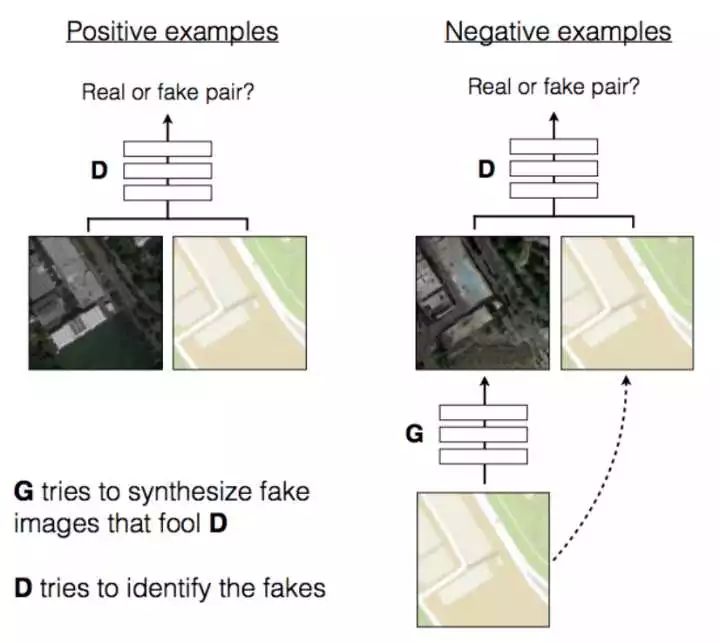
说得更直白一点,pix2pix与之前的GAN最大的区别就在于将一个pair中的两张图一起作为判别器的输入(实现上就是把两个图片叠在一起,channel为6作为输入),这样的结构使得判别器不再是简单地判断图片本身的真与假,而是进一步判断两个图片的对应关系,从而使得生成器生成的图片同时具备真实性和相关性。
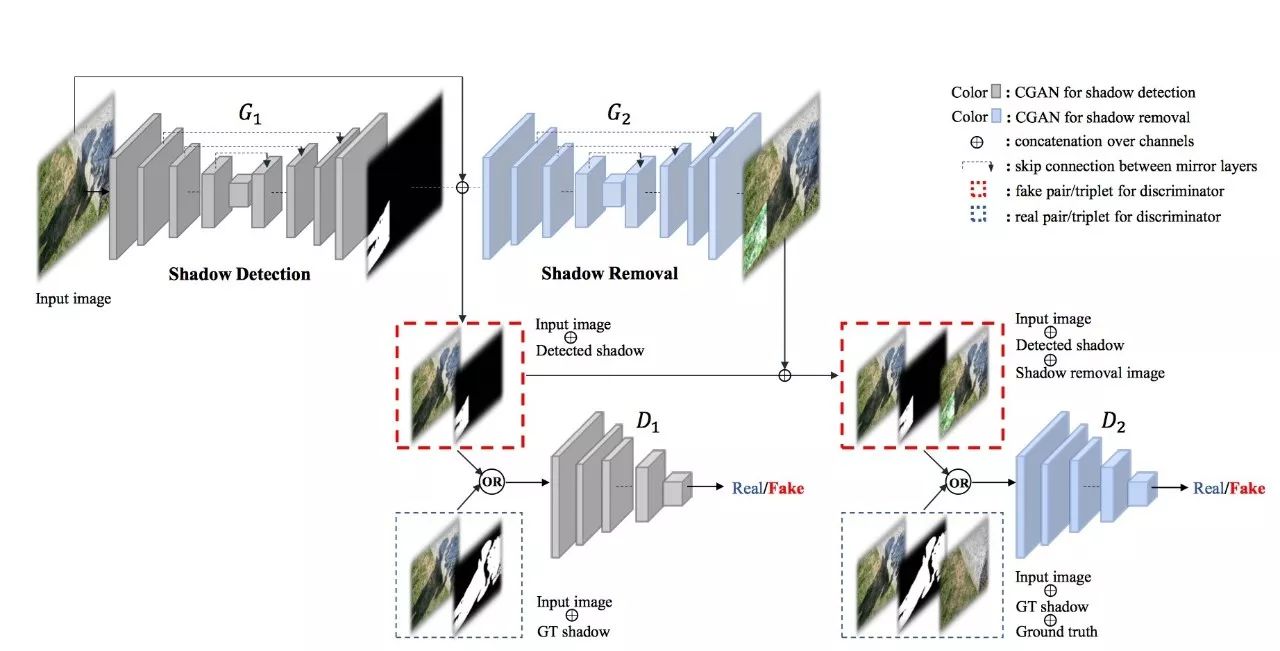
回到本篇文章将要介绍的ST-CGAN中来,介于pix2pix应用场景的单一性,很多人在思考如何将GAN应用于更广泛的应用场景中,ST-CGAN就是其中一个。ST-CGAN的模型结构如下图所示。
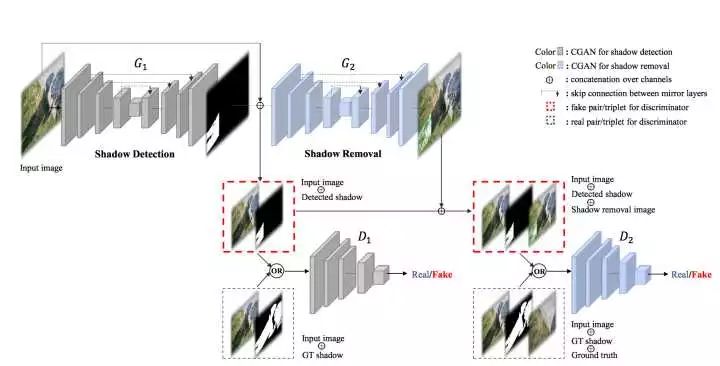
由上图我们可以看到,ST-CGAN构建了两个生成器,G1用于从原图生成含有阴影的图,G2用于从原图和阴影图的叠加中生成去除了阴影的图,而两个判别器则分别监督这两个生成过程,最终达到收敛。

可以看到论文中给出的效果都还不错。
论文中作者将Balance Error Rate (BER)作为评估检测(Detection)阴影效果的标准,用Root mean square error (RMSE)作为评估生成的去除阴影的图像(Removal)效果的标准
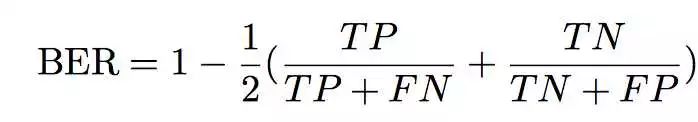
关于Balance Error Rate (BER)的详细解释读者可以看这个回答。Root mean square error (RMSE)就是在MSE的基础上取平方根。
在这里要吐槽一下,文中并没有指明BER表达式中几个变量对应的含义,包括在实验部分的表格中论文里给出了shadow和Non-shadow也没有给出定义。。。博主根据实验描述判断,这里把生成的阴影图切割为包含阴影的区域(shadow)和不包含阴影的区域(Non-shadow),然后针对这两个不同的类分别与Ground Truth计算对应的像素点之间的error(论文中的描述为"along with separated per pixel error rates per class (shadow and non-shadow“)。具体而言,TP/(TP+FN)指代阴影区域正确检测到阴影的部分,TN/(TN+FP)指代非阴影区域判断为没有阴影的部分,这样BER的值越低对应模型的效果就越好。
实验部分,论文提出了一个新的数据集ISTD(Large-scale Dataset with Image Shadow Triplets),与其他包含阴影图的数据集不同的地方在于,ISTD数据集包含三类数据,包含阴影的原始图片,阴影标注数据和不包含阴影的原始图片,基于ISTD数据集论文提出的模型才得以实践(因为模型要求的输入条件就必须包含这三种数据)。
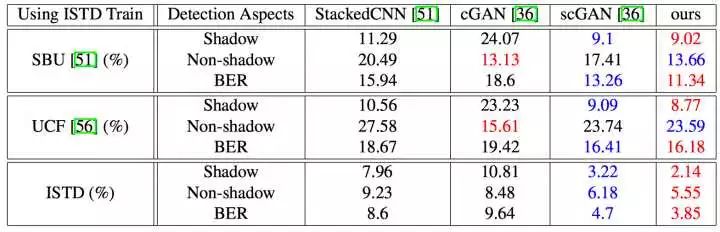
可以看到,基于ISTD数据集训练的情况下,ST-CGAN达到了不错的效果,同时为了说明模型的鲁棒性,论文也在别的数据集下做了对比实验,由于其它的数据集不具备包含三类数据的条件(即不包含没有阴影的原始图像),论文给出的解决办法是先用别的模型生成一个"roughly generated shadow-free images"添加到数据集中。
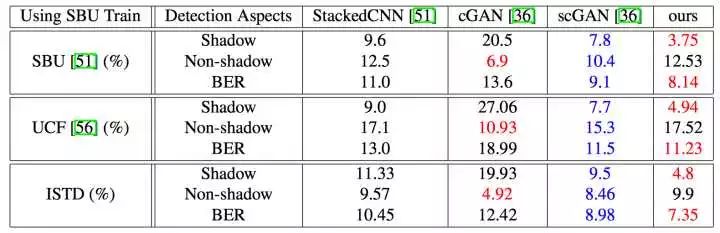
效果相对于第一个实验略差一点。还有几组数据这里就不再赘述了,论文给出了几种不同模型做阴影去除(Removal)的效果对比
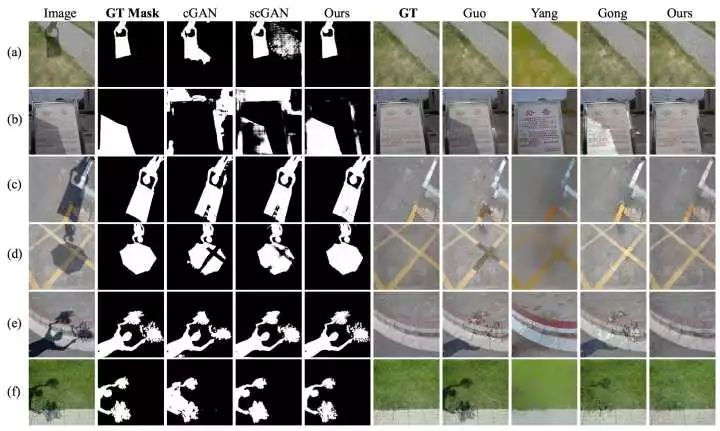
可以看到,除了第5组数据中阴影部分较暗的情况下效果略差,其他情况效果还不错。
最后,博主想到既然pix2pix实现了双向端到端的image translation,那ST-CGAN是否可以用来从原始图片生成出逼真的含有阴影的图片呢?这个可能要论文作者来解答了。
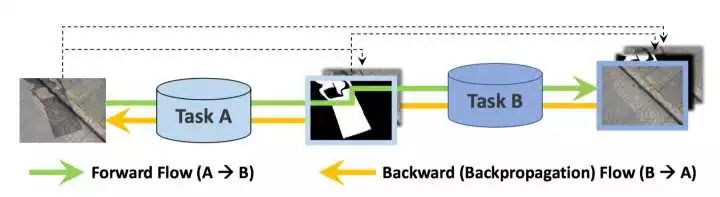
从B到A可能可以实现在没有阴影的图像上添加阴影的效果。
以上就是对ST-CGAN的大概解读,下面聊一下博主对这篇论文的优缺点评价:
优点:
idea很不错,用GAN来做Detection和Removal,为大家打开了思路,现在有不少人都在思考怎么把GAN拓展到更加广的应用场景里。
实验效果不错,与几个Baseline相比效果有明显提升。
缺点:
正如文中所说,论文描述里一些地方指代不清,希望原作者后续能给出新的版本。
相对于其它模型,ST-CGAN所需要的先验条件变多了,具体来讲就是需要包含阴影的原始数据,阴影图,不包含阴影的原始数据这三类数据,而其它的模型是在不具备第三类数据的情况下做的,在这样的情况下ST-CGAN表现更好可能跟它获取的输入条件更多有关。
实验中给出了阴影部分教深的情况下的实验结果,并没有给出在阴影部分较浅的情况下的结果,其次如何给出一个深浅的标准也是一个值得讨论的问题,这可能直接影响到对模型评价标准。
作者介绍:江亦凡,华中科技大学本科生,专注于深度学习和计算机视觉。
原文地址:https://zhuanlan.zhihu.com/p/31941969
以上是博主一些个人的想法,欢迎大家在评论区讨论。
热文精选
谷歌AI正式来中国了,机器学习三大职位正在招聘...如果你想跟李飞飞一起工作的话
算法还是算力?周志华微博引爆深度学习的“鸡生蛋,蛋生鸡”问题
不被邀请又怎样!马云都快买下中国AI芯片的半壁江山了,直怼腾讯和百度
Reddit热点 | 想看被打码的羞羞图片怎么办?CNN帮你解决
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
AI人才缺失催生的“跨境猎头”,人才年薪高达300万,猎头直赚100万




