强化学习是人工智能的未来?


强化学习作为通用人工智能的希望,吸引了很多人工智能爱好者学习和研究。Markov决策过程是最知名的强化学习模型,强化学习教程也常以Markov决策过程作为起点。但是,强化学习并不只有Markov决策过程这一种模型。本文全景式地分析强化学习的研究内容,展示Markov决策过程以外的广阔天地。

正强化与负强化
强化学习是一类能够最大化奖励、最小化惩罚的机器学习算法。强化学习这一概念在历史上来源于行为心理学,来描述生物为了趋利避害而改变自己行为的学习过程。这一概念后来被引入到人工智能领域中。
强化可以分为正强化和负强化。例如,我在写论文的过程中会有很多行为。如果某些行为能够让我的论文更容易被录用,甚至还能得最佳论文,获得很多引用,那么我会在以后更倾向采用这样的行为。这里的论文录用、论文获奖、论文被引就是正强化。如果某些行为会导致论文被拒,或是被查出学术不端行为,毕不了业了,那么我会在以后避免采用这样的行为。这里的论文悲剧、查重事故、毕不了业就是负强化。
在强化学习问题的建模过程中,正强化可以用奖励来量化,而负强化可以用代价来量化。
Jack Michael的论文《Positive and negative reinforcement, a distinction that is no longer necessary》(1975)论证了正强化和负强化的等价性。这意味着,奖励和代价可任取其一,最大化奖励和最小化代价没有区别。

智能体/环境接口
智能体/环境接口是强化学习最常见的建模方法,它把任务中的所有元素划分为智能体和环境两个部分:决策和学习的部分归为智能体,把其他部分归为环境。
考虑写论文的例子:我学习如何写论文,也决定要怎么写。我的学习和决策部分就是智能体。但是我自己整个人却不全是智能体。比如如果我生病了,那我就不写论文了。我的健康状况就属于环境的部分。
用智能体环境接口将智能体和环境分开后,智能体和环境之间只需要通过三个要素来交互。这三个要素是:动作、观测、奖励。
前面已经论证,奖励可以等价于负的代价,奖励一定是数值的,比如说是一个实数。与之相对,动作和观测不一定是数值。
例如,观测可以是“看到了帅气的小哥哥”或是“看到了漂亮的小姐姐”这样的事件,动作可以是“上前向小哥哥要微信”这样的动作。
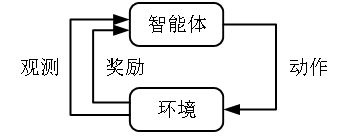
图 智能体/环境接口
快问快答
问:强化学习问题一定要使用智能体/环境接口来研究吗?
答:不一定。我们也可以在不划分智能体和环境的情况下对任务进行整体优化。比如我们知道某些参数能够驱动整个系统,那么我可以用Monte Carlo方法评估不同参数下的系统性能,再用进化算法求解最优参数。这样就在没有使用智能体/环境接口的情况下完成了强化学习。
问:既然强化学习可以采用智能体/环境接口也可以不采用智能体/环境接口,那为什么绝大多数求解使用智能体/环境接口呢?
答:智能体/环境接口把主观可以控制的部分和客观不能改变的部分分开,便于进一步分析和求解问题。

序贯决策与时间指标
智能体和环境可以交互多次,引入序贯决策问题。
对于序贯决策问题,我们可以引入时间指标来标记决策的顺序。
如果决策机会是可数的(有限次数或是无限可数次数),那么我们可以把决策时机和自然数一一对应。比如说第一次决策时机记为t=0,第二次决策时机记为t=1,依此类推。这时的智能体/环境接口就成为离散时间智能体/环境接口。
如果决策机会是不可数的,那么我们可以把决策时机和其等势的集合(如非负实数集)一一对应。时间指标规范化到实数集或其连续子集的时候智能体/环境接口就成为连续时间智能体/环境接口。
快问快答
问:强化学习问题一定是序贯决策问题么?
答:不一定。比如单次赌博机问题就不是序贯决策问题。非序贯决策问题不需要引入时间指标。
问:决策时机一定可以规范化为自然数集或是非负实数集么?
答:不一定。例如,对于半Markov过程,决策间隔是随机的。并且决策间隔的值会影响后续结果,所以模型不能忽略决策间隔。例如,我投了会议论文,下次决策的机会就是可以回复审稿人意见的时候。审稿人什么时候发回意见是不确定的,并且审稿人发回什么意见是和审稿人什么时候把审稿意见传上网是有关系的。
强化学习任务还可以根据智能体的数量划分为单智能体任务和多智能体任务。当任务中有多个智能体的时候,多个智能体并不一定同时有决策机会。在某个时刻,可能只有某些智能体有资格决策,其他智能体可能只能观察,或是连观察的资格都没有。
例如,几个人一起玩吃鸡游戏。某些玩家可能刚开局就落地成盒,后面就不用决策了。某些玩家能坚持到最后,有更多的决策机会。

环境的可观测性与环境模型
智能体获得观测后,有可能会知道环境信息。如果智能体能够通过观测完全了解环境,那么称该任务是完全可观测的;如果智能体通过观测完全不能了解环境,那么该任务是完全不可观测的;如果智能体通过观测能够部分了解环境,则该任务是部分可观测的。
强化学习算法可以分为有模型算法和无模型算法两类。
有模型算法是在求解过程中利用环境模型的算法。环境模型可以是事先给定的(比如AlphaGo算法、动态规划算法),也可以通过学习得到(比如Dyna算法、WorldModels算法)。
无模型算法不需要依赖环境模型的实现,实现更加简单。
无论算法是有模型算法还是无模型算法,可以假设环境具有某种驱动的形式。最常见的假设是认为从状态和动作到观测和奖励是以概率形式驱动的,可以表示为Pr[O,R|S,A]。
快问快答
问:环境一定是以概率形式驱动的吗?
答:不一定。环境还可能以其他形式驱动,比如以组合形式驱动。例如对于井字棋问题,就可以建模为组合问题,用alpha-beta算法求解。如果将本来的组合形式驱动的任务强行建模为用概率形式驱动的任务,则可能求不到最优解。对于围棋,AlphaGo算法并不一定能得到最优解。AlphaGo只是得到了相对比较好的解。

深度强化学习的新机会
从1950年算起,强化学习已经有接近70年的研究历史。在这并不短暂的研究历史中,绝大多数的研究都是和深度学习无关的,其算法是非深度强化学习算法。在诸多非深度强化学习算法中,资格迹算法实现简洁、性能优异,一度成为旗舰强化学习算法。
2013年,DeepMind发明了DQN算法,成功将深度学习和强化学习结合起来,开启了深度强化学习的新纪元。此后数年,强化学习的成果日新月异,很多非常困难的问题都被深度强化学习算法解决。
深度强化学习能够获得如此巨大的成功,原因在于深度学习可以表示非常复杂的解。
非深度强化学习算法能求解有数千个参数的解,而深度强化学习算法的解的参数数量可以远远超过这个数。具体而言,无模型深度强化算法的可以求解出有数亿参数的解,而有模型深度强化学习算法可以求解出有数千亿个参数的解。一般认为,有模型算法能够比无模型算法支持更复杂的解。如果对无模型算法强行使用过多的参数个数,会导致训练无法启动。
样本复杂性是强化学习算法的一个非常重要的性能指标。有观点认为,有模型算法之所以能够比无模型算法获得更复杂的解,正是因为有模型算法的样本利用率更高。
例如:围棋是一个非常困难的问题,它的解非常复杂,需要搭配非常深的神经网络。AlphaGo这样的有模型算法就充分依赖给定的模型,利用MCTS算法提高了样本利用率。

结语
诸多强化学习教程都是从学习Markov决策过程开始的。但是强化学习模型远不只有Markov决策过程这一种。
在本文中,我们已经知道强化学习不一定要用智能体环境接口,时间指标不一定是自然数集或非负实数集,环境不一定是概率驱动的,从观测不一定能完全知道状态,多个智能体不总是同时有资格决策,等等。所有这一切,都超出了Markov决策过程的模型假设。
强化学习的模型如此众多,在选择模型时要遵循两大准则:其一,模型要体现要解决的问题。模型往往是真实场景的简化。如果一个模型的的解答不足以充分解决要解决的真实问题,那么这个模型是不够的。其二,模型要能够妥善求解。如果一个模型太复杂,以至于完全无法从这个复杂至极的模型中获得任何有用的知识,那么这个模型也是没有什么用的。
作者:肖智清,清华大学工学博士。著有《神经网络与PyTorch实战》《强化学习:原理与Python实战》。scipy、sklearn等开源项目源码贡献者。近7年发表SCI/EI论文十余篇,多个顶级期刊和会议审稿人。在国内外多项程序设计和数据科学竞赛上获得冠军。
声明:本文系作者独立观点,不代表CSDN立场。
【End】

热 文 推 荐
☞大白话讲解比特币白皮书,十年后它依然是学习区块链的最佳资料,你真的读懂了吗?





