论文集锦 | ChinaMM 2019会议专栏上线!
点击中国图象图形学报→主页右上角菜单栏→设为星标


图片来源网络
第四届中国多媒体大会(ChinaMM 2020),将于2020年9月18-20日在青岛召开。会议将邀请本领域国内外学术界和企业界的顶尖专家与学者作主题报告,分享最新的前沿技术与产业热点。
《中国图象图形学报》作为ChinaMM 2020合作媒体,将发表部分会议推荐的优秀论文,大会征文主题点击了解:
图图推荐《中国图象图形学报》最新上线的ChinaMM 2019会议专栏,论文分别来自航天工程大学吴玲达研究员团队,南京信息工程大学刘青山教授团队,河海大学王慧斌教授团队,以及常州大学侯振杰教授团队。

利用稳健非负矩阵分解实现无监督高光谱解混
论文作者:宋晓瑞,吴玲达,孟祥利
作者单位:航天工程大学复杂电子系统仿真实验室
关键词:非负矩阵分解;无监督混合像元分解;端元提取;丰度估计;高光谱图像
全文链接:
基于非负矩阵分解的高光谱图像无监督解混算法普遍存在着目标函数对噪声敏感、在低信噪比条件下端元提取和丰度估计性能不佳的缺点。因此,论文提出一种基于稳健非负矩阵分解的高光谱图像混合像元分解算法。
在传统基于非负矩阵分解的解混算法基础上,对目标函数加以改进,用更加稳健的L1范数作为重建误差项,提高算法对噪声的适应能力,得到新的无监督解混目标函数。针对新目标函数的非凸特性,利用梯度下降法对端元矩阵和丰度矩阵交替迭代求解,进而完成优化求解,得到端元和丰度估计值。
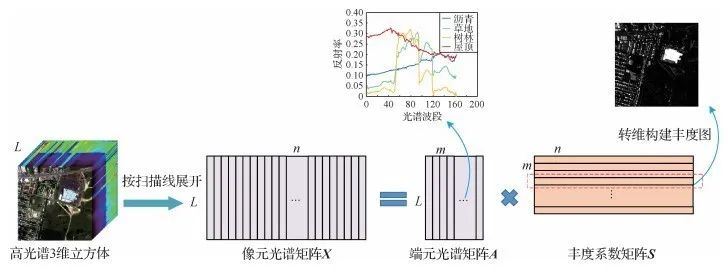
图1 论文方法
分别利用模拟和真实高光谱数据,对算法性能进行定性和定量分析。在模拟数据集中,将论文算法与具有代表性的5种无监督解混算法(VCA ,MVCNMF,RCoNMF,TVWSNMF,uDAS)进行比较,相比于对比算法中最优者,论文算法在典型信噪比20 dB下,光谱角距离(SAD)增大了10.5%,信号重构误差(SRE)减小了9.3%。
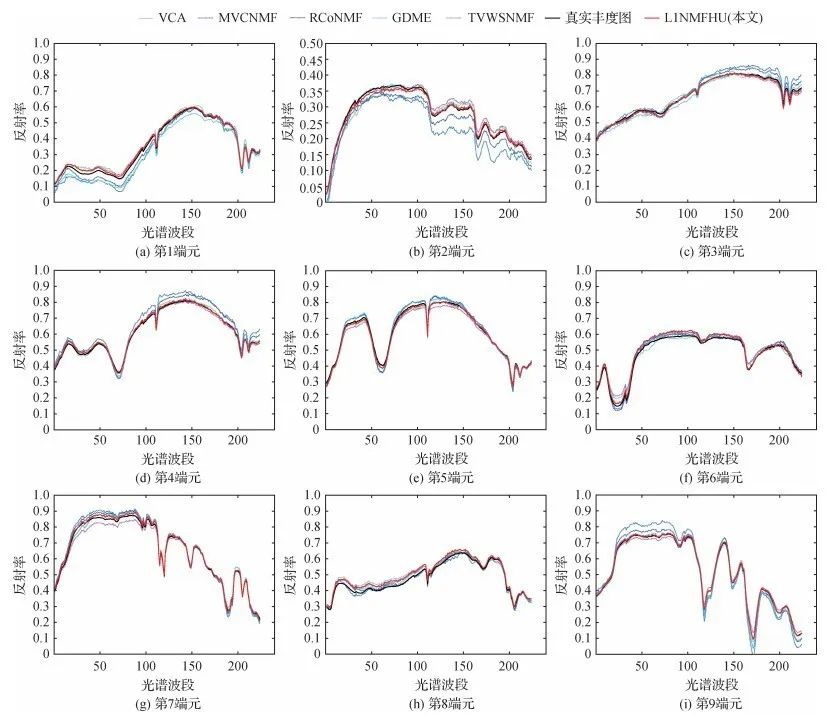
图2 信噪比为20dB时不同算法的端元光谱估计结果
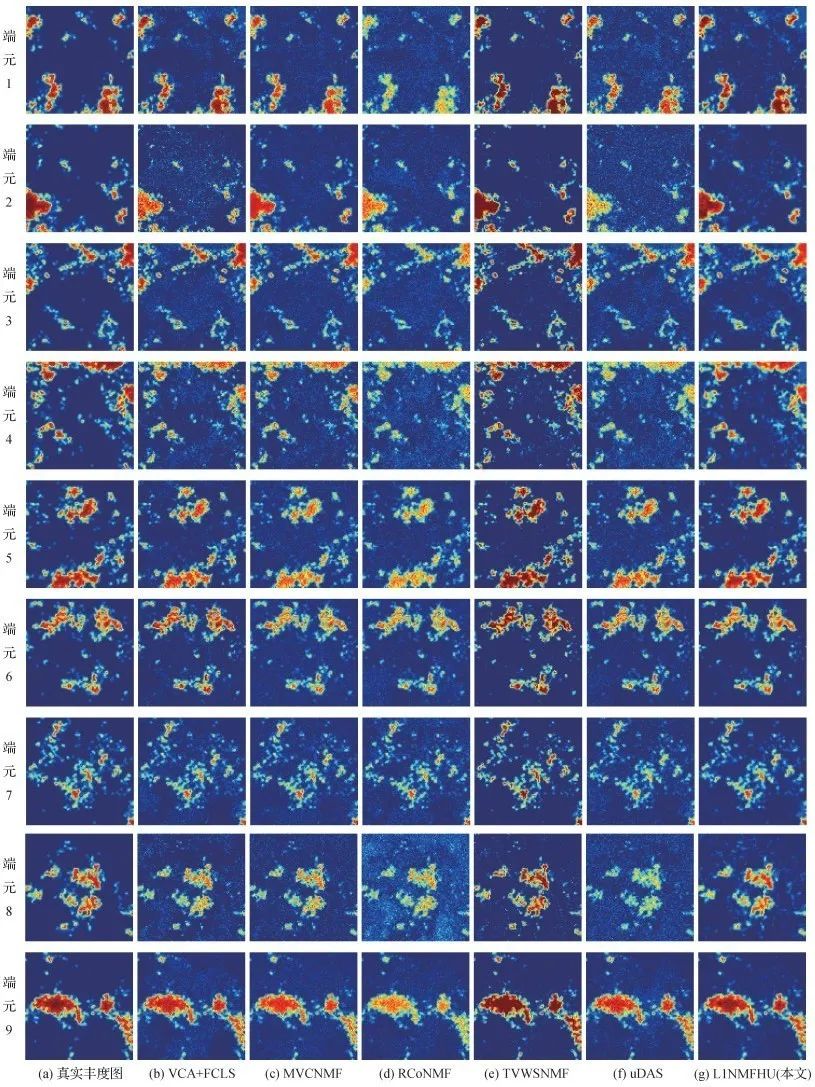
图3 信噪比为20dB时不同算法的丰度图估计结果
在真实数据集(Cuprite)中,利用光谱库中的地物光谱特征验证论文算法端元提取质量,并利用真实地物分布定性分析丰度估计结果。
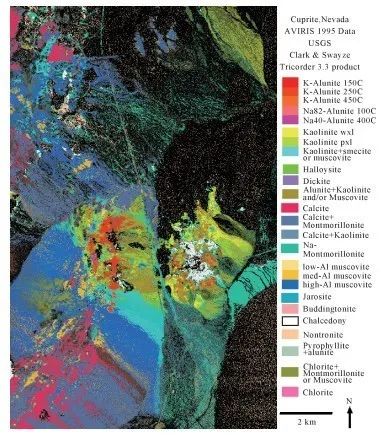
图4 Cuprite真实数据集中地物分布情况
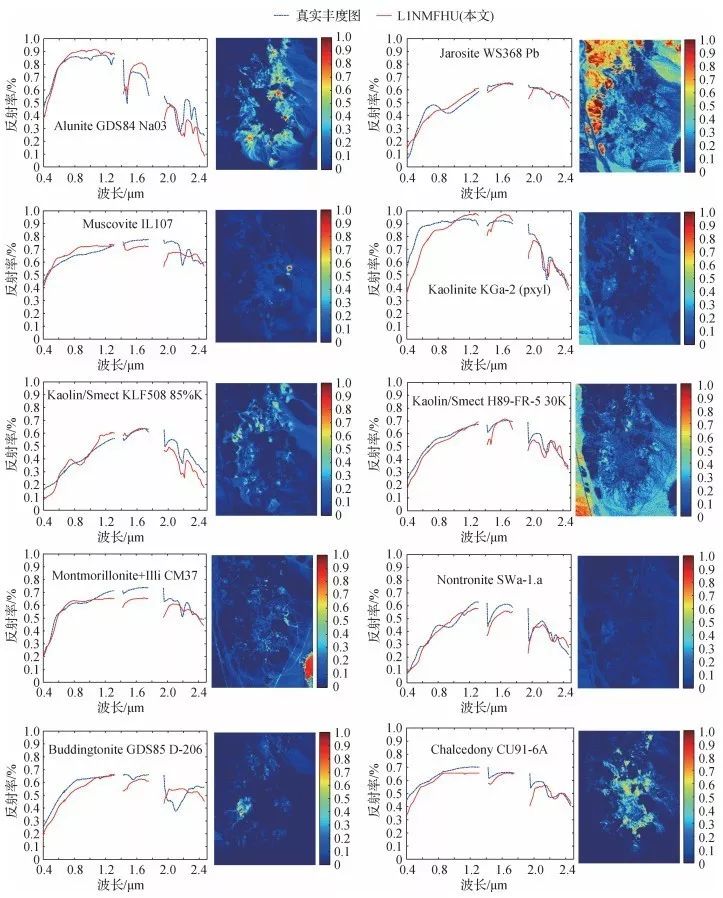
图5 Cuprite数据集的端元提取及丰度估计结果
论文算法在不同信噪比条件下均具有更好的解混性能,且在低信噪比条件下优势更为明显。然而,由于算法中存在迭代更新环节,具有较高的算法复杂度,实际应用中耗时较长。因此,在未来的研究中,将针对算法时间开销较大的缺陷,重点关注于算法的快速实现。


关键点深度特征驱动人脸表情识别
论文作者:王善敏,帅惠,刘青山
作者单位:南京信息工程大学自动化学院, 江苏省大数据分析技术重点实验室
关键词:人脸表情识别; 关键点检测; 多任务; 注意力模型; 中间监督
全文链接:
人脸关键点检测和人脸表情识别两个任务紧密相关。已有对两者结合的工作均是两个任务的直接耦合, 忽略了其内在联系。针对这一问题, 论文提出了一个多任务的深度框架, 借助关键点特征识别人脸表情。
参考Inception结构设计了一个深度网络, 同时检测关键点并识别人脸表情, 网络在两个任务的监督下更加关注关键点附近的信息, 使得五官周围的特征获得较大响应值。
为进一步减小人脸其他区域的噪声对表情识别的影响, 利用检测到的关键点生成一张位置注意图, 增加五官周围特征的权重, 减小人脸边缘区域的特征响应值。
复杂表情引起人脸部分区域的形变, 增加了关键点检测的难度, 为缓解这一问题, 引入了中间监督层, 在第1级检测关键点的网络中增加较小权重的表情识别任务, 一方面, 提高复杂表情样本的关键点检测结果, 另一方面, 使得网络提取更多表情相关的特征。
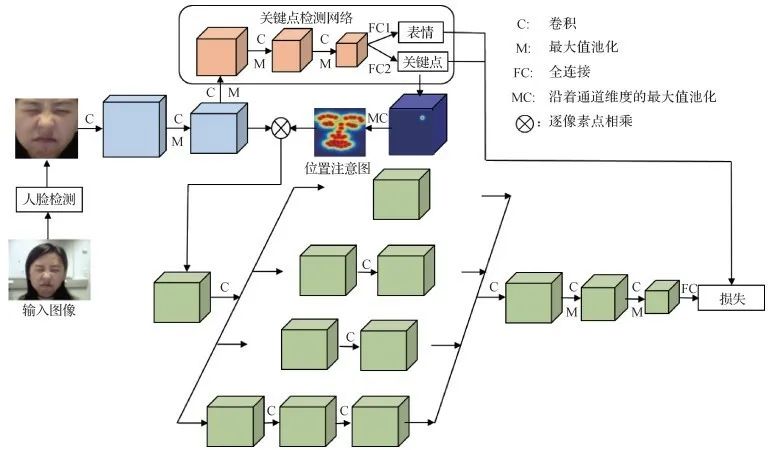
图1 论文方法

图2 特征图可视化结果
在3个公开数据集:CK+, Oulu和MMI上与经典方法:
AlexNet,多任务+SVM,Zero-bias CNN ,FaceNet2ExpNet,多任务CNN,多任务CNN+attention,DTAGN,VGG finetune,PPDN,CNN Baseline,AUDN,DeRL,CNN(Inception)
进行比较, 论文方法在CK+数据集上的识别准确率取得了最高值, 在Oulu和MMI数据集上的识别准确率比目前识别率最高的方法分别提升了0.14%和0.54%。
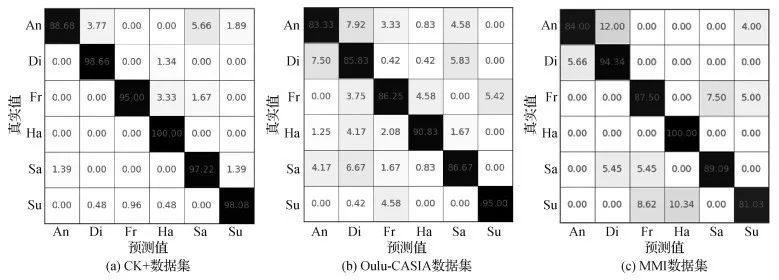
图3 3个数据集表情识别混淆矩阵
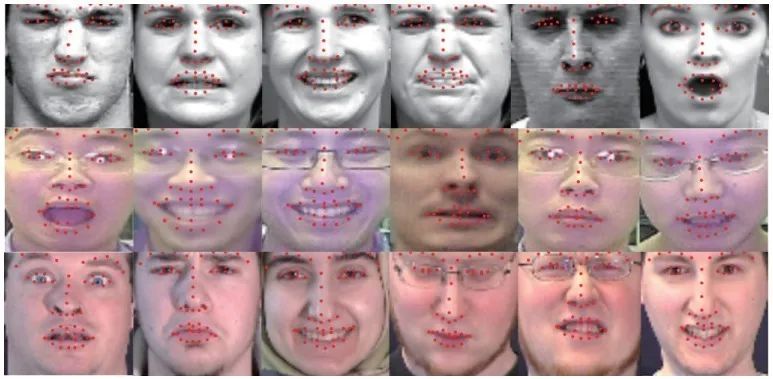
图4 部分样本关键点检测结果
论文设计的多任务网络对人脸表情识别的准确率优于单一的人脸表情识别网络,利用检测到的关键点生成的位置注意力图进一步提高了3个数据集上的表情识别率。
但是在识别人脸表情时, 论文方法较少考虑实际应用中存在的一些问题, 如:光照、遮挡、姿态等。光照问题是几乎所有视觉任务需要克服的困难, 现有的表情识别相关数据集基本没有涉及该问题, 将在后续研究中搜集更多相关数据集进行试验。


融合区域和边缘特征的水平集水下图像分割
论文作者:孙杨,陈哲,王慧斌,张振,沈洁
作者单位:河海大学计算机与信息学院
关键词:水下图像分割; 水平集; 深度信息; 边缘特征; 图像显著性
全文链接:
在水下环境中,由于水体高散射、强衰减等多因素的共同作用,使得现有图像特征及水平集模型难以适用于对水下图像的分割任务,分割结果与目标形态间存在较大差异。鉴于此,论文提出一种适用于水下图像分割的区域-边缘水平集模型,以提高水下图像目标分割的准确性。
综合应用图像的区域特征及边缘特征对水下目标进行辨识。对于区域特征,引入水下图像显著性特征;对于边缘特征,创新性地提出了一种基于深度信息的边缘特征提取方法。所提方法在融合区域级和边缘级特征的基础上,引入距离正则项对水平集函数进行规范,以增强水平集函数演化的稳定性。
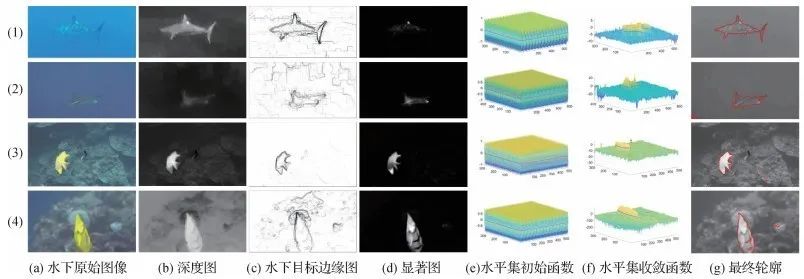
图1 水下图像分割过程
基于YouTube和Bubblevision水下数据集的实验结果表明,论文方法不仅对高散射强衰减的低对比度水下图像实现较好的分割效果,同时对处理强背景噪声图像也有较好的鲁棒性,与水平集分割方法LPF相比,分割精确度至少提高11.5%,与显著性检测方法HCN相比,精确度提高6.7%左右。
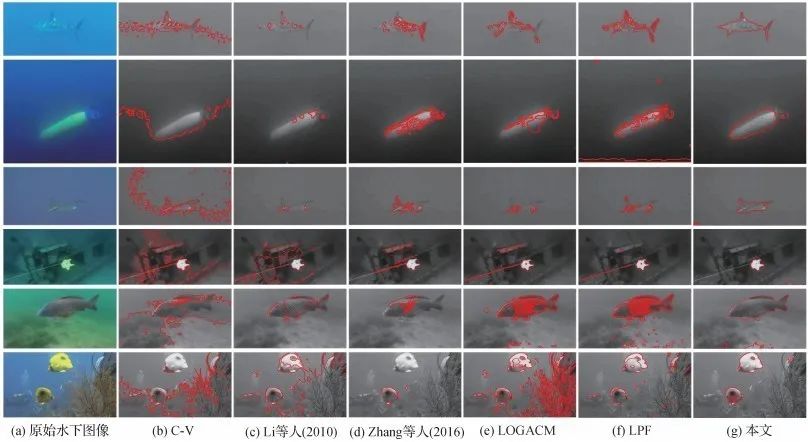
图2 与水平集方法的水下图像分割结果对比

图3 与显著性方法的水下图像分割结果对比
实验结果表明,所提模型适用于水下复杂场景中所采集的图像数据,能够有效区分目标与背景区域,并且准确拟合目标的轮廓。同时,量化评测结果也表明,与传统水平集方法相比,所提方法具有更好的图像分割能力。实验发现文中方法也存在一些不足,例如难以分割复杂纹理的目标,这将是后续研究工作的重点。


深度时空能量特征表示下的人体行为识别
论文作者:巢新,侯振杰,李兴,梁久祯,宦娟,刘浩昱
第一作者单位:常州大学信息科学与工程学院
关键词:行为识别; 深度图序列; 时序信息; 深度时空能量图; 关键帧
全文链接:
利用深度图序列进行人体行为识别是机器视觉和人工智能中的一个重要研究领域,现有研究中存在深度图序列冗余信息过多以及生成的特征图中时序信息缺失等问题。论文提出一种关键帧算法,该算法提高了人体行为识别算法的运算效率;针对时序信息缺失的问题,提出了一种新的深度图序列特征表示方法,即深度时空能量图DSTEM,该算法突出了人体行为特征的时序性。
关键帧算法根据差分图像序列的冗余系数剔除深度图序列的冗余帧,得到足以表述人体行为的关键帧序列。DSTEM算法根据人体外形及运动特点建立能量场,获得人体能量信息,再将能量信息投影到3个正交轴获得DSTEM。
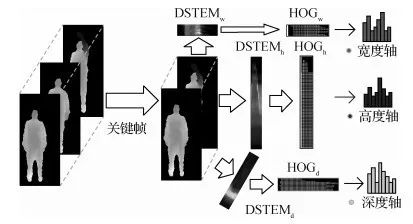
图1 基于关键帧与DSTEM的人体行为识别框架
在MSR_Action3D数据集上的实验结果表明,关键帧算法减少冗余量,各算法在关键帧算法处理后运算效率提高了20% 30%。对DSTEM提取的方向梯度直方图HOG特征,不仅在只有正序行为的数据库上识别准确率达到95.54%,而且在同时具有正序和反序行为的数据库上也能保持82.14%的识别准确率。

图2 数据集1上DSTEM-HOG的混淆矩阵

图3 数据集2上DSTEM-HOG的混淆矩阵
在MSR_Action3D数据集上的实验结果表明,关键帧算法提高了特征图提取速率和人体行为的识别准确率;DSTEM-HOG不仅在只有正序行为的数据库上,保持较高的识别准确率,而且在同时具有正序和反序行为的数据库上,依然保持较高的识别准确率。相比MEI和MHI,DSTEM保留了深度图序列的空间信息;相比DMM,DSTEM完整地保留了深度图序列的时序信息。但是DSTEM为获得完整的时序信息,而牺牲了部分空间信息。
下一步工作将继续探索去除深度图序列冗余信息的方法;继续研究DSTEM,使其在保留完整时序信息的同时,增强对空间信息的表征能力。




技术创新是社会和经济发展的核心驱动力,新冠疫情期间,基于视觉的情感感知技术、医学影像AI技术与自动驾驶技术受到社会的高度关注,如何打破领域技术瓶颈,让科技更好服务于人类,需要学术界和产业界相关研究者的共同探讨。
为探索上述问题,《中国图象图形学报》邀请业内专家共同策划推出“基于视觉的情感感知技术与应用”专刊、“AI+医学影像”专刊与“自动驾驶技术与应用”专刊,欢迎学术界和产业界的一线科研人员踊跃投稿。
以下为专刊征文通知,点击了解:
前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
算法集锦 | 深度学习如何辅助医疗诊断?
10篇CV综述速览计算机视觉新进展
算法集锦|深度学习在遥感图像处理中的六大应用
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
Hinton,吴恩达,李飞飞 !大师深度学习课程集锦
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
《中国图象图形学报》2019年第12期目次
《中国图象图形学报》2019年第11期目次
获取方式
本文系《中国图象图形学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:秀 秀
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。
与你同在
前沿 | 观点 | 资讯 | 独家
电话:010-58887030/7035/7418
网站:www.cjig.cn






