借助 TFLite GPU Delegate 的实时推理扫描书籍

vFlat 处理过程示意图
移动端的扫描应用随处可见,但大多数应用仅专注于将平面文档数字化,当我们在遇到扫描书页是曲面时便束手无策。
在扫描曲面上的文本时,用户要么手动拆除图书的装订部分来获取平整的扫描,要么不得不接受原样输入及后续阅读时带来的识别困难。
正因如此,我们在 VoyagerX 开发出 vFlat 这款 Android 应用,希望通过深度学习解决上述问题。vFlat 应用旨在让用户能够轻松扫描图书,无需担心曲面书页造成的识别困难。此外,这款应用还尝试自动确定书页边界,进而减少用户的手动操作。
注:vFlat
https://play.google.com/store/apps/details?id=com.voyagerx.scanner&hl=en_US


左:普通手机镜头下拍摄的曲面书页图像,右:经 vFlat 扫描的相同书页
借助光学字符识别 (Optical Character Recognition, OCR) 技术,用户可以轻松提取书页图像中的文本。在提取上方左图中的文本时,OCR 会因曲面弧度过大而无法正确识别某些单词和文本行。但是,如果使用同种技术处理右图,不仅成功率要高得多,而且提取到的文本基本上完全正确。

利用 vFlat 应用扫描右图得出的 OCR 结果
vFlat 应用的构建原理
我们开发出一种深度学习模型将曲面书页平面化,并提供移动端支持,以便为让用户获得最佳体验。在 vFlat 应用中,用户可通过“实时预览”功能实时(超过 20FPS)预览平面化书页。如果用户通过 vFlat 能实时预览平面化的扫描书页,便可在拍摄前调整好所需的角度和帧数。
vFlat 的“实时预览”功能
为了在移动应用中实现实时推理功能,我们需要对训练后的模型进行优化,并利用硬件加速的优势。我们的最初想法是借助 OpenGL 自行实现此推理模块,因此我们准备用 GLSL(OpenGL 着色语言)来实现该模型的各个层。
幸运的是,我们发现了 TensorFlow Lite 的 GPU 支持,并决定试用此功能(在编写此功能时,“tensorflow-lite-gpu”软件包版本已更新为“org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly”)。我们通过减少权重和复杂操作的数量,设计出此模型的轻量级版本,并且用 TFLite GPU Delegate 实现硬件加速。
注:tensorflow-lite-gpu
https://tensorflow.google.cn/lite/performance/gpu
相较于 CPU,GPU 拥有更强大的计算能力,且擅长处理大规模并行工作负载,因而非常适合用于深度神经网络。但使用移动 GPU 并非易事;正因如此,TFLite GPU Delegate 应运而生。
TFLite GPU Delegate 可优化移动端 GPU 的神经网络图,编译并生成异步执行的计算着色器。得益于 TFLite GPU Delegate,我们无需自行实现硬件加速推理模块,从而节省了数月的开发时间。
尽管 TFLite GPU Delegate 有助于节省时间和精力,但在将我们自己的模型转换为 TFLite 模型并将其与 TFLite GPU Delegate 集成时,我们也遇到了一些问题。该 GPU Delegate 的实验性版本仅支持在 MobileNet 中使用的运算,不支持我们原始模型中的一些运算。
注:MobileNet
https://tensorflow.google.cn/lite/performance/gpu_advanced#supported_ops
为了在不牺牲模型性能下使用该 GPU Delegate,我们需要替换部分运算,同时仍保持整体网络结构不变。我们在转换过程中遇到了一些问题,而由于代码当时尚未开源,因此很难准确查明错误原因(TFLite GPU Delegate 的代码现已公布于 GitHub 平台)。
注:GitHub - TFLite GPU Delegate
https://github.com/tensorflow/tensorflow/tree/5044a18831c68039dcb1ba33b03f76f32465c2e9/tensorflow/lite/delegates/gpu
例如,由于 TFLite GPU Delegate不支持 LeakyReLU 运算,我们不得不通过以下方式改用支持的 PReLU 运算,将:
tf.keras.layers.LeakyReLU(alpha=0.3)改为:
tf.keras.layers.PReLU(alpha_initializer=Constant(0.3), shared_axes=[1, 2], trainable=False)不过,在通过共享所有轴 (shared_axes=[1,2,3]) 将 PReLU 运算中的参数数量减少到 1 时,我们发现了一项异常行为。尽管此代码在 CPU 模式中能正常运行,但在 TFLite GPU Delegate中却运行失败,并返回错误 “Linear alpha shape does not match the number of input channels”。这也是我们最终只在轴 1 和轴 2 上共享参数的原因。
在尝试使用网络中的 Lambda 层归一化 -1 到 1 之间的输入数据时,我们遇到了另一个问题。
tf.keras.layers.Lambda(lambda x : (x / 127.5) — 1.0)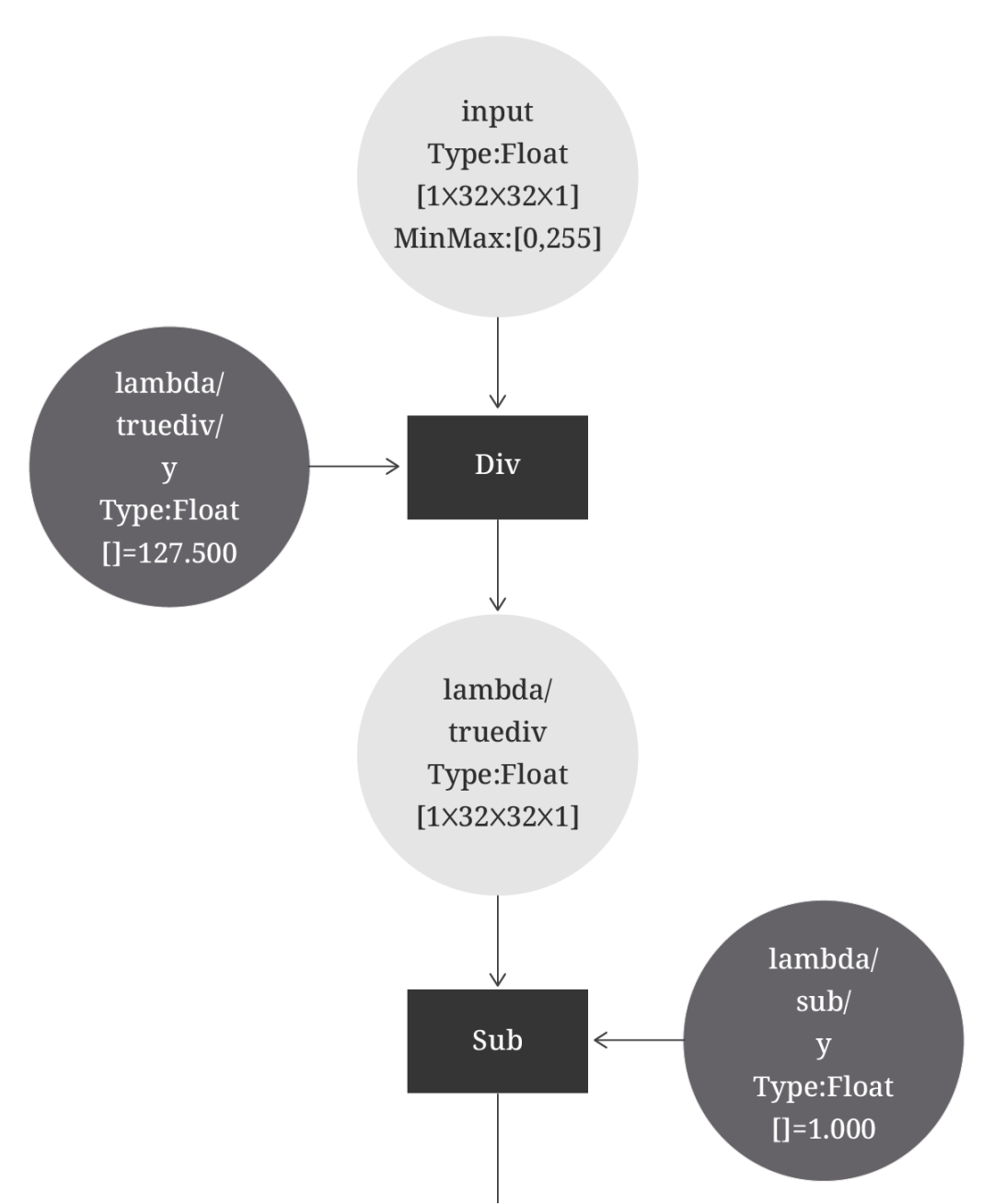
由 TFLite 转换器转换的 Lambda 层的可视化
注:TFLite 转换器
https://tensorflow.google.cn/lite/convert
此过程看似用于 TFLite GPU Delegate,但实际运行时,它会在无任何提示的情况下重新使用 CPU。在此情况下,TFLite 通常会向我们发送警告消息,例如“Failed to apply delegate. Only the first M ops will run on the GPU, and the remaining N on the CPU.”。因此,请谨慎使用 Lambda 层,并且务必在继续操作前预估实际推理时间。
结论
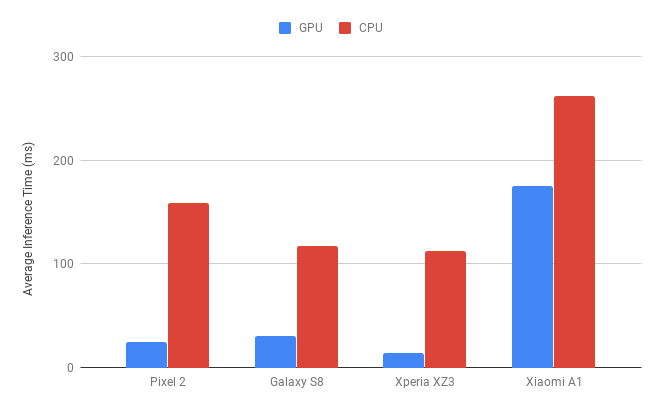
我们的模型在各类 Android 设备上的 GPU 平均推理时间与 GPU 基准推理时间对比
尽管在研究过程中阻碍重重,但通过使用 TFLite GPU Delegate,我们将模型的推理时间减少了一半以上。最终,我们打造出“实时预览”功能,为用户实时呈现平面化书页。
我们可以自信地说,使用 TFLite GPU Delegate 是一个明智之选。同时,如果您也想在移动设备上部署训练后的模型,强烈推荐您试用此工具。
如需了解详情并亲自试用,请参阅 TensorFlow Lite GPU Delegate (https://tensorflow.google.cn/lite/performance/gpu)。

vFlat 流程图
更多案例:
(点击 “阅读原文“,提交案例,我们将尽快和你联系)






