开源开放 | 一个用于知识驱动的零样本学习研究的开源数据集KZSL(CCKS2021)
OpenKG地址:http://openkg.cn/dataset/k-zsl
GitHub地址:https://github.com/China-UK-ZSL/Resources_for_KZSL
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:浙江大学(耿玉霞、陈卓、陈华钧),牛津大学(陈矫彦),爱丁堡大学(Jeff Z. Pan),华为(苑宗港)
本开放资源由浙江大学知识引擎实验室以及牛津大学的陈矫彦研究员和爱丁堡大学的Jeff Z. Pan教授联合贡献。在此开放资源中,我们为零样本学习相关技术贡献了类别语义知识图谱,图谱囊括了类别的属性信息和文本信息、结构化知识信息,以及语义更丰富的逻辑约束信息等,包含了比以往工作更丰富的类别语义知识,为推动知识驱动的零样本学习研究提供数据支撑。
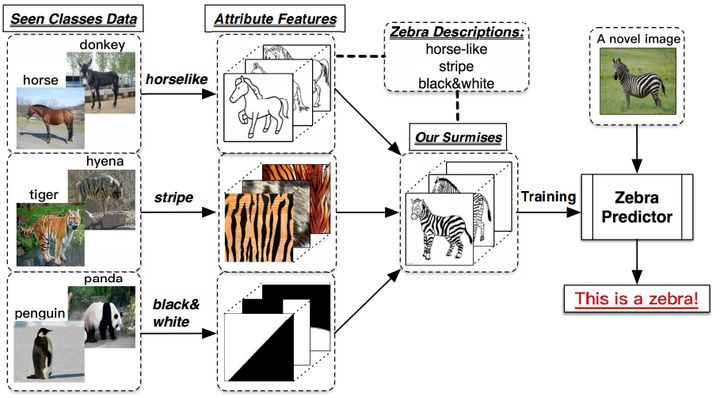
图1 知识驱动的零样本学习
对象间的语义联系通常依赖一些外部知识建立,如自然语言文本,这些外部知识从另一维度对象进行了描述(区别于对象的样本),且相比于标注样本更容易获取(如百科知识、在线语料)。其他的一些领域特定的语义知识如属性描述、类别层次等描述了领域内概念间的关系,为该领域的零样本预测问题提供了帮助。
借助知识图谱强大的知识表示和知识融合能力,我们提出使用知识图谱建模对象间的语义联系,并将现有的语义关系补充到图谱资源中,同时引入更丰富的关系类型,旨在解决现有工作中对象关系语义不足,以及缺乏基准数据集以公平比较各类知识驱动的零样本学习方法的问题。我们为两个典型的、来自不同领域的零样本学习问题构建了资源,即零样本图像分类和零样本知识图谱补全任务,下面我们将对这两个任务资源的构建过程进行简单介绍,具体的构建细节可参见原文(https://arxiv.org/pdf/2102.07339.pdf)。
零样本图像分类任务(ZS-IMGC)资源构建过程
零样本图像分类任务(Zero-shot Image Classification, ZS-IMGC),是指分类未在训练集中出现的类别的图像。在训练集中出现过的类别定义为seen类别,而未出现的类别定义为unseen类别,我们使用知识图谱为这些类别标签构建它们之间的语义联系。资源的构建过程如下:
(1)我们首先使用WordNet中定义的类别层次关系建立KG的基本结构,其中 每个类别对应 WordNet 中的一个实体节点,由 WordNet 实体 ID 唯一标识,不同的节点之间通过subClassOf关系连接;
(2)基于此结构,我们加入类别的属性信息。属性同样也被表示为节点,并通过自定义的ID唯一标识。对于类别节点和属性节点之间关系的定义,我们通过对属性分组/分类实现,这是因为,类别的部分属性信息通常描述了对象相同方面的特征,如红色、白色、黑色等属性均描述了对象的外观颜色,对于相同类别的属性,我们为其定义对应的连接关系,如为颜色属性定义hasColor属性。此外,对于属性的归类,同时也丰富了属性间的关系;
(3)接下来,我们在图谱中加入当前实体的文本描述信息。考虑到类别间具有明显的层次关联关系,且父类别与子类别间名称较相似,如红狐、黑狐等都是狐狸类别的子类,因此,我们选择类别及属性的名称作为文本语义加入图谱,并通过label关系,与当前图谱进行关联;
(4)此外,我们从外部KG如ConceptNet中抽取与当前类别和属性相关的知识。具体地,我们利用类别和属性的文本信息以字符串匹配的方式与外部 KG中的实体进行对齐,并抽取这些实体1跳范围内的三元组加入当前图谱中。对齐后的实体通过 sameAs 关系关联。此外,为保证抽取知识的质量,ConceptNet中一些不相关的关系在抽取的过程中被过滤;
(5)除上述语义信息外,我们在图谱中也引入了类别间以及类别和属性间的逻辑互斥关系。这是因为很多类别虽然视觉上存在较大差异但存在数量不少的共享属性,如“斑马”、“老虎”都有属性“条纹”、“尾巴”和“肌肉”等。大量的共享属性,使得这些视觉差异较大的类别,很容易在特征迁移时互相影响,因此,我们在这些类别之间添加互斥关系。同时我们也类别和属性间的互斥关系,如“斑马不吃鱼”声明了“斑马”和“吃鱼”间的互斥关系。
经上述构建过程,我们为ZS-IMGC任务构建了领域特定的知识图谱语义资源,构建的片段如下图所示:
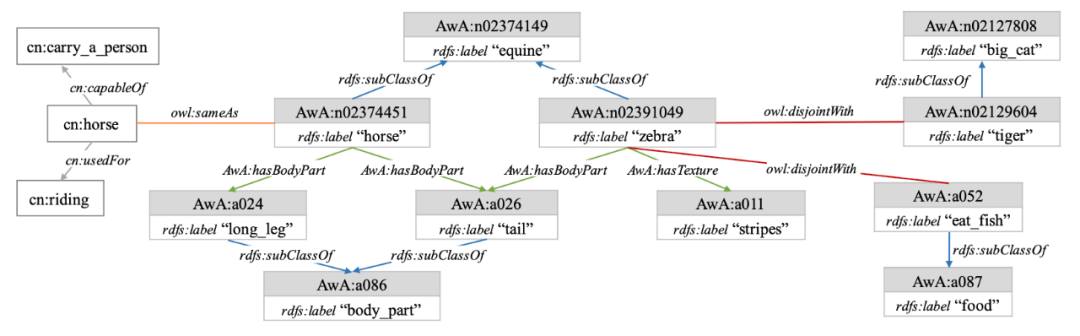
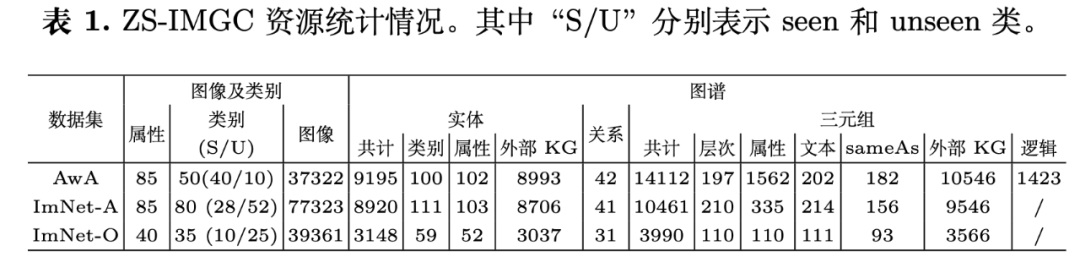
我们以ZS-IMGC任务的三个基准数据集AwA、ImNet-A和ImNet-O为例构建了该资源,资源的统计信息如下表所示。
零样本知识图谱补全任务(ZS-KGC)资源构建过程
该任务主要是为知识图谱补全过程中出现的新关系建模语义知识。不同于为ZS-IMGC构建的知识图谱资源,针对KG(即data graph)本身零样本的问题,我们利用知识图谱本体层的语义信息为知识图谱关系构建语义图谱(即schema graph)。
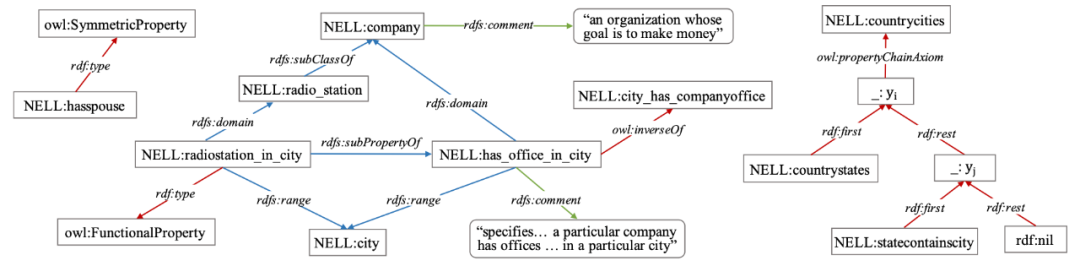
(1)我们首先利用RDFS中的术语定义schema graph的基本结构,不同于一般KG中关系被建模为实体间的连接边,在schema graph中,关系也可以出现在实体的位置,以此建模关系之间的关系,即元关系。具体地,我们利用rdfs:subPropertyOf定义关系间的层次关系,rdfs:domain和rdfs:range定义分别定义关系的头尾实体类型约束,以及rdfs:subClassOf 定义实体类型的层次结构,下图展示了该 schema的一个片段。
(2)随后,我们在schema graph中加入实体类型和关系的文本描述信息,引入关系的文本语义,这些文本通过rdfs:comment属性与当前图谱进行关联;
(3)除上述语义外,我们引入OWL术语描述关系间更复杂的关系,主要包括两类,一类是对关系间关系的表达,如等价关系、互逆关系、互斥关系以及组合关系,这些关系对于关系间关系的建立有重要帮助,如已知一个seen关系和一个unseen关系互为逆关系,则可以通过该seen关系的三元组直接推理预测出unseen的部分三元组。另一类是关系的属性信息,如对称&非对称、自反&非自反、函数&反函数、传递性等,这些属性可以帮助unseen关系进行更好的预测。
经上述构建过程,我们为ZS-KGC任务构建了领域特定的本体语义资源,构建的片段如下图所示:
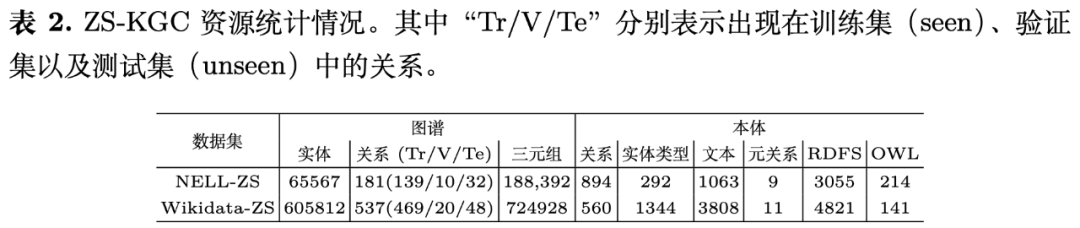
我们以ZS-KGC任务的两个基准数据集NELL-ZS和Wikidata-ZS为例构建了该资源,资源的统计信息如下表所示。
对于构建后的资源,我们可以从以下几个方面进行利用:
(1)首先是用于提升ZSL模型性能。现有ZSL方法在训练模型时,通常利用从语义知识中学习的语义向量,如属性向量和文本词向量。相应地,在利用基于知识图谱的语义资源增强ZSL模型性能时,可借助语义嵌入的相关技术如知识图谱表示学习和本体表示学习等对图谱进行向量化的表示,得到类别/关系的语义向量,应用到ZSL模型中;
(2)该资源还可应用于为ZSL模型提供可解释性。图谱中包含的类别间的共享知识可以很好地为类别间特征的可迁移性提供佐证。相比于使用通用域知识图谱为模型提供可解释性,我们所构建的知识图谱资源更加领域适配;
(3)从资源的统计数据中,我们可以发现,我们构建的图谱资源具有样本分布不均衡、部分关系/元关系具有对称性,以及存在组合逻辑语义等特点,这些语义特征依赖现有的知识图谱表示学习及本体表示学习技术无法很好地捕获,因此,我们希望基于此开放资源,探究表达能力更强、更鲁棒的语义嵌入技术,从而在深度学习的背景;
在本开放资源中,我们为来自两个不同领域的零样本学习任务构建了基于知识图谱的类别语义信息,并详解介绍了该语义资源的构建过程,构建的资源整合 ZSL 现有语义信息的同时,也为 ZSL 任务带来了语义更丰富的知识。这些知识 为 ZSL 模型定义了更丰富的类别/关系描述信息,从而帮助其进行更好的特 征迁移,同时,图谱资源也为 ZSL 模型的可解释性等任务带来了更丰富的 领域知识。我们希望此开放资源,可以更好地为研究知识驱动的零样本学习技术以及表达能力更强的语义嵌入技术提供支持,探究有效的神经-符号集成(Neural-Symbolic Integration)模式,促进人工智能系统的进步。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


