开源开放|CCKS2021入选开放图谱资源简介
笔记整理 | 王萌(东南大学)、张宁豫(浙江大学)

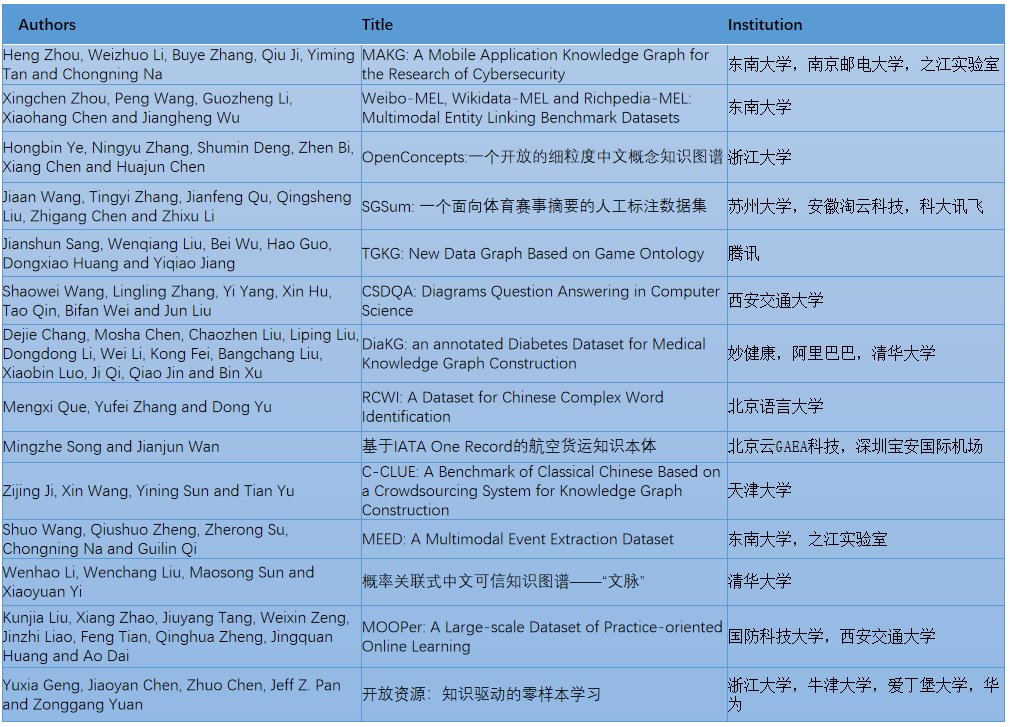
本次开放征集的录用论文具有以下三个特色。首先,录用的开放资源涵盖了多个垂直领域,例如,在移动终端领域,南京邮电大学提出了一个大规模移动应用知识图谱MAKG;在教育领域,西安交通大学提出了一个计算机学科的示意图视觉问答数据集CSDQA,国防科技大学提出了面向在线学习场景的数据集MOOPer;在体育领域,苏州大学提出了一个全新的面向体育赛事摘要的数据集SGSum;在医药健康领域,妙健康和阿里巴巴、清华大学提出了一个糖尿病知识图谱数据集DiaKG;在游戏领域,腾讯提出了面向游戏领域本体的数据图TGKG等。其次,录用资源的数据维度和类型丰富,例如,在本体层级,深圳宝安机场集团提出了“基于IATA One Record的航空货运知识本体”;在概念层级,浙江大学构建了一个细粒度中文概念知识图谱OpenConcepts;在不确定性和可信层级,清华大学提出了“面向概率关联式中文可信知识图谱—文脉”;在词汇层级,北京语言大学标注了一个高质量的中文复杂性词汇数据集RCWI;在多模态方面,东南大学提出了一个基于微博、维基、Richpedia构建的多模态实体链接数据集,以及联合之江实验室提出了一个全新的多模态事件抽取数据集MEED;在小样本方面,浙江大学联合多家单位共同提出了零样本学习数据集等。最后,录用的资源还包含了不少开源工具,如天津大学提出了一个基于众包的开源知识图谱构建系统C-CLUE等。
本开放征集的录用的论文列表如下,每篇论文作者都提供了资源下载链接及使用说明,我们将在未来一段时间逐一介绍每一篇工作:
CCKS介绍
全国知识图谱与语义计算大会(CCKS: China Conference on Knowledge Graph and Semantic Computing)由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议。CCKS源于国内两个主要的相关会议:中文知识图谱研讨会the Chinese Knowledge Graph Symposium (CKGS)和中国语义互联网与Web科学大会Chinese Semantic Web and Web Science Conference (CSWS)。首届中文知识图谱研讨会于2013年在苏州举行,随后分别在武汉、宜昌成功举办第二次和第三次研讨会。CSWS首次会议于2006年在北京举办,随后的近十年里,逐渐成为国内语义技术领域的主要会议。新的知识图谱与语义计算大会将致力于成为国内知识图谱、语义技术、链接数据等领域的核心会议,并聚集了知识表示、自然语言理解、智能问答、知识抽取、链接数据、图数据库、图挖掘、自动推理等相关技术领域的重要学者和研究人员。
致谢
感谢中国中文信息学会语言与知识计算专业委员会的支持,感谢CCKS2021组委会和各位审稿人的辛勤工作,感谢CCKS Resource Track的各位赐稿者,期待11月线下相聚广州。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。




