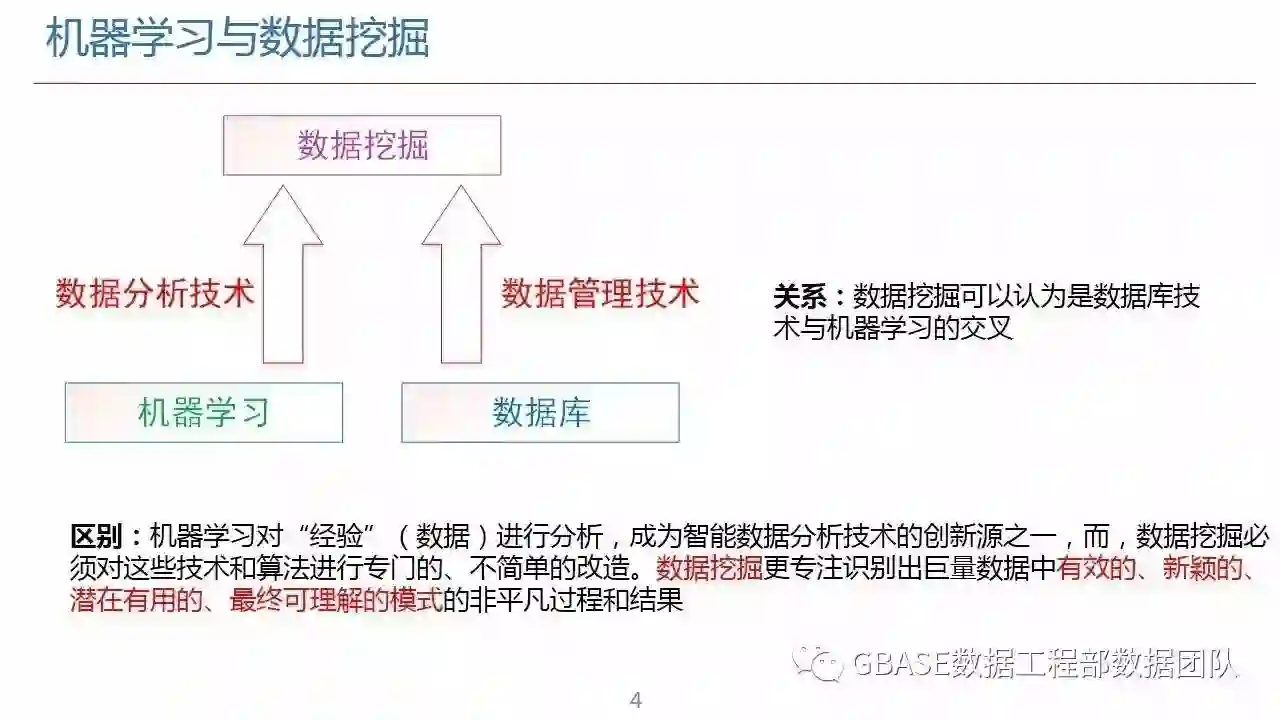
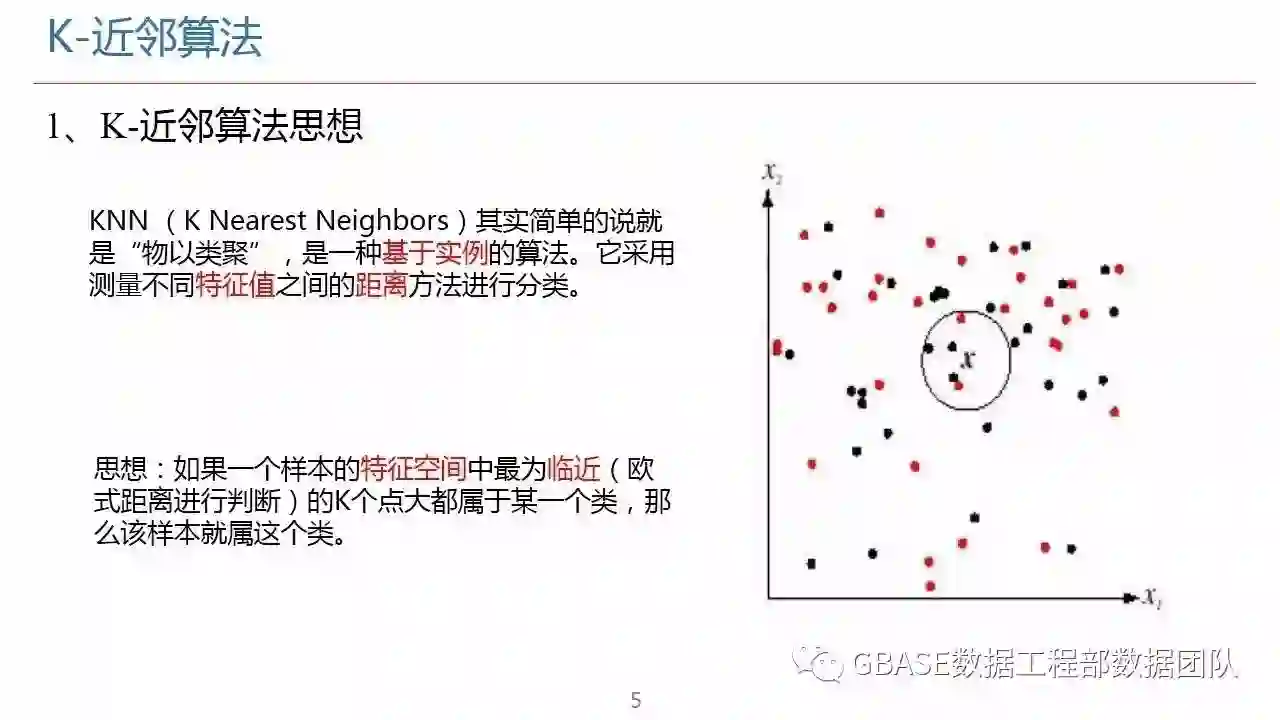
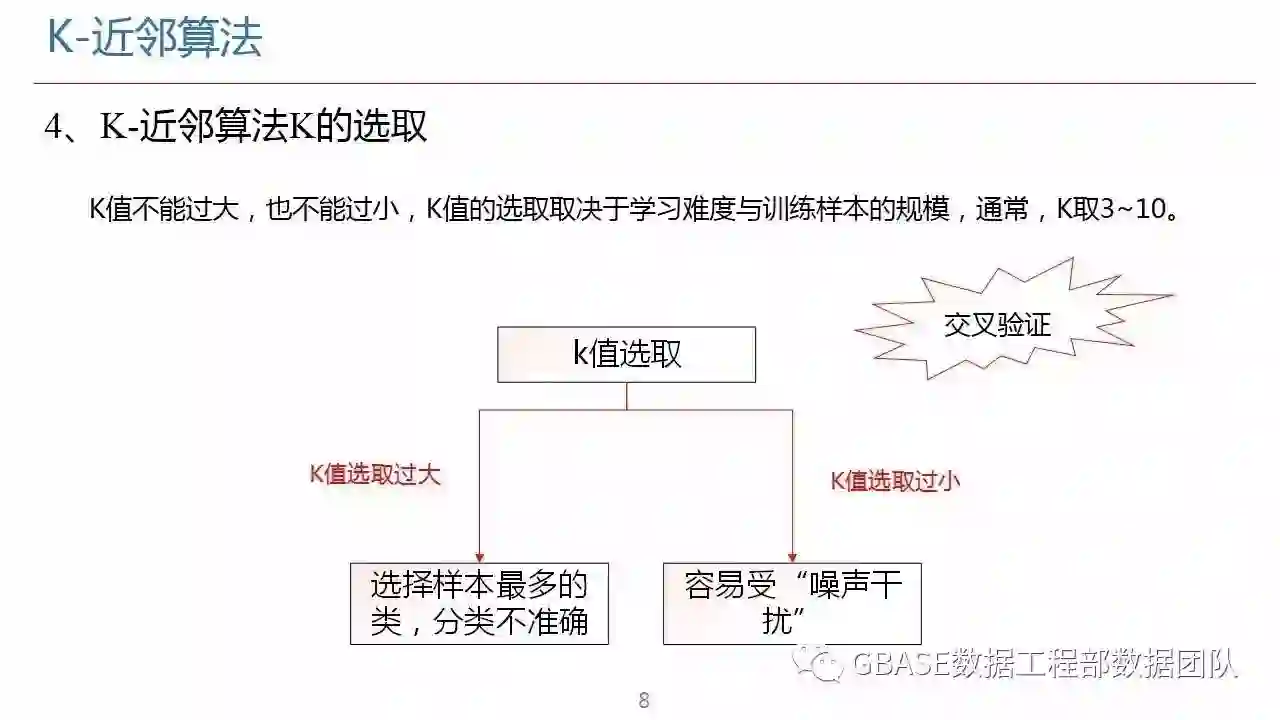
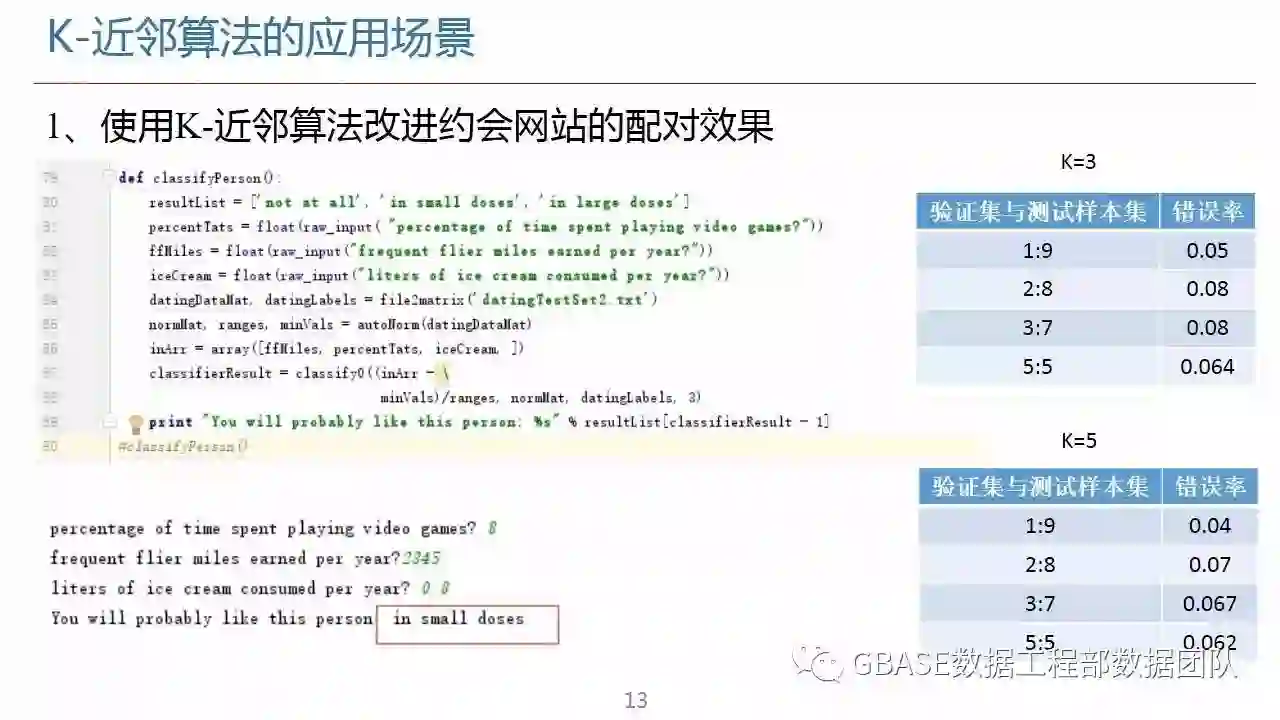
机器学习为数据挖掘提供数据分析支持,进一步推进数据挖掘中的关联分析。k-近邻算法是机器学习中基于实例的算法,常常用来对决策问题建立模型通过选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较,通过这种方式来寻找最佳的匹配。分类是基本的机器学习任务。k-近邻作为分类算法时,可以通过“投票法”预测结果,基于距离远近进行加权投票;作为回归算法时,可以通过“平均法”预测结果,基于距离远近进行加权平均。