问答 | 数据集如何确保开发集和测试集的数据分布一致?

这里是 AI 研习社,我们的问答版块已经正式推出了!欢迎大家来多多交流~
https://club.leiphone.com/page/question
(戳文末阅读原文直接进)
社长为你推荐来自 AI 研习社问答社区的精华问答。如有你也有问题,欢迎进社区提问。
话不多说,直接上题
问:数据集如何确保开发集和测试集的数据分布一致?
数据集如何确保开发集和测试集的数据分布一致。比如:某个数据集有A、B、C......F6个特征。要确保数据分布一致,怎么做?
来自社友的回答
▼▼▼
@duxiaoyang:
数据量足够大,交叉验证?
@吴正一BISTU:
像图像数据,我们采用的是统计每个类别的数据量,然后从各个类里按比例选取部分图像作为测试集。
如果是有明确特征列表的数据,我觉得可以先对特征做个统计,手工结合代码,对数据分布进行调整。
@沐沐mumu:
从语音方面来说:
一般没有专门去抽取,如果最严谨的方法是背景一致,内容一致区分;但是实际操作都是按照大类来进行,从声学和语言上考虑是搭配的。
像是录制的数据就好搞,但是线上的数据不太好搞成这样。
比如录制了一批数据,会记录每批数据的属性,比如性别,年龄,地区等,开发集和测试集按照比例分出来。
比如按照地域开发集是南北方各占50%,测试集也搞成南北方各占50%
(本答案来自好基友芳菲妹子解答~~~~么么哒~)
@MicoonZhang:
不好意思,回答晚了。
相信很多人都会有这种疑惑,我们用标准数据来训练,但是在真是的测试过程中,输入数据的并不会是标准数据,导致了训练与测试的两个过程中数据分布的不一致。
首先要说,训练集合与测试集合的分布完全一样,这个不太现实,因为相对于有限的训练集,测试集合理论上趋于无限大,所以无法穷尽。然而我们也不能为了单单去拟合我们手里的测试集而调整模型。
那么要了解业务场景,要知道你的产品需要到哪些场景中,人为的分析数据源,这样收集到的数据可能会更好。
这里假定你有个识别人脸的应用,你的数据集是来自某知名人脸数据库(简称原数据库),10w张左右,图片清晰标注明确。而你的用户是手机上传图像,图像模糊且场景较复杂,1w张左右。那么现在其实你应该关心的是1w张用户数据,但是1w张样本太少了(假设),那么此时可以随机划分出一部分用户图像与原数据库混合训练,但是测试集合一定是用户图像而非你的原数据库。那么这样的模型可能就会表现的更好一些(相对)。
还有就是做k折交叉验证:
转自:搜狐-机器学习研究会
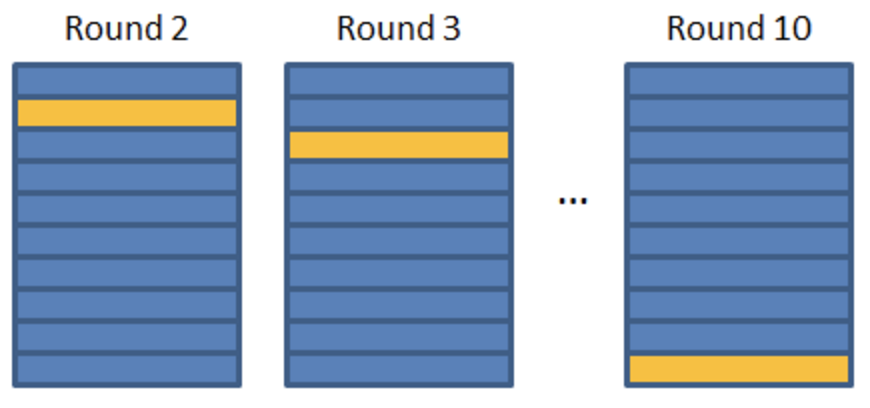
首先可以将训练数据分为10份,将其中的9份作为训练集(如下蓝色部分),其中的一份作为测试集(如下黄色部分)
通过这个训练数据,训练一个分词和词性标注器,然后对测试数据进行分词和词性标注。这个结果对黄色部分数据来说,就会与测试数据的分布接近,已经不是标准数据了。
然后还有其他9份数据,这个时候类似于K折交叉验证的思想。我们再将其余的9份数据依次作为测试数据。
比如下图类似:
图来自:K折交叉验证 :
GitBookhttps://www.gitbook.com/book/suetming/k-fold-cross-validation/details
If you know the distribution of the verification collection, do you still need to plan your training set?

@唐娜·亚伯拉:
一般评分卡的,基本是看PSI
欢迎点击“阅读原文”
或者移步 AI 研习社社区
我们会把你的问题对接给技术大牛




