AI 造出来个“假”奥巴马,你听到的奥巴马演讲可能也是假的 | 潮科技

概要:研究者们之所以选择奥巴马作为研究对象,是因为网上有很多奥巴马演讲的高清视频。
原作者:图普科技
不仅奥巴马可以被山寨,接下被山寨的可能是你!
研究人员介绍说,这项工作将有助于虚拟现实应用程序和加强现实应用程序生成人物的数字模型。
早前,华盛顿大学的计算机科学家们表示,通过对人物图像的分析,不论是像汤姆汉克斯和施瓦辛格这样的名人,还是像乔治布什和奥巴马这样的公众人物,他们都能够生成人物的数字模型。这项工作暗示着,只要网络上有大量的人物照片,创建人物数字模型将会变得非常简单。
研究者们之所以选择奥巴马作为研究对象,是因为网上有很多奥巴马演讲的高清视频。研究小组用一个神经网络来分析视频的数百万帧影像,以判断奥巴马在讲话时面部的变化,比如他的嘴唇、牙齿,甚至是嘴巴和下巴周围的皱纹。
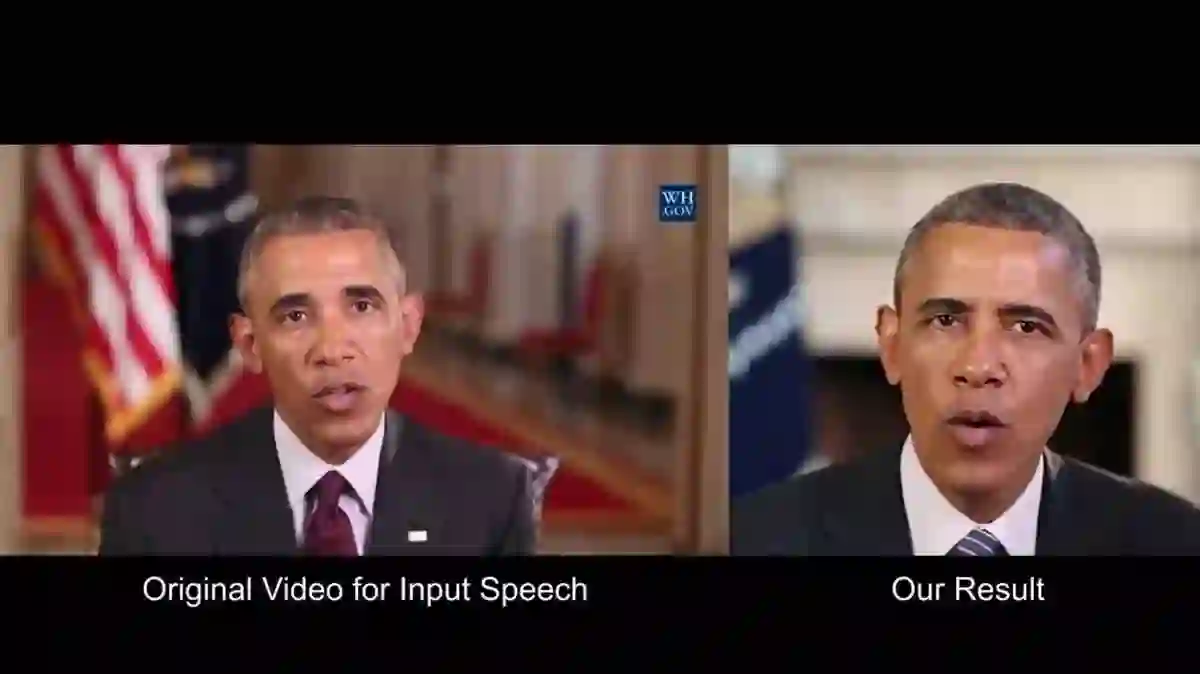
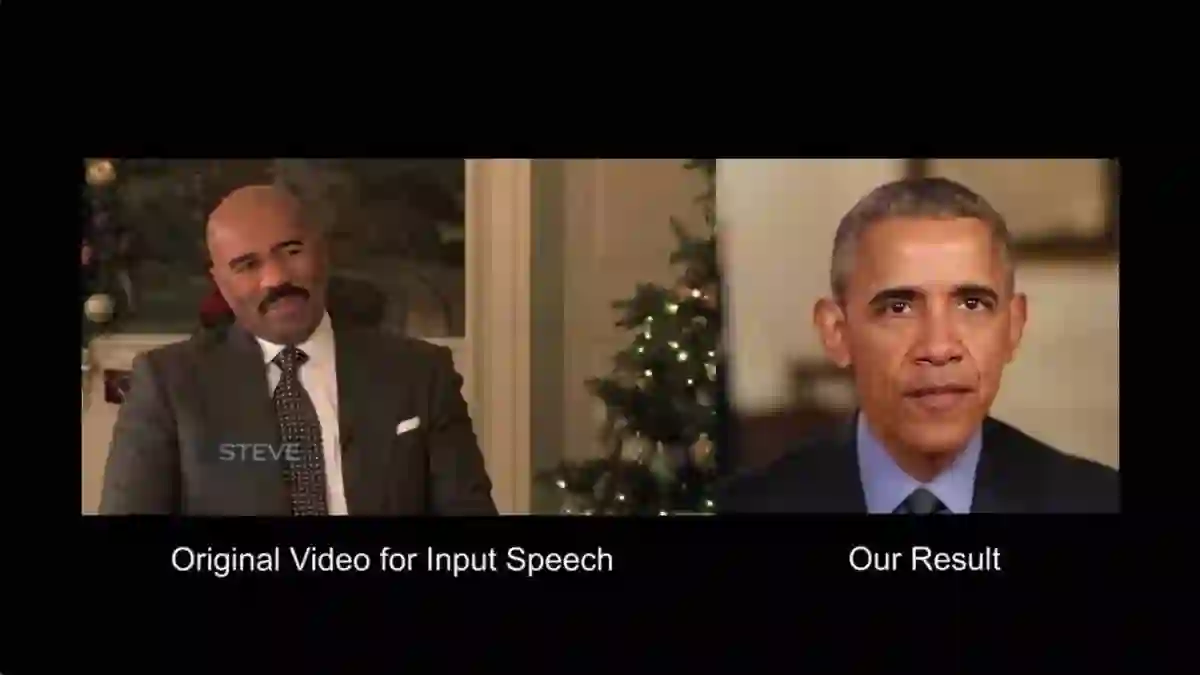

点击查看完整视频
在人工神经网络中,被称为“人工神经元”的组件实际上是输入的数据。这些组件共同协作来解决类似人脸识别和语音识别这样的问题。这个神经网络能够通过改变各个神经元间的关系模式,进而改变神经元的互动方式。经过不断的反复,这个神经网络最终就能选择出一种最有佳的解决方案——一个模仿人类大脑的人工智能战略模式。
在新的研究中,神经网络通过对音频和视频的分析,了解与声音匹配的各种口型。研究者们将音频与视频的原声文件对比分析,然后选取与音频匹配的口型,将它们嫁接到新视频中。从本质上来说,研究者们是将奥巴马多年来讲话的口型合成为一个新视频。
专家们表示,通过拍摄人们说话的视频,然后对声音和视频进行分析,进而总结出各种口型以及与之匹配的各种声音,这样的研究方式不仅成本高,而且非常单调、耗时。相反,这个神经网络能够通过对网上大量的视频文件的分析和研究,帮助我们总结出口型以及与之匹配的声音。
此项研究合作者、华盛顿大学的Ira Kemelmacher-Shlizerman指出,这项新技术的一个潜在应用是完善视频会议。视频会议的视频内容可能会断断续续或不够清晰,也可能被冻结,但音频内容一般不会出现这样的情况。因此,将来的视频会议可能会直接传输人们说话的音频,然后利用这个软件将他们说话的声音与他们可能出现的口型合成,形成一个虚拟的会议视频。Kemelmacher-Shlizerman表示,这项技术还能帮助人们在虚拟现实应用程序或加强现实应用程序中与数字虚拟人物进行交谈。
研究专家们指出他们合成的视频现在来说还不够完美。举例来说,当奥巴马在目标视频中稍微转过了脸,他的脸的3D模型就会产生缺陷,这也将导致他的部分嘴巴超出脸的范围,与背景相重叠。
研究团队表示他们的工作虽然可以模仿人的说话方式,但并不能模仿出人的感情。所以合成视频中的奥巴马的面部表情可能会出现与场合不相称的情况,比如在严肃的演讲中表情过于高兴。但是他们也表明,如果他们的神经网络能够从音频中预测人物的情绪状态,进而生成相应的视频,那么这将是非常有趣的研究成果。
研究者们在合成视频时,会尽量避免在新视频中出现奥巴马不曾涉及过的言论。研究的主要研究员,同时也是华盛顿大学的计算机科学家的Supasorn Suwajanakorn表示,这样的“假视频”是可能即将发生的。
然而,这项新研究同时也提出了未来检测“假视频”的方法。例如,研究人员进行的视频操作会模糊人物的嘴巴和牙齿。Suwajanakorn说:“人的肉眼可能很难发现这些细微的变化,但是将嘴部模糊部分与视频中其余部分作对比,程序能够轻易地识别出。”
研究者们推测,在某种程度上,口型与说话方式之间的联系可能对所有人都是普遍通用的。这就表明,经奥巴马和其他公众人物的视频训练的神经网络能够适用于很多不同的普通人。
原作者:图普科技
欢迎加入未来科技学院企业家群,共同提升企业科技竞争力
一日千里的科技进展,层出不穷的新概念,使企业家,投资人和社会大众面临巨大的科技发展压力,前沿科技现状和未来发展方向是什么?现代企业家如何应对新科学技术带来的产业升级挑战?
欢迎加入未来科技学院企业家群,未来科技学院将通过举办企业家与科技专家研讨会,未来科技学习班,企业家与科技专家、投资人的聚会交流,企业科技问题专题研究会等多种形式,帮助现代企业通过前沿科技解决产业升级问题、开展新业务拓展,提高科技竞争力。
未来科技学院由人工智能学家在中国科学院虚拟经济与数据科学研究中心的支持下建立,成立以来,已经邀请国际和国内著名科学家、科技企业家300多人参与学院建设,并建立覆盖2万余人的专业社群;与近60家投资机构合作,建立了近200名投资人的投资社群。开展前沿科技讲座和研讨会20多期。 欢迎行业、产业和科技领域的企业家加入未来科技学院
报名加入请扫描下列二维码,点击本文左下角“阅读原文”报名






