计算机视觉中,有哪些比较好的目标跟踪算法?(上)

本文作者YaqiLYU,本文整理自作者在知乎《计算机视觉中,目前有哪些经典的目标跟踪算法?》问题下的回答。AI 研习社已获得转载授权。
相信很多来这里的人和我第一次到这里一样,都是想找一种比较好的目标跟踪算法,或者想对目标跟踪这个领域有比较深入的了解,虽然这个问题是经典目标跟踪算法,但事实上,可能我们并不需要那些曾经辉煌但已被拍在沙滩上的tracker(目标跟踪算法),而是那些即将成为经典的,或者就目前来说最好用、速度和性能都看的过去tracker。我比较关注目标跟踪中的相关滤波方向,接下来我帮您介绍下我所认识的目标跟踪,尤其是相关滤波类方法,分享一些我认为比较好的算法,顺便谈谈我的看法。
第一部分:目标跟踪速览
先跟几个SOTA的tracker混个脸熟,大概了解一下目标跟踪这个方向都有些什么。一切要从2013年的那个数据库说起。。如果你问别人近几年有什么比较niubility的跟踪算法,大部分人都会扔给你吴毅老师的论文,OTB50和OTB100(OTB50这里指OTB-2013,OTB100这里指OTB-2015,50和100分别代表视频数量,方便记忆):
Wu Y, Lim J, Yang M H. Online object tracking: A benchmark [C]// CVPR, 2013.
Wu Y, Lim J, Yang M H. Object tracking benchmark [J]. TPAMI, 2015.
顶会转顶刊的顶级待遇,在加上引用量1480+320多,影响力不言而喻,已经是做tracking必须跑的数据库了,测试代码和序列都可以下载: Visual Tracker Benchmark(http://t.cn/RYhz9Sd),OTB50包括50个序列,都经过人工标注:

两篇论文在数据库上对比了包括2012年及之前的29个顶尖的tracker,有大家比较熟悉的OAB, IVT, MIL, CT, TLD, Struck等,大都是顶会转顶刊的神作,由于之前没有比较公认的数据库,论文都是自卖自夸,大家也不知道到底哪个好用,所以这个database的意义非常重大,直接促进了跟踪算法的发展,后来又扩展为OTB100发到TPAMI,有100个序列,难度更大更加权威,我们这里参考OTB100的结果,首先是29个tracker的速度和发表时间(标出了一些性能速度都比较好的算法):
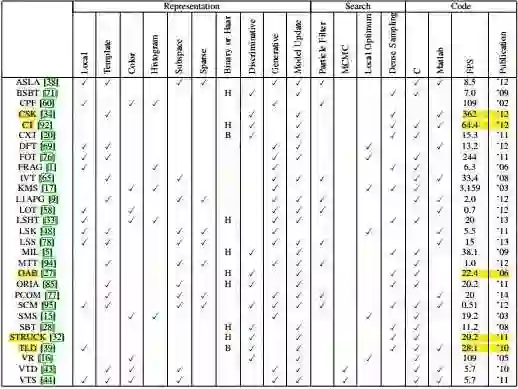
接下来再看结果(更加详细的情况建议您去看论文比较清晰):
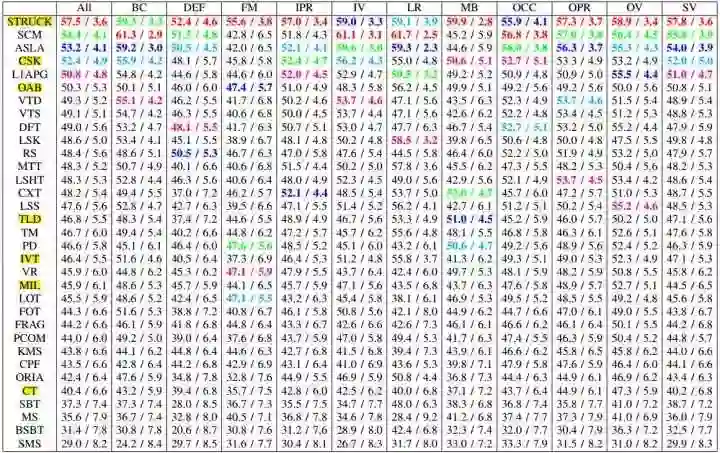
直接上结论:平均来看Struck, SCM, ASLA的性能比较高,排在前三不多提,着重强调CSK,第一次向世人展示了相关滤波的潜力,排第四还362FPS简直逆天了。速度排第二的是经典算法CT(64fps)(与SCM, ASLA等都是那个年代最热的稀疏表示)。如果对更早期的算法感兴趣,推荐另一篇经典的survey(反正我是没兴趣也没看过):
Yilmaz A, Javed O, Shah M. Object tracking: A survey [J]. CSUR, 2006.
2012年以前的算法基本就是这样,自从2012年AlexNet问世以后,CV各个领域都有了巨大变化,所以我猜你肯定还想知道2013到2017年发生了什么,抱歉我也不知道(容我卖个关子),不过我们可以肯定的是,2013年以后的论文一定都会引用OTB50这篇论文,借助谷歌学术中的被引用次数功能,得到如下结果:
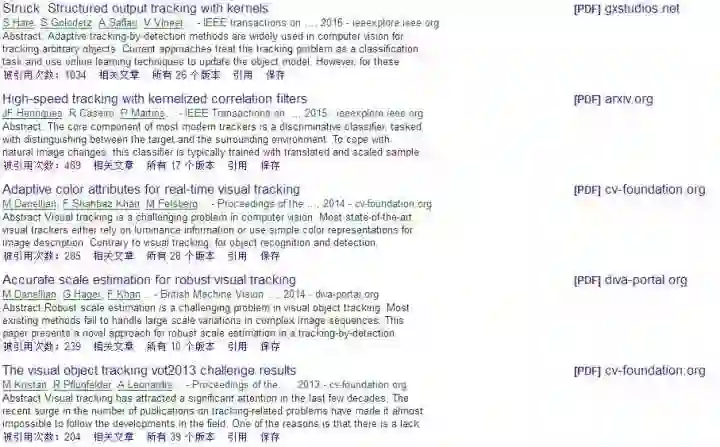
这里仅列举几个引用量靠前的,依次是Struck转TPAMI, 三大相关滤波方法KCF, CN, DSST, 和VOT竞赛,这里仅作示范,有兴趣可以亲自去试试。(这么做的理论依据是:一篇论文,在它之前的工作可以看它的引用文献,之后的工作可以看谁引用了它;虽然引用量并不能说明什么,但好的方法大家基本都会引用的(表示尊重和认可);之后还可以通过限定时间来查看某段时间的相关论文,如2016-2017就能找到最新的论文了,至于论文质量需要仔细甄别;其他方向的重要论文也可以这么用,顺藤摸瓜,然后你就知道大牛是哪几位,接着关注跟踪一下他们的工作 ) 这样我们就大致知道目标跟踪领域的最新进展应该就是相关滤波无疑了,再往后还能看到相关滤波类算法有SAMF, LCT, HCF, SRDCF等等。当然,引用量也与时间有关,建议分每年来看。此外,最新版本OPENCV3.2除了TLD,也包括了几个很新的跟踪算法 OpenCV: Tracking API(http://t.cn/RYhzun2):

TrackerKCF接口实现了KCF和CN,影响力可见一斑,还有个GOTURN是基于深度学习的方法,速度虽快但精度略差,值得去看看。tracking方向的最新论文,可以跟进三大会议(CVPR/ICCV/ECCV) 和arXiv。
第二部分:背景介绍
接下来总体介绍下目标跟踪。这里说的目标跟踪,是通用单目标跟踪,第一帧给个矩形框,这个框在数据库里面是人工标注的,在实际情况下大多是检测算法的结果,然后需要跟踪算法在后续帧紧跟住这个框,以下是VOT对跟踪算法的要求:

通常目标跟踪面临几大难点(吴毅在VALSE的slides):外观变形,光照变化,快速运动和运动模糊,背景相似干扰:

平面外旋转,平面内旋转,尺度变化,遮挡和出视野等情况:

正因为这些情况才让tracking变得很难,目前比较常用的数据库除了OTB,还有前面找到的VOT竞赛数据库(类比ImageNet),已经举办了四年,VOT2015和VOT2016都包括60个序列,所有序列也是免费下载 VOT Challenge | Challenges(http://t.cn/RYhZqT2):
Kristan M, Pflugfelder R, Leonardis A, et al. The visual object tracking vot2013 challenge results [C]// ICCV, 2013.
Kristan M, Pflugfelder R, Leonardis A, et al. The Visual Object Tracking VOT2014 Challenge Results [C]// ECCV, 2014.
Kristan M, Matas J, Leonardis A, et al. The visual object tracking vot2015 challenge results [C]// ICCV, 2015.
Kristan M, Ales L, Jiri M, et al. The Visual Object Tracking VOT2016 Challenge Results [C]// ECCV, 2016.
OTB和VOT区别:OTB包括25%的灰度序列,但VOT都是彩色序列,这也是造成很多颜色特征算法性能差异的原因;两个库的评价指标不一样,具体请参考论文;VOT库的序列分辨率普遍较高,这一点后面分析会提到。对于一个tracker,如果论文在两个库(最好是OTB100和VOT2016)上都结果上佳,那肯定是非常优秀的(两个库调参你能调好,我服,认了~~),如果只跑了一个,个人更偏向于VOT2016,因为序列都是精细标注,且评价指标更好(人家毕竟是竞赛,评价指标发过TPAMI的),差别最大的地方,OTB有随机帧开始,或矩形框加随机干扰初始化去跑,作者说这样更加符合检测算法给的框框;而VOT是第一帧初始化去跑,每次跟踪失败(预测框和标注框不重叠)时,5帧之后重新初始化,VOT以short-term为主,且认为跟踪检测应该在一起不分离,detecter会多次初始化tracker。
补充:OTB在2013年公开了,对于2013以后的算法是透明的,论文都会去调参,尤其是那些只跑OTB的论文,如果关键参数直接给出还精确到小数点后两位,建议您先实测(人心不古啊~被坑的多了)。VOT竞赛的数据库是每年更新,还动不动就重新标注,动不动就改变评价指标,对当年算法是难度比较大,所以结果相对更可靠。(相信很多人和我一样,看每篇论文都会觉得这个工作太好太重要了,如果没有这篇论文,必定地球爆炸,宇宙重启~~所以就像大家都通过历年ILSVRC竞赛结果为主线了解深度学习的发展一样,第三方的结果更具说服力,所以我也以竞赛排名+是否公开源码+实测性能为标准,优选几个算法分析)
目标视觉跟踪(Visual Object Tracking),大家比较公认分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪tracking-by-detection,为保持回答的完整性,以下简单介绍。
生成类方法,在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。举个例子,从当前帧知道了目标区域80%是红色,20%是绿色,然后在下一帧,搜索算法就像无头苍蝇,到处去找最符合这个颜色比例的区域,推荐算法ASMS vojirt/asms(http://t.cn/RYhZoH3):
Vojir T, Noskova J, Matas J. Robust scale-adaptive mean-shift for tracking [J]. Pattern Recognition Letters, 2014.
ASMS与DAT并称“颜色双雄”(版权所有翻版必究),都是仅颜色特征的算法而且速度很快,依次是VOT2015的第20名和14名,在VOT2016分别是32名和31名(中等水平)。ASMS是VOT2015官方推荐的实时算法,平均帧率125FPS,在经典mean-shift框架下加入了尺度估计,经典颜色直方图特征,加入了两个先验(尺度不剧变+可能偏最大)作为正则项,和反向尺度一致性检查。作者给了C++代码,在相关滤波和深度学习盛行的年代,还能看到mean-shift打榜还有如此高的性价比实在不容易(已泪目~~),实测性能还不错,如果您对生成类方法情有独钟,这个非常推荐您去试试。(某些算法,如果连这个你都比不过。。天台在24楼,不谢)
判别类方法,OTB50里面的大部分方法都是这一类,CV中的经典套路图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域:
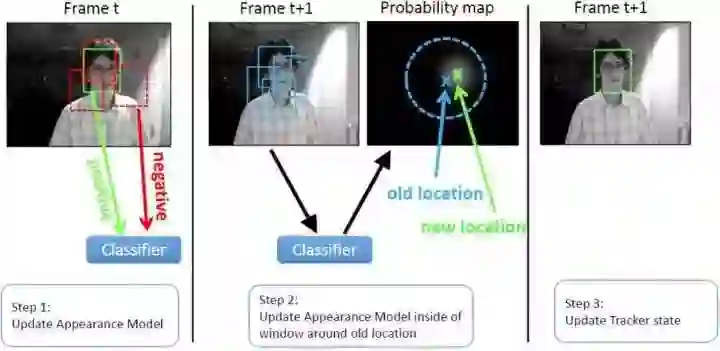
与生成类方法最大的区别是,分类器采用机器学习,训练中用到了背景信息,这样分类器就能专注区分前景和背景,所以判别类方法普遍都比生成类好。举个例子,在训练时告诉tracker目标80%是红色,20%是绿色,还告诉它背景中有橘红色,要格外注意别搞错了,这样的分类器知道更多信息,效果也相对更好。tracking-by-detection和检测算法非常相似,如经典行人检测用HOG+SVM,Struck用到了haar+structured output SVM,跟踪中为了尺度自适应也需要多尺度遍历搜索,区别仅在于跟踪算法对特征和在线机器学习的速度要求更高,检测范围和尺度更小而已。这点其实并不意外,大多数情况检测识别算法复杂度比较高不可能每帧都做,这时候用复杂度更低的跟踪算法就很合适了,只需要在跟踪失败(drift)或一定间隔以后再次检测去初始化tracker就可以了。其实我就想说,FPS才TMD是最重要的指标,慢的要死的算法可以去死了(同学别这么偏激,速度是可以优化的)。经典判别类方法推荐Struck和TLD,都能实时性能还行,Struck是2012年之前最好的方法,TLD是经典long-term的代表,思想非常值得借鉴:
Hare S, Golodetz S, Saffari A, et al. Struck: Structured output tracking with kernels [J]. IEEE TPAMI, 2016.
Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection [J]. IEEE TPAMI, 2012.
长江后浪推前浪,前面的已被排在沙滩上,这个后浪就是相关滤波和深度学习。相关滤波类方法correlation filter简称CF,也叫做discriminative correlation filter简称DCF,注意和后面的DCF算法区别,包括前面提到的那几个,也是后面要着重介绍的。深度学习(Deep ConvNet based)类方法,因为深度学习类目前不适合落地就不瞎推荐了,可以参考Winsty的几篇 Naiyan Wang - Home(http://t.cn/RYhZRKc),还有VOT2015的冠军MDNet Learning Multi-Domain Convolutional Neural Networks for Visual Tracking(http://t.cn/Rq626Dk),以及VOT2016的冠军TCNN (http://t.cn/RYhww93),速度方面比较突出的如80FPS的SiamFC SiameseFC tracker(http://t.cn/RcaRnrN)和100FPS的GOTURN davheld/GOTURN(http://t.cn/RYhwRRP),注意都是在GPU上。基于ResNet的SiamFC-R(ResNet)在VOT2016表现不错,很看好后续发展,有兴趣也可以去VALSE听作者自己讲解 VALSE-20160930-LucaBertinetto-Oxford-JackValmadre-Oxford-pu(http://t.cn/RYhwskg),至于GOTURN,效果比较差,但优势是跑的很快100FPS,如果以后效果也能上来就好了。做科研的同学深度学习类是关键,能兼顾速度就更好了。
Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking [C]// CVPR, 2016.
Nam H, Baek M, Han B. Modeling and propagating cnns in a tree structure for visual tracking. arXiv preprint arXiv:1608.07242, 2016.
Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking [C]// ECCV, 2016.
Held D, Thrun S, Savarese S. Learning to track at 100 fps with deep regression networks [C]// ECCV, 2016.
最后,深度学习END2END的强大威力在目标跟踪方向还远没有发挥出来,还没有和相关滤波类方法拉开多大差距(速度慢是天生的我不怪你,但效果总该很好吧,不然你存在的意义是什么呢。。革命尚未成功,同志仍须努力)。另一个需要注意的问题是目标跟踪的数据库都没有严格的训练集和测试集,需要离线训练的深度学习方法就要非常注意它的训练集有没有相似序列,而且一直到VOT2017官方才指明要限制训练集,不能用相似序列训练模型。
最后强力推荐两个资源。王强维护的benchmark_results (http://t.cn/RV08A2h):大量顶级方法在OTB库上的性能对比,各种论文代码应有尽有,大神自己C++实现并开源的CSK, KCF和DAT,还有他自己的DCFNet论文加源码,找不着路的同学请跟紧。
@H Hakase维护的相关滤波类资源(http://t.cn/RYhAlJn),详细分类和论文代码资源,走过路过别错过,相关滤波类算法非常全面,非常之用心!
第三部分:相关滤波
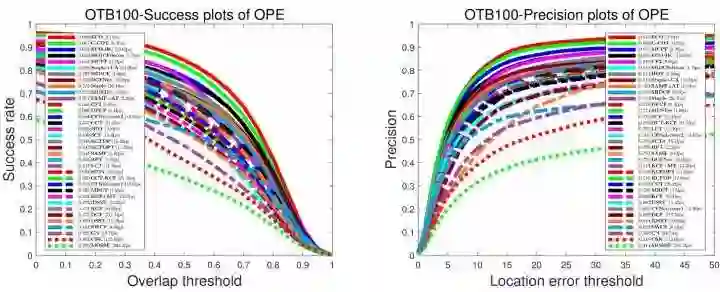
介绍最经典的高速相关滤波类跟踪算法CSK, KCF/DCF, CN。很多人最早了解CF,应该和我一样,都是被下面这张图吸引了:
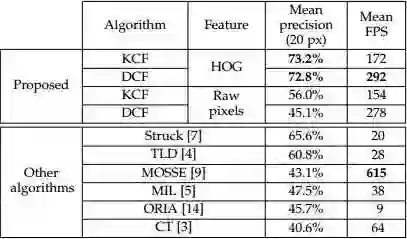
这是KCF/DCF算法在OTB50上(2014年4月就挂arVix了, 那时候OTB100还没有发表)的实验结果,Precision和FPS碾压了OTB50上最好的Struck,看惯了勉强实时的Struck和TLD,飙到高速的KCF/DCF突然有点让人不敢相信,其实KCF/DCF就是在OTB上大放异彩的CSK的多通道特征改进版本。注意到那个超高速615FPS的MOSSE(严重超速这是您的罚单),这是目标跟踪领域的第一篇相关滤波类方法,这其实是真正第一次显示了相关滤波的潜力。和KCF同一时期的还有个CN,在2014'CVPR上引起剧烈反响的颜色特征方法,其实也是CSK的多通道颜色特征改进算法。从MOSSE(615)到 CSK(362) 再到 KCF(172FPS), DCF(292FPS), CN(152FPS), CN2(202FPS),速度虽然是越来越慢,但效果越来越好,而且始终保持在高速水平:
Bolme D S, Beveridge J R, Draper B A, et al. Visual object tracking using adaptive correlation filters [C]// CVPR, 2010.
Henriques J F, Caseiro R, Martins P, et al. Exploiting the circulant structure of tracking-by- detection with kernels [C]// ECCV, 2012.
Henriques J F, Rui C, Martins P, et al. High-Speed Tracking with Kernelized Correlation Filters [J]. IEEE TPAMI, 2015.
Danelljan M, Shahbaz Khan F, Felsberg M, et al. Adaptive color attributes for real-time visual tracking [C]// CVPR, 2014.

CSK和KCF都是Henriques J F(牛津大学)João F. Henriques 大神(http://t.cn/RYh22WY)先后两篇论文,影响后来很多工作,核心部分的岭回归,循环移位的近似密集采样,还给出了整个相关滤波算法的详细推导。还有岭回归加kernel-trick的封闭解,多通道HOG特征。
Martin Danelljan大牛(林雪平大学)用多通道颜色特征Color Names(CN)去扩展CSK得到了不错的效果,算法也简称CN(http://t.cn/RYh2iJd)。
MOSSE是单通道灰度特征的相关滤波,CSK在MOSSE的基础上扩展了密集采样(加padding)和kernel-trick,KCF在CSK的基础上扩展了多通道梯度的HOG特征,CN在CSK的基础上扩展了多通道颜色的Color Names。HOG是梯度特征,而CN是颜色特征,两者可以互补,所以HOG+CN在近两年的跟踪算法中成为了hand-craft特征标配。最后,根据KCF/DCF的实验结果,讨论两个问题:
1. 为什么只用单通道灰度特征的KCF和用了多通道HOG特征的KCF速度差异很小?
第一,作者用了HOG的快速算法fHOG,来自Piotr's Computer Vision Matlab Toolbox,C代码而且做了SSE优化。如对fHOG有疑问,请参考论文Object Detection with Discriminatively Trained Part Based Models第12页。
第二,HOG特征常用cell size是4,这就意味着,100*100的图像,HOG特征图的维度只有25*25,而Raw pixels是灰度图归一化,维度依然是100*100,我们简单算一下:27通道HOG特征的复杂度是27*625*log(625)=47180,单通道灰度特征的复杂度是10000*log(10000)=40000,理论上也差不多,符合表格。
看代码会发现,作者在扩展后目标区域面积较大时,会先对提取到的图像块做因子2的下采样到50*50,这样复杂度就变成了2500*log(2500)=8495,下降了非常多。那你可能会想,如果下采样再多一点,复杂度就更低了,但这是以牺牲跟踪精度为代价的,再举个例子,如果图像块面积为200*200,先下采样到100*100,再提取HOG特征,分辨率降到了25*25,这就意味着响应图的分辨率也是25*25,也就是说,响应图每位移1个像素,原始图像中跟踪框要移动8个像素,这样就降低了跟踪精度。在精度要求不高时,完全可以稍微牺牲下精度提高帧率(但看起来真的不能再下采样了)。
2. HOG特征的KCF和DCF哪个更好?
大部分人都会认为KCF效果超过DCF,而且各属性的准确度都在DCF之上,然而,如果换个角度来看,以DCF为基准,再来看加了kernel-trick的KCF,mean precision仅提高了0.4%,而FPS下降了41%,这么看是不是挺惊讶的呢?除了图像块像素总数,KCF的复杂度还主要和kernel-trick相关。所以,下文中的CF方法如果没有kernel-trick,就简称基于DCF,如果加了kernel-trick,就简称基于KCF(剧透基本各占一半)。当然这里的CN也有kernel-trick,但请注意,这是Martin Danelljan大神第一次使用kernel-trick,也是最后一次。。。
这就会引发一个疑问,kernel-trick这么强大的东西,怎么才提高这么点?这里就不得不提到Winsty的另一篇大作:
Wang N, Shi J, Yeung D Y, et al. Understanding and diagnosing visual tracking systems[C]// ICCV, 2015.
一句话总结,别看那些五花八门的机器学习方法,那都是虚的,目标跟踪算法中特征才是最重要的(就是因为这篇文章我粉了WIN叔哈哈),以上就是最经典的三个高速算法,CSK, KCF/DCF和CN,推荐。
第四部分:14年的尺度自适应
VOT与OTB一样最早都是2013年出现的,但VOT2013序列太少,第一名的PLT代码也找不到,没有参考价值就直接跳过了。直接到了VOT2014竞赛 (http://t.cn/RYh2FSL)。这一年有25个精挑细选的序列,38个算法,那时候深度学习的战火还没有烧到tracking,所以主角也只能是刚刚展露头角就独霸一方的CF,下面是前几名的详细情况:
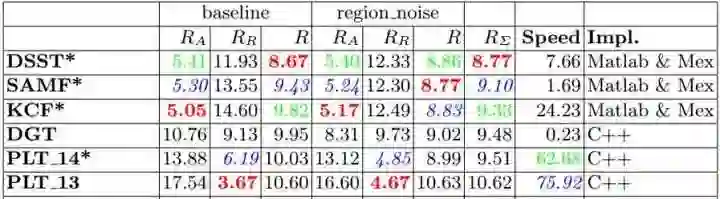
前三名都是相关滤波CF类方法,第三名的KCF已经很熟悉了,这里稍微有点区别就是加了多尺度检测和子像素峰值估计,再加上VOT序列的分辨率比较高(检测更新图像块的分辨率比较高),导致竞赛中的KCF的速度只有24.23(EFO换算66.6FPS)。这里speed是EFO(Equivalent Filter Operations),在VOT2015和VOT2016里面也用这个参数衡量算法速度,这里一次性列出来供参考(MATLAB实现的tracker实际速度要更高一些):

其实前三名除了特征略有差异,核心都是KCF为基础扩展了多尺度检测,概要如下:

尺度变化是跟踪中比较基础和常见的问题,前面介绍的KCF/DCF和CN都没有尺度更新,如果目标缩小,滤波器就会学习到大量背景信息,如果目标扩大,滤波器就跟着目标局部纹理走了,这两种情况都很可能出现非预期的结果,导致漂移和失败。
SAMF (http://t.cn/RYhLGfe),浙大Yang Li的工作,基于KCF,特征是HOG+CN,多尺度方法是平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及所在尺度:
Li Y, Zhu J. A scale adaptive kernel correlation filter tracker with feature integration [C]// ECCV, 2014.
Martin Danelljan的DSST(http://t.cn/RYhLa1k),只用了HOG特征,DCF用于平移位置检测,又专门训练类似MOSSE的相关滤波器检测尺度变化,开创了平移滤波+尺度滤波,之后转TPAMI做了一系列加速的版本fDSST,非常+非常+非常推荐:
Danelljan M, Häger G, Khan F, et al. Accurate scale estimation for robust visual tracking [C]// BMVC, 2014.
Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. IEEE TPAMI, 2017.

简单对比下这两种尺度自适应的方法:
DSST和SAMF所采用的尺度检测方法哪个更好?
首先给大家讲个笑话:Martin Danelljan大神提出DSST之后,他的后续论文就再没有用过(直到最新CVPR的ECO-HC中为了加速用了fDSST)。
虽然SAMF和DSST都可以跟上普通的目标尺度变化,但SAMF只有7个尺度比较粗,而DSST有33个尺度比较精细准确;
DSST先检测最佳平移再检测最佳尺度,是分步最优,而SAMF是平移尺度一起检测,是平移和尺度同时最优,而往往局部最优和全局最优是不一样的;
DSST将跟踪划分为平移跟踪和尺度跟踪两个问题,可以采用不同的方法和特征,更加灵活,但需要额外训练一个滤波器,每帧尺度检测需要采样33个图像块,之后分别计算特征、加窗、FFT等,尺度滤波器比平移滤波器慢很多;SAMF只需要一个滤波器,不需要额外训练和存储,每个尺度检测就一次提特征和FFT,但在图像块较大时计算量比DSST高。
所以尺度检测DSST并不总是比SAMF好,其实在VOT2015和VOT2016上SAMF都是超过DSST的,当然这主要是因为特征更好,但至少说明尺度方法不差。总的来说,DSST做法非常新颖,速度更快,SAMF同样优秀也更加准确。
DSST一定要33个尺度吗?
DSST标配33个尺度非常非常敏感,轻易降低尺度数量,即使你增加相应步长,尺度滤波器也会完全跟不上尺度变化。关于这一点可能解释是,训练尺度滤波器用的是一维样本,而且没有循环移位,这就意味着一次训练更新只有33个样本,如果降低样本数量,会造成训练不足,分类器判别力严重下降,不像平移滤波器有非常多的移位样本(个人看法欢迎交流)。总之,请不要轻易尝试大幅降低尺度数量,如果非要用尺度滤波器33和1.02就很好。
以上就是两种推荐的尺度检测方法,以后简称为类似DSST的多尺度和类似SAMF的多尺度。如果更看重速度,加速版的fDSST,和仅3个尺度的SAMF(如VOT2014中的KCF)就是比较好的选择;如果更看重精确,33个尺度的DSST,及7个尺度的SAMF就比较合适。
(未完待续)

10年前的DARPA挑战赛是催生自动驾驶商业化的里程碑,10年后的硅谷和匹兹堡成为全球自动驾驶研发和部署最激进的两个大本营。除了两地的斯坦福大学和卡耐基梅隆大学,Google、Uber、Tesla等大公司以及传统车企的超前研发也为美国的自动驾驶行业培养了大量人才。
而在地球的另一端,中国已经是最大的汽车消费市场,市场规模、特色的道路和法规环境让中国市场成为一个独特且极具吸引力的市场。即便在美国,华人势力也是自动驾驶创新领域一支重要的主力军。
2018年1月16日,雷锋网将在旧金山湾区举办GAIR硅谷智能驾驶峰会,我们希望汇集中美两地最强的自动驾驶研发力量,与学界、互联网大公司、汽车行业以及新技术公司一起来一场自动驾驶领域的大爬梯。

深度学习目标检测概览
▼▼▼




