ACM顶会CIKM 2022放榜!度小满AI Lab三篇入选
![]()
新智元报道

新智元报道
【新智元导读】国际顶会历来是AI技术的试金石,也是各家企业大秀肌肉的主战场。
-
ExpertBert: Pretraining Expert Finding -
Efficient Non-sampling Expert Finding -
Deep View-Temporal Interaction Network for News Recommendation
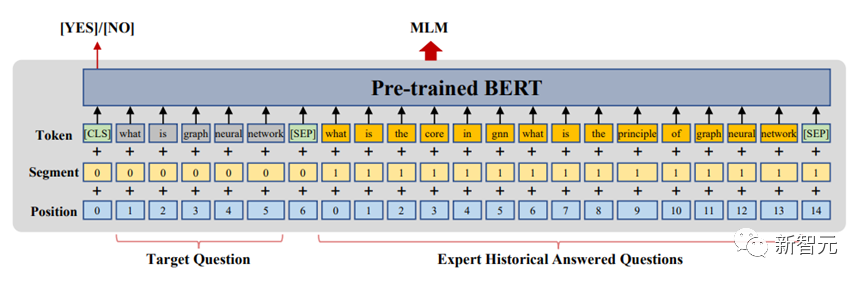
ExpertBert:用户粒度预训练框架,快速匹配高质量回答
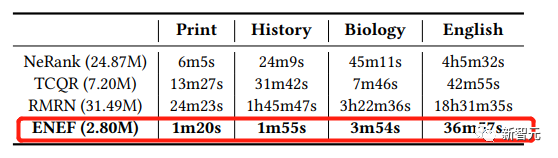
ENEF:高性能、低计算复杂度的「非采样」专家发现模型
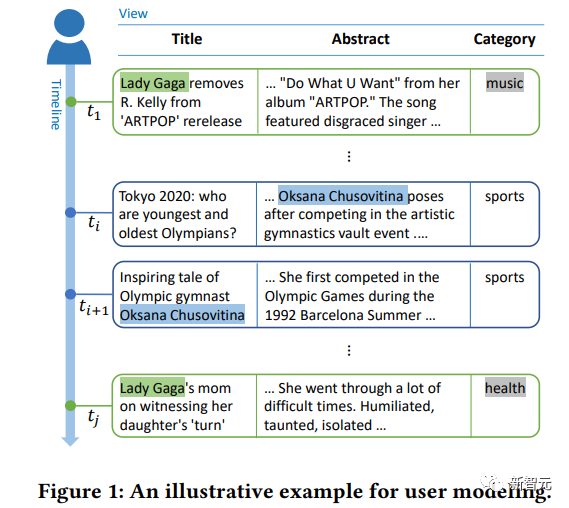
DeepVT:视图与时序模式交互,全面、精准预测用户画像
写在后面


登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月22日
Arxiv
0+阅读 · 2022年11月22日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月22日
Arxiv
0+阅读 · 2022年11月22日