ECCV 2020 | 利用多相机处理严重遮挡下的行人检测和保持社交距离
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:侯云钟
https://zhuanlan.zhihu.com/p/196771711
本文已由原作者授权,不得擅自二次转载
本文介绍澳洲国立大学郑良老师实验室在ECCV 2020上的新工作《Multiview Detection with Feature Perspective Transformation》。一直以来,遮挡问题严重影响了识别、检测等诸多计算机视觉系统的性能。在这篇文章中,作者提出的MVDet模型通过联合考虑多个相机,极大缓解了遮挡对检测系统的影响;此外,文章还提出了一个新的仿真数据集MultiviewX。此外,文章中提出的多相机检测模型,也可以应用在保持社交距离(social distancing)中,对抗击疫情提供技术上的支持。

题目:Multiview Detection with Feature Perspective Transformation
作者:Yunzhong Hou, Liang Zheng, Stephen Gould
论文地址:https://arxiv.org/abs/2007.07247
主页:https://hou-yz.github.io/publication/2020-eccv2020-mvdet
代码:https://github.com/hou-yz/MVDet
数据集:https://github.com/hou-yz/MultiviewX

真实数据集Wildtrack上效果可视化

仿真数据集MultiviewX上效果可视化
多相机(multi-view)系统

在一个多相机系统中,包含多个同步、有公共视野、标定好的相机。在多相机检测系统中,由于相机参数已知,可以通过假设行人3D包围框(3D bounding box)的直径和高度,计算得到每个相机中的2D包围框(2D bounding box)。因此,多相机检测一般在地面(俯瞰)上评估行人的检测效果。利用多相机进行检测,有两个亟待解决的问题:
如何联合考虑多个相机的信息?
如何联合考虑地面上相邻位置,以做出联合判断?(对于不清楚的位置,如果周围没有其他人,则大概率该位置无人;若周围十分拥挤,则大概率该位置有人)
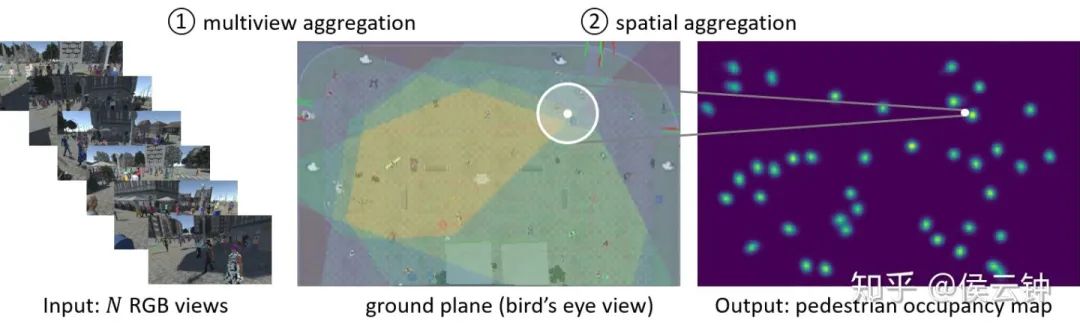
方法:MVDet网络
1. 联合考虑多相机

anchor-free的行人信息表示
之前工作一般利用相机参数和行人3D形状,计算每个相机内,对应每个位置的anchor box。之后,再利用anchor box feature(以及ROI pooling)表示该位置的行人信息。但是,这一类anchor box形状不一定准确,导致聚合的信息不准(上图白衣女士坐在地上,导致anchor box feature很大一部分都在描述背景而非行人,严重影响检测)。
本文中,作者使用了一套anchor-free的信息表示方法。对于地面上每个位置,直接选取该位置的feature vector作为代表(该feature vector也同时表示站在该处行人的信息)。
利用feature map的投影变换进行多相机信息聚合
利用相机参数,可以得到图片像素和地面上坐标的对应关系。通过一组地面坐标和一组图像像素的对应,可以建立出一张参数化的sampling grid。
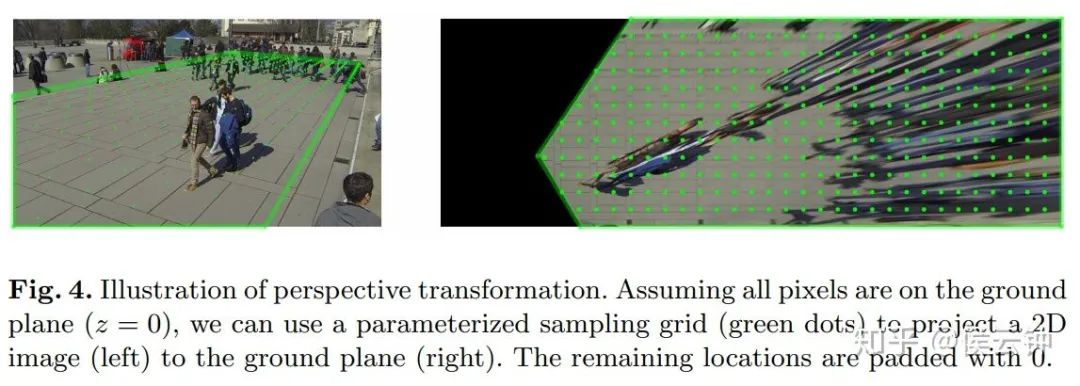
该sampling grid完全可导。上图给出了利用sampling grid对RGB图像投影的实例。同理,我们可以对feature map进行投影;并通过连接(concatenate)多张投影后的feature map,完成anchor free的多相机信息聚合。
2. 联合考虑地面相邻位置
通过大卷积核卷积联合考虑地面相邻位置

之前工作一般利用条件随机场(conditional random field)完成这一任务。本文中,作者使用拥有大卷积核(大感受野)的卷积,完成这一操作,并得到全卷积的检测器MVDet。
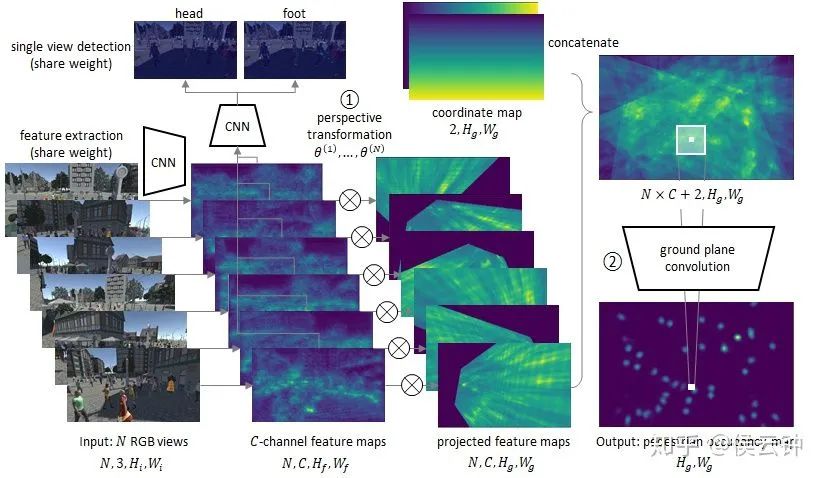
3. 训练及监督
训练中,MVDet主要使用地面上行人位置图作为监督。为了进一步提高性能,可以加入单目检测作为辅助(可选)。
4. 测试
测试时在网络输出后加入非极大值抑制(NMS)即可。
实验
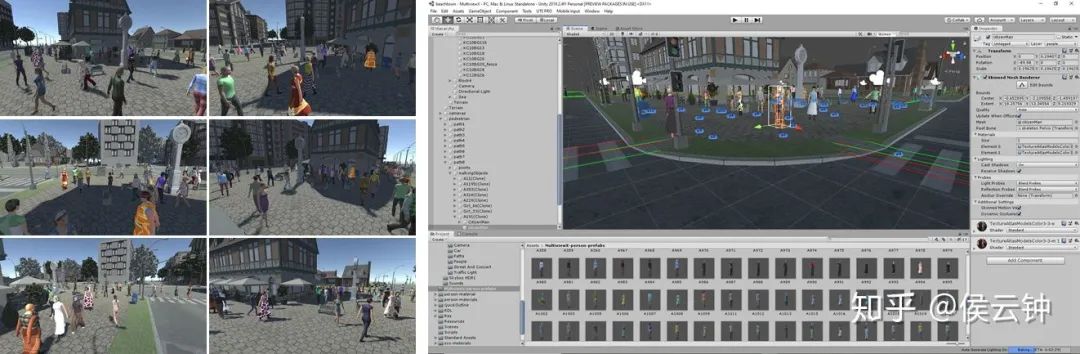
1. 仿真数据集MultiviewX
利用Unity引擎以及PersonX 数据集 中提供的3D行人模型,我们创建了一个3D仿真multiview detection数据集,MultiviewX。
https://github.com/hou-yz/MultiviewX
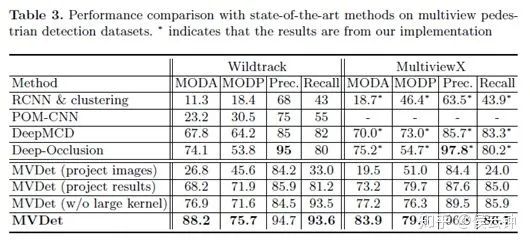
2. 性能
在真实数据集上,MVDet超出之前state-of-the-art方法14.1% MODA性能。相比使用Faster RCNN进行单目检测(RCNN projected),MVDet性能更是远远超出。
3. 帮助保持社交距离
由于MVDet直接输出地面上的行人位置图,且对遮挡比较鲁棒,该方法也可以帮助保持社交距离。
感谢观看!
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


