学界 | 普适注意力:用于机器翻译的2D卷积神经网络,显著优于编码器-解码器架构
选自arXiv
作者:Joe Davison
机器之心编译
参与:李诗萌、张倩
现有的当前最佳机器翻译系统都是基于编码器-解码器架构的,二者都有注意力机制,但现有的注意力机制建模能力有限。本文提出了一种替代方法,这种方法依赖于跨越两个序列的单个 2D 卷积神经网络。该网络的每一层都会根据当前生成的输出序列重新编码源 token。因此类似注意力机制的属性适用于整个网络。该模型得到了非常出色的结果,比当前最佳的编码器-解码器系统还要出色,而且从概念上讲,该模型也更加简单、参数更少。
引言
深度神经网络对自然语言处理技术造成了深远的影响,尤其是机器翻译(Blunsom, 2013; Sutskever et al., 2014; Cho et al., 2014; Jean et al., 2015; LeCun et al., 2015)。可以将机器翻译视为序列到序列的预测问题,在这类问题中,源序列和目标序列的长度不同且可变。目前的最佳方法基于编码器-解码器架构(Blunsom, 2013; Sutskever et al., 2014; Cho et al., 2014; Bahdanau et al., 2015)。编码器「读取」长度可变的源序列,并将其映射到向量表征中去。解码器以该向量为输入,将其「写入」目标序列,并在每一步用生成的最新的单词更新其状态。基本的编码器-解码器模型一般都配有注意力模型(Bahdanau et al., 2015),这样就可以在解码过程中重复访问源序列。在给定解码器当前状态的情况下,可以计算出源序列中的元素的概率分布,然后使用计算得到的概率分布将这些元素的特征选择或聚合在解码器使用的单个「上下文」向量中。与依赖源序列的全局表征不同,注意力机制(attention mechanism)允许解码器「回顾」源序列,并专注于突出位置。除了归纳偏置外,注意力机制还绕过了现在大部分架构都有的梯度消失问题。
但现有的注意力机制建模能力有限,一般是对源表征的权重求和(Bahdanau et al., 2015; Luong et al., 2015),在这些模型中,这里的权重是源元素和目标元素的简单匹配。注意力模块将相同的源词编码重新组合,在解码时就无法重新编码或重新解释源序列。
为了克服这些局限,我们提出了一种基于深度 2D 卷积神经网络的可替代神经 MT 架构。源序列和目标序列中的位置的积空间定义了用于定义网络的 2D 网格。屏蔽卷积核,使其无法访问源自目标序列未来 token 的信息,从而获得与图像和音频波形中常用的生成模型(Oord et al., 2016a,b)类似的自回归模型(autoregressive model)。相关说明请参见图 1。
这种方法允许我们根据一堆 2D 卷积层学到深度特征的层次关系,并从训练过程中的并行运算受益。我们的网络的每一层都能根据目前生成的目标序列计算出源 token 的特征,并利用这些特征预测出下一个输出 token。因此,我们的模型通过构造类似注意力的能力,使这种能力适用于网络的所有层,而不是「添加」一个注意力模型。
我们在 IWSLT 2014 的德译英 (De-En) 和英译德 (En-De) 任务上通过实验验证了模型。我们改良了目前最佳的具备注意力机制的编码器-解码器模型,同时,从概念上讲我们的模型更加简单,参数更少。
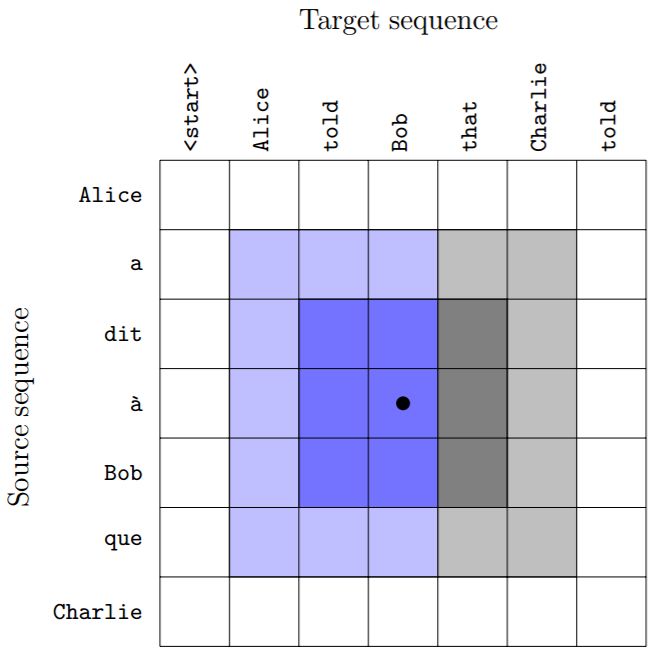
图 1:我们的模型中的卷积层隐藏了 3*3 的卷积核,这样就可以只根据之前的输出计算特征。在一层(深蓝色)和两层(浅蓝色)之后的感受野的图示,还有正常的 3*3 卷积核视野的隐藏部分(灰色)。
论文:Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction

论文链接:https://arxiv.org/pdf/1808.03867v1.pdf
现有的当前最佳机器翻译系统都是基于编码器-解码器架构的,首先要对输入序列进行编码,然后根据输入的编码生成输出序列。这两者都有注意力机制,注意力机制可以根据解码器的状态重新组合源 token 的固定编码。我们提出了一种可替代的方法,这种方法依赖于跨越两个序列的单个 2D 卷积神经网络。我们的网络的每一层都会根据当前生成的输出序列重新编码源 token。因此类似注意力机制的属性适用于整个网络。我们的模型得到了非常出色的结果,比当前最佳的编码器-解码器系统还要出色,而且从概念上讲我们的模型也更加简单、参数更少。
卷积网络最广为人知的应用是在视觉识别模型中(Oord et al., 2016a; Salimans et al., 2017; Reed et al., 2017; Oord et al., 2016c)。近期也有一些将卷积网络引入自然语言处理中的研究。第一个卷积方法是编码由堆叠的词向量组成的长度可变的序列,运用 1D 卷积,再用最大池化操作聚合(Collobert and Weston, 2008; Kalchbrenner et al., 2014; Kim, 2014)。就序列生成而言,Ranzato 等人(2016)、Bahdanau 等人(2017)以及 Gehring 等人(2017a)的研究将卷积编码器和 RNN 解码器融合。Kalchbrenner 等人(2016b)首次在编码器-解码器模型中引入了完整卷积过程,但他们没有对当前最佳的循环架构中加以改进。Gehring 等人(2017b)在编码器和解码器模块中用了带有线性门控单元的 1D CNN(Meng et al., 2015; Oord et al., 2016c; Dauphin et al., 2017)进行机器翻译,得到的结果比深度 LSTM 要好。
基于 CNN 和基于 RNN 的模型之间的区别在于,基于 CNN 的模型的时序连接被置于网络的层之间,而非层内。相关概念图请参见图 2。这种在连接上显而易见的微小差异可能造成两种重要的结果。第一,这种连接使可视域在卷积网络的层间线性增长,但在循环网络的层中则是无边界的。其次,RNN 中的激活值只能以序列方式计算,但在卷积网络中则可以在时序维度上并行计算。
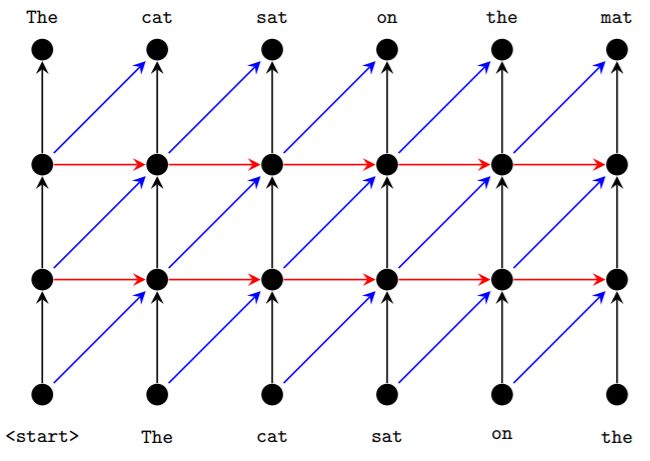
图 2:有两个隐藏层的解码器网络拓扑结构图示,底部和上部的节点分别表示输入和输出。RNN 用的是水平方向的连接,卷积网络用的是对角方向的连接。这两种方法都用了垂直连接。参数可跨时间步(水平方向)共享,但不跨层(垂直方向)共享。
实验结果
我们将在本节中探索模型中的几个参数所造成的影响,这几个参数有:token 嵌入维度、深度、增长率和卷积核大小。我们也在源维度中对不同的聚合机制进行了评估,这些聚合机制有:最大池化、平均池化以及注意力机制。
我们在每个给定的设置下都训练了五个初始值不同的模型,并报告 BLEU 分数的平均值和标准差。我们还用了与 Vaswani 等人(2017)类似的方式,根据训练的系统时间和 GPU 的单精度规格估计了每个模型的参数数量以及训练过程中的计算成本。
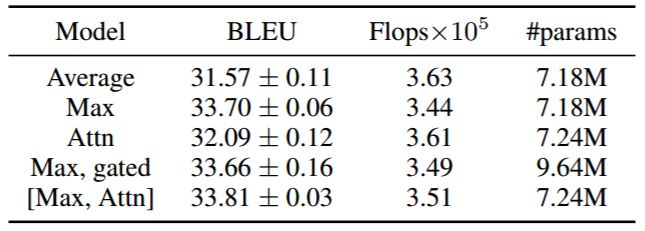
表 1:通过不同池化操作以及使用门控卷积单元训练的模型(L=24,g=32,ds=dt=128)。
从表 1 可知,与用平均池化相比,在源维度上用最大池化时 BLEU 可以提高约 2 个点。用公式(3)中的
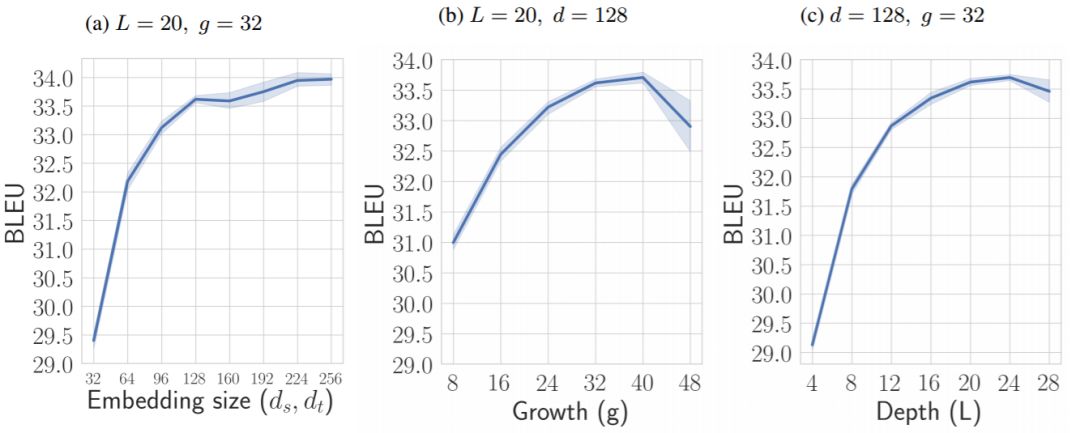
图 4:token 嵌入大小、层数(L)及增长率(g)产生的影响。
图 4 所示是 token 嵌入大小、网络增长率及网络深度所产生的影响。token 嵌入大小和增长率 g 控制的是沿着源维度通过池化操作传递的特征数量,可用于 token 预测。在源序列和目标序列中用的 token 嵌入大小都相同,即 d=d_t=d_s,网络预测出的 token 的特征的总数量是 fL=2d+gL。我们可以从图 4 中了解到,token 嵌入大小在 128 到 256 之间时,BLEU 分数在 33.5 和 34 之间。嵌入较小会迅速降低模型性能,嵌入为 64 时会使模型性能降至 32.2。增长率(g)对模型表现有重要影响,将其从 8 提高到 32,BLEU 可以增长超过 2.5 个点。g=32 之后模型性能达到饱和,模型只有微乎其微的改善。在模型性能和计算损失中进行取舍,我们在剩余的实验中都将采用 g=32。网络的深度对其表现也有重要的影响,当网络深度从 8 增长到 24 时,BLEU 分数增长了约 2 个点。当越过这个点后,由于过拟合,模型表现下降,这意味着我们在构造更深的网络之前应该增加 dropout 值或添加另一级正则化。我们的模型的感受野是由其深度和卷积核的大小控制的。在表 2 中,我们注意到在复杂程度相同、层数较少的情况下,狭窄的感受野比大一点的感受野表现更好,例如,将(k=3,L=20)和(k=5,L=12)相比较,或将(k=5,L=16)和(k=7,L=12)相比较。
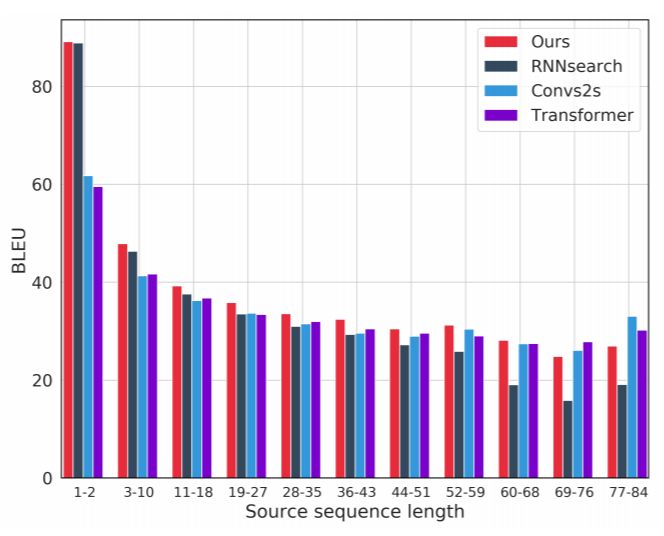
图 5:不同的句子长度得到的 BLEU 分数。
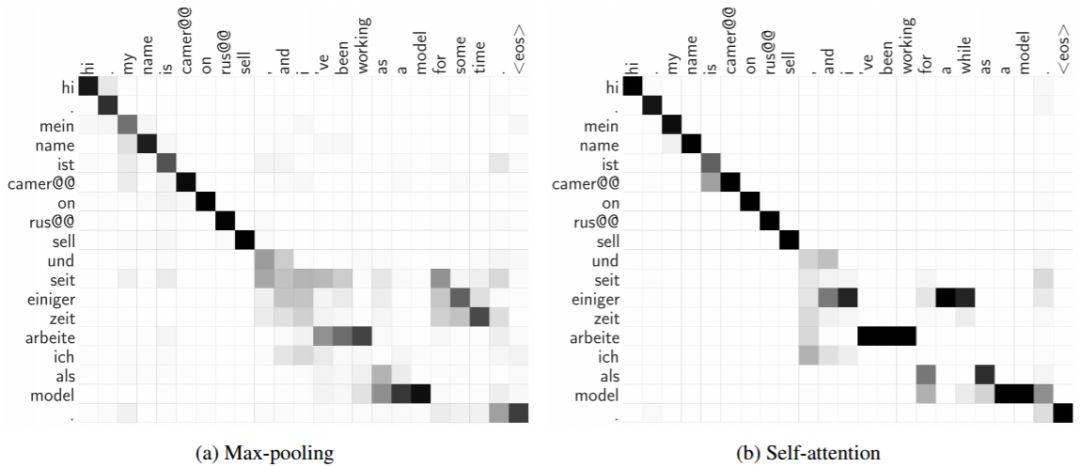
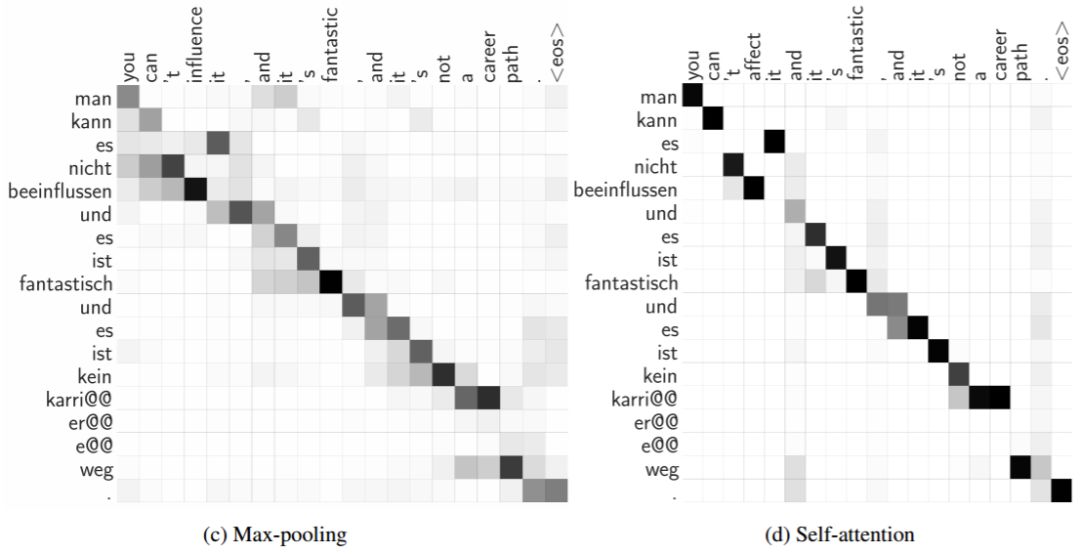
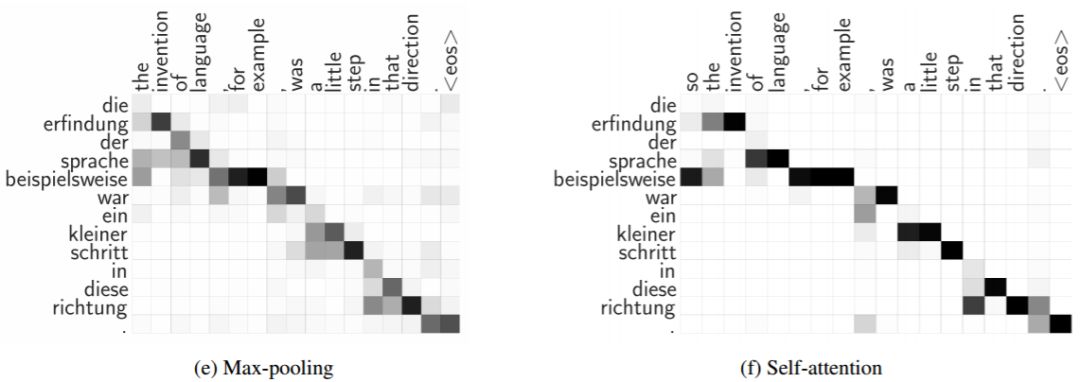
图 6:我们的普适注意力模型(Pervasive Attention model)生成的隐式 BPE 的 token 级对齐。在最大池化聚合中我们将式(7)中的 α 可视化,而在自注意力聚合中我们可视化的是式(8)中的权重 ρ。
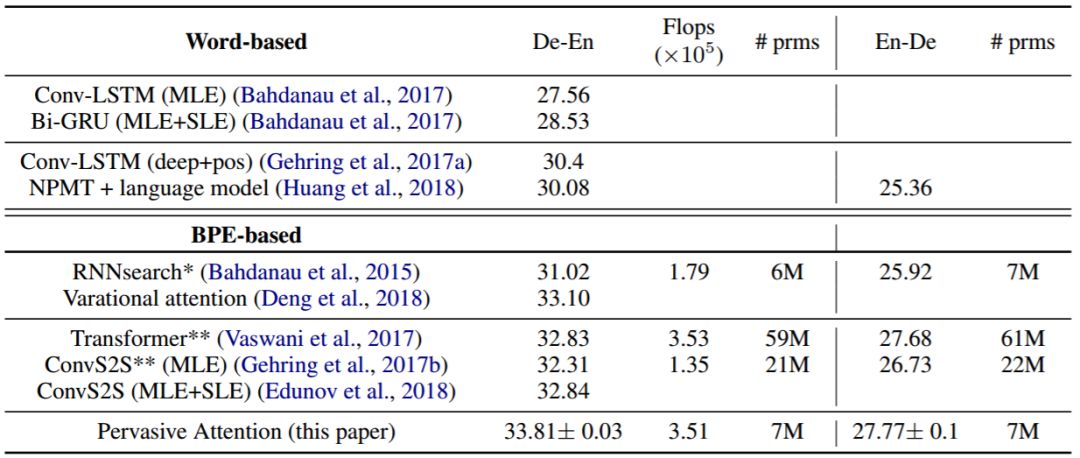
表 3:与目前最佳的 IWSLT 德译英的机器翻译结果进行比较。(*):用我们的方法得到的结果。(**):用 FairSeq(Gehring et al., 2017b)得到的结果。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



