CVPR 2020 Oral|解读X3D,Facebook视频理解/行为识别新作
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
Facebook FAIR 于CVPR 2020 提出了轻量级 X3D 行为识别模型,采用4.8\x~GFLOPs 和 5.5\x~ parameters就可以取得与之前SOTA媲美的结果。
X3D: Expanding Architectures for Efficient Video Recognition
论文链接:https://arxiv.org/abs/2004.04730
PS;这篇工作作者就Christoph Feichtenhofer老哥一个人,也太秀了吧!
不过致谢(后援团)中出现了下面几位(瑟瑟发抖.jpg):

-
本文主要对 2D conv 在不同维度进行expand。基本思路在EfficientNet延伸,在3D卷积中对各个系数进行调整:video clip 长度,帧率,图像特征分辨率,宽度和深度。 -
受到ML中特征选择方法的启发,设计 stepwise network expansion approach,每个step中,对各个维度单独扩张分别训练一个model,选择扩张效果最好的维度。大大减小搜索优化的复杂度 -
参考坐标下降法,每次对单个维度进行expand -
最终的model very thin(特别是使用了channel-wise separable convolution),同时block的 width 非常小。
Abstract
This paper presents X3D, a family of efficient video networks that progressively expand a tiny 2D image classification architecture along multiple network axes, in space, time, width and depth. Inspired by feature selection methods in machine learning, a simple stepwise network expansion approach is employed that expands a single axis in each step, such that good accuracy to complexity trade-off is achieved. To expand X3D to a specific target complexity, we perform progressive forward expansion followed by backward contraction. X3D achieves state-of-the-art performance while requiring 4.8\x~and 5.5\x~fewer multiply-adds and parameters for similar accuracy as previous work.
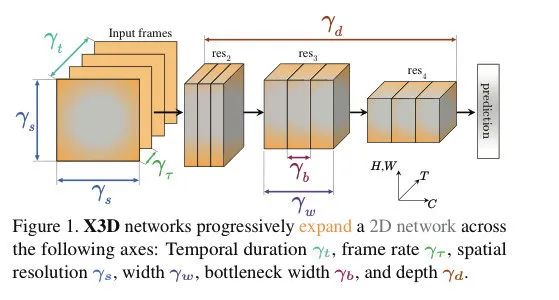
expand model from the 2D space into 3D spacetime domain.
-
temporal duration 采样的帧数 -
frame rate 对 video 的采样帧率(间隔) -
spatial resolution -
network width -
bottleneck width -
depth
坐标下降法 Coordinate Descent
与梯度优化算法沿着梯度最速下降的方向寻找函数最小值不同,坐标下降法依次沿着坐标轴的方向最小化目标函数值。
它的核心思想是将一个复杂的优化问题分解为一系列简单的优化问题以进行求解。我们知道,对高维的损失函数 求最小值有时并不是一件容易的事情,而坐标下降法就是迭代地通过将大多数自变量 固定(即看作已知常量),而只针对剩余的自变量 ,求极值的过程。这样,一个高维的优化问题就被分解成了多个一维的优化问题,从而大大降低了问题的复杂性。
关于坐标下降法,以下几点需要注意:
-
坐标轴的顺序可以是任意的,可以使用{1,2,...,n}的任何排列 -
坐标下降法与梯度下降法的不同之处在于不需要计算目标函数的梯度,每次迭代 只用在单一维度上进行线性搜索,但是坐标下降法只适用于 光滑函数,如果是非光滑函数可能会 陷入非驻点从而无法更新。 -
严格的坐标下降法,即每次仅沿着单个坐标轴的方向寻找函数极小值。与之相对应的是 块坐标下降法,即每次沿着多个坐标轴的方向(超平面)取极值,它通过对变量的 子集进行同时优化,把原问题分解为多个子问题。在下降的过程中更新的次序 可以是确定或随机的,如果是确定的次序,我们可以设计某种方式,或是周期或是贪心的方法选择更新子集。
考虑一个优化任务:
一个块坐标下降的通用框架如下图所示:
-
将新的 的值立马代入后续 的计算很重要,否则的话有可能导致不收敛。
特征选择
-
使用贪心的方法找到能提升 performance 的relevant features -
删去对performance最小的feature
find relevant features to improve in a greedy fashion by including (forward selection) a single feature in each step, or start with a full set of features and aim to find irrelevant ones that are excluded by repeatedly deleting the feature that reduces performance the least (backward elimination).
X2D baseline

-
使用了channel-wise separable convolution -
Further, the temporal convolution in the first stage is channel-wise. -
Similar to the SlowFast pathways , the model preserves the temporal input resolution for all features throughout the network hierarchy.There is no temporal downsampling layer (neither temporal pooling nor time-strided convolutions) throughout the network, up to the global pooling layer before classifcation.Thus, the activations tensors contain all frames along the temporal dimension, maintaining full temporal frequency in all features.
Expansion operations
文章中设计了以下几种Expansion operations:
-
保持sample的clip长度( clip duration)不变,提升采样帧率 ,从而增加 ( ), -
同时增加sample的clip长度( longer input duration)和采样帧率 ( higher frame-rate ),从而增加 ( ) -
提升采样的spatial resolution ( ) -
提升网络中每个stage的block的数量 ( ) -
提升主要的stage 的channel数量 times ( ) -
expand Bottleneck 中 channel-wise separable conv 和 conv 的channel数量 ( )
Progressive Network Expansion
Forward expansion
定义
-
expansion criterion function ——accuracy of a model expanded by current expansion factors -
complexity criterion function ——floating point operations
only changes a single one of the expansion factors while holding the others constant; therefore there are only different subsets of to evaluate.
expansion-rate ,粗略地讲,每增加一个step,target complexity 缩放的倍数,
使用坐标下降法 Coordinate Descent 进行优化
expansion 的代价非常小
expansion is simple and cheap e.g. our low-compute model is completed after only training 30 tiny models that accumulatively require over 25× fewer multiply-add operations for training than one large state-of-the-art network
Backward contraction
如果缩放后的model超过了target complexity(GFLOPs), 对缩放因子expansion-rate大小进行略微的压缩,比如略小于2
优化结果
-
step 1:由于 使用了channel-wise separable convolution,比较高效,thus are economical to expand at first . -
step 2: extends the temporal size of the model from one to two frames (expanding and is identical for this step as there exists only a single frame) -
step 3:expand spatial resolution -
step 4:expand depth -
step 5:expand temporal duration ( X3D-XS) -
step 6:expand temporal resolution -
step 7:expand temporal duration ( X3D-S) -
step 8:expand spatial resolution ( X3D-M) -
step 9:expand spatial resolution -
step 10 : expand the depth of the network, ( X3D-L) -
step 11: expand the width ( X3D-XL)
注意:
-
增加 input spatial resolution 后要紧接着增加depth ,(例如 step 3 -> step 4 和 step 8 step 9->step 10) -
An expansion of the depth after increasing input resolution is intuitive, as it allows to grow the filter receptive field resolution and size within each residual stage. -
A surprising finding of our progressive expansion is that networks with thin channel dimension and high spatiotemporal resolution can be effective for video recognition.
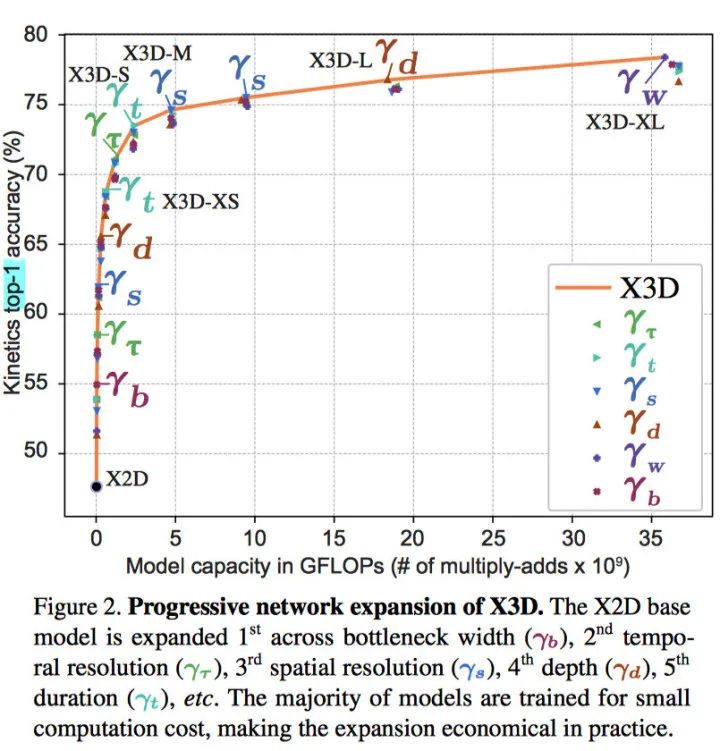
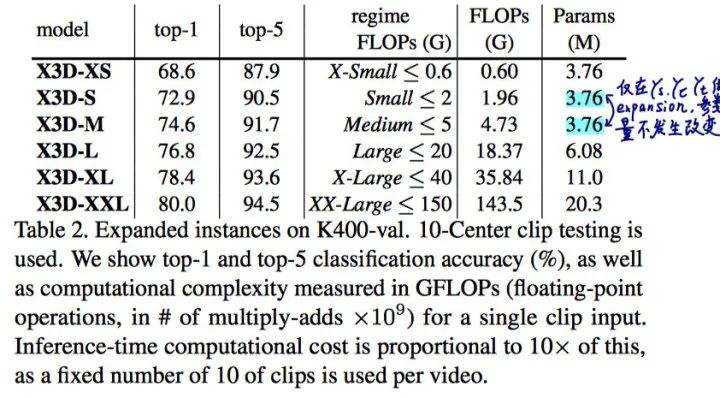
X3D-S is a lower spatiotemporal resolution version of X3D-M therefore has the same number of parameters,



The models in (a) and (b) only differ in spatiotemporal resolution of the input and activations and (c) differs from (b) in spatial resolution, width, , and depth, See Table 1 for . Surprisingly -XL has a maximum width of 630 feature channels.
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~





