基于Milvus的向量搜索实践(三)
摘要:本系列文章分为三部分,第一篇主要讲基本概念、背景、选型及服务的整体架构;第二篇主要讲针对低延时、高吞吐需求,我们对Milvus部署方式的一种定制;本篇主要讲实现数据更新、保证数据一致性,以及保证服务稳定及提高资源利用率做的一些事情。
1.数据存储方案
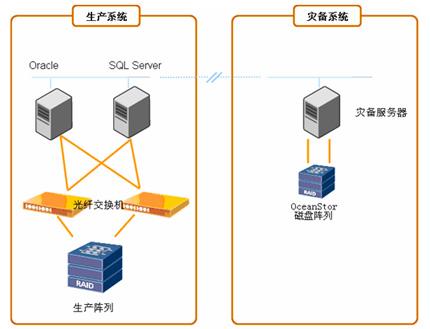
第二篇中我们解决了部署方案的问题,接下来要考虑的是数据如果存储。在分布式部署情况下,Milvus是需要使用Mysql来存储元数据的[1]。Milvus分布式部署时,数据只会写一份,如何实现数据的分布式使用呢?基本的思路有两种:1)内部数据复制,典型的例子如elasticsearch[2],kafka[3][4];2)数据存储在共享存储上,如NFS,glusterfs,AWS EBS,GCE PD,Azure Disk等,都提供了kubernetes下的支持[5]。两种思路没有本质的区分,前者是应用自己实现了数据的存储及高可用(多副本);缺点是应用复杂度增加;优点是具有更高的灵活性。后者依赖于已有的通用的存储方案,只需要关注自身的核心功能,复杂度降低了,而且更方便在多种存储方案下切换。在云计算技术发展的今天,后者有一定的市场。Milvus选用了共享存储来存储数据。为了实现存储的统一及高可用,我们把单个Milvus集群所涉及到的所有数据存储(mysql数据文件和milvus的存储),都放到共享存储中。我们使用了glusterfs做为共享存储的具体实现。整体的存储方案如图1。
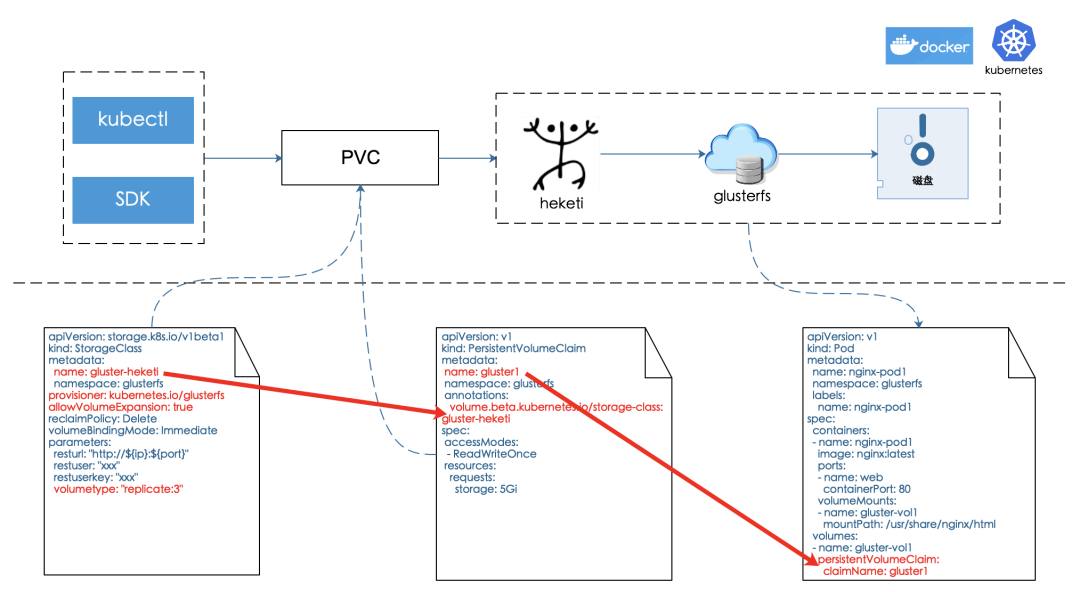
为了解决集群的自动创建,减少沟通维护成本以及物理资源的最大利用(Milvus是cpu密集型,glusterfs是存储密集型),我们将glusterfs同Milvus混合部署。我们参考实现了glusterfs在kubernetes下的超融合(Full Hyper-Convergence)部署,并借助heketi[7]实现了存储资源的动态分配。另外,在部署过程中,还需要注意的是glusterfs需要一个独立的磁盘/分区,你也可以使用loop设备[8];在部署过程中,因为各种原因,不可避免需要重置部署,这时你需要清除脏数据,可以参照以下命令。
# 清除逻辑卷
lvscan | awk 'system("lvremove -y "$2 )'
# 清除卷分组
vgscan | grep group | awk -F '"' '{system("vgremove "$2)}'
glusterfs在kubernetes下的部署架构如图2所示,glusterfs服务可以分布在kubernetes的多个node上,我们可以根据存储的需求增加结点。
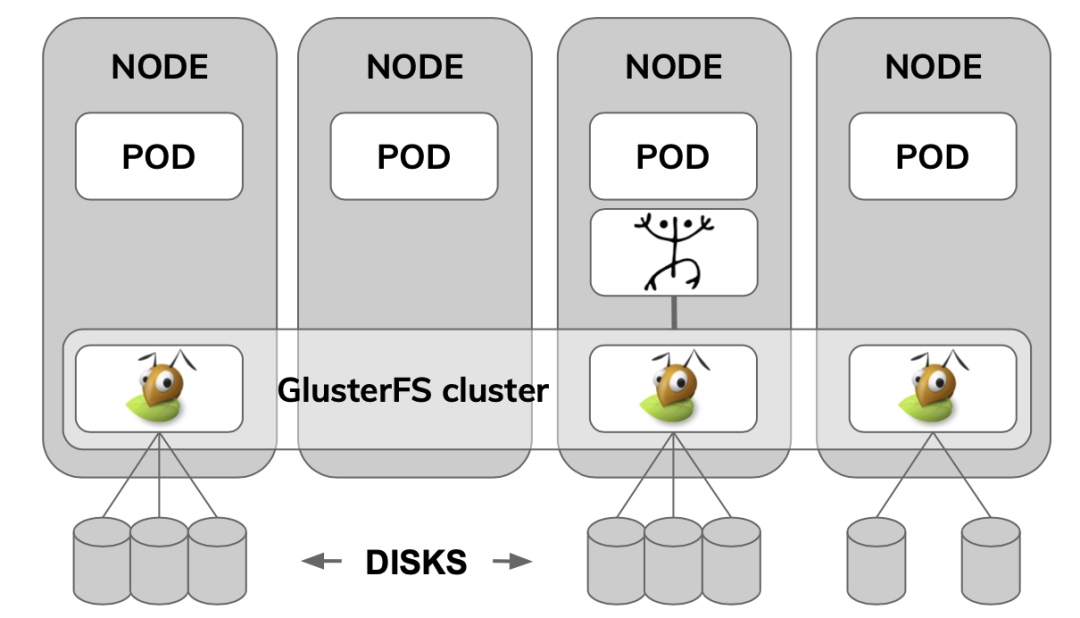
实现了glusterfs在kubernetes的部署,我们更关心的是glusterfs本身的可用性:1)glusterfs是否可以实现数据的不丢失/高可用;2)glusterfs是否可以存储大批量数据。
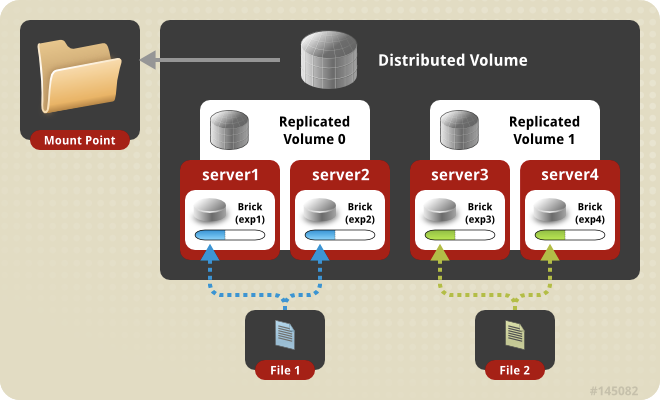
由[9]可知,glusterfs有Distributed volume、Replicated volume、Distributed Replicated volume、Dispersed Glusterfs Volume、Distributed Dispersed Glusterfs Volume 5种类型的卷,其中Distributed volume可以解决数据分布存储数据,从而实现大批量数据的存储,Replicated volume通过数据的冗余来实现高可用,Distributed Replicated volume同时解决了高可用和大批量数据存储的问题,Dispersed Glusterfs Volume、Distributed Dispersed Glusterfs Volume是分别对Replicated volume、Distributed Replicated volume的优化,借助一种前向纠错码(erasure code[10])实现数据存储成本的降低。图3给出了Distributed Replicated volume类型卷的结构图。
最后,借助heketi[7]、以及kubernetes的StorageClass[11]、PVC[12],我们屏蔽掉了以上glusterfs卷创建、扩容、销毁的细节,比较完美解决了数据存储的问题。
2.数据更新方案
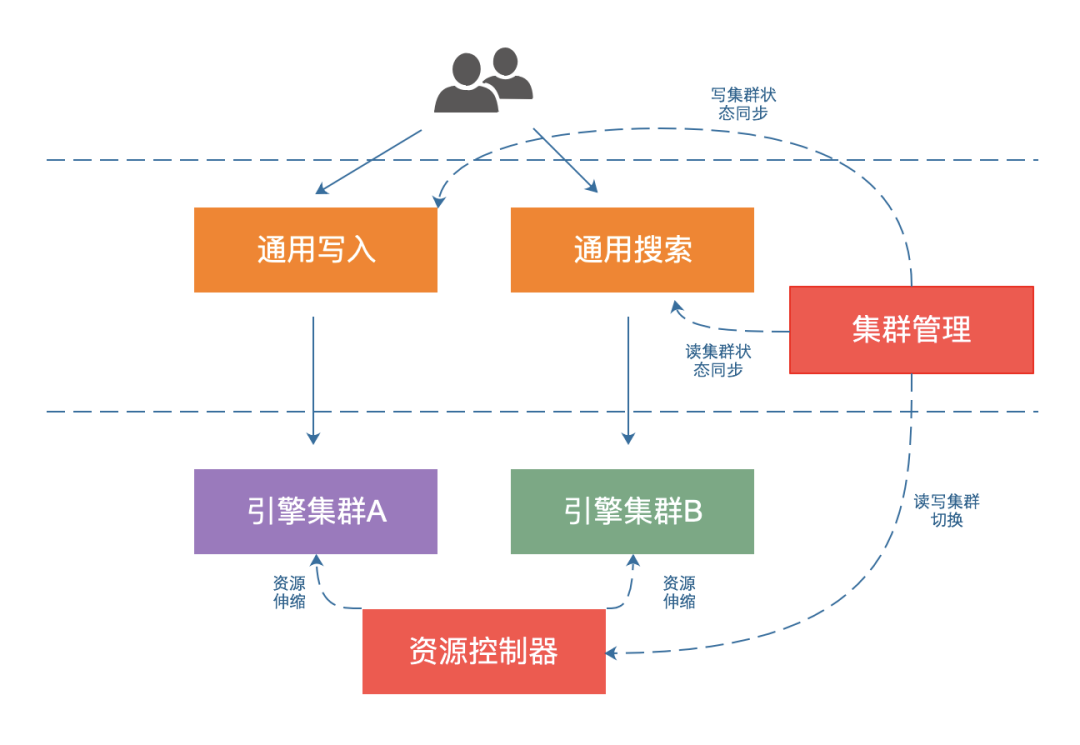
数据更新分为实时更新和批量/全量更新两种,Milvus本身是支持实时更新的,但是数据更新时需要重新创建索引,而索引构建需要消耗大量的CPU资源,从而引发服务整体的稳定性问题。综合考虑稳定性,以及业务的数据更新场景(绝大多数是T+1更新策略),我们采用了如图4所示的数据更新策略。
我们使用了A、B两组对等的资源(可以是同机房、跨机房)作为底层Milvus引擎,在引擎的外层,我们实现了读写分离,同一时刻,A、B集群只会承担读、写角色中的一个。在引擎外层,我们维护了读写角色与A、B集群的对照表;数据更新时,我们操作写集群完成数据写入、索引构建,写集群索引构建完成后,切换成角色成读集群;数据更新时出现任何问题,不影响读集群。另外,在读写集群都有正常数据(数据更新差一天)情况下,如果读集群出现问题,写集群可以随时切换成读集群,从而在实现数据更新的同时还实现了互备。由于底层资源使用对等的两份,如何没有特别的处理,不可避免会造成资源的浪费,后面内容会专门讨论解决这个问题的方案。
3. 数据一致性保证
解决了数据更新的问题,另一个问题接踵而来:如何保证数据更新时一致性?如何做到以下三点:1)数据量不多不少;2)数据不重复;3)旧数据不会覆盖新数据。
由于我们的前提是数据全量更新,在业务数据本身不重复的情况下,不会存在数据覆盖问题,我们重点讨论前两点。
3.1 数据量不多不少
我们总体思路是,明确写入操作开始和结束(提供专门的api实现),在结束时检验数据量。数据全量写入开始时,我们清空数据,在数据全量写入结束时,判断数据写入的实际数量与预期是否一致,如果一致,我们可以确认数据数量是没有问题的。数据写入操作可以并发进行,以保证整体的写入吞吐量,但是需要使用方保证,结束写操作需要在所有写入操作之后。另外,为了兼顾数据一致性、引擎稳定性以及服务整体可用,可以设定一致性错误容忍度(比如可以容忍多少比例的数据量差异)。
3.2 数据不重复
我们假设,写入Milvus的请求返回成功,数据写入成功;请求返回失败,数据写入失败。
我们写入Milvus时,通过同步阻塞来实现数据不重复。具体地,写入时,我们设定写入超时时间大于引擎内部写入请求的处理时间,也就是留出足够时间来让引擎返回成功/失败(即感知到引擎因为各种问题引起的失败);如果失败,我们会执行一次删除操作(删除可能写入的指定数据),并进行重试(如果重试指定次数还未成功,会由数据量校验来决定是否全量更新成功)。
除了以上方案,还有两种可选的方案:
-
外部维护一个数据是否已经写入的标识,数据写入前进行判断,如果已经存在,就不再写入。 -
Milvus自身支持upset(如果不存在就插入,如果存在就更新)操作。
方案1在实现同步阻塞方案效果的基础上,还兼顾了使用方与向量服务之间的可能网络异常(写入成功,但是没有返回给业务方,业务方重试,导致数据写入重复;Milvus在0.8.0下不能去重);但是,增加了额外的开销,系统的复杂度也随之增加。
方案2是一个更优秀的方案,把去重的工作外部透明了。当然,这个依赖于Milvus的版本迭代[13]。
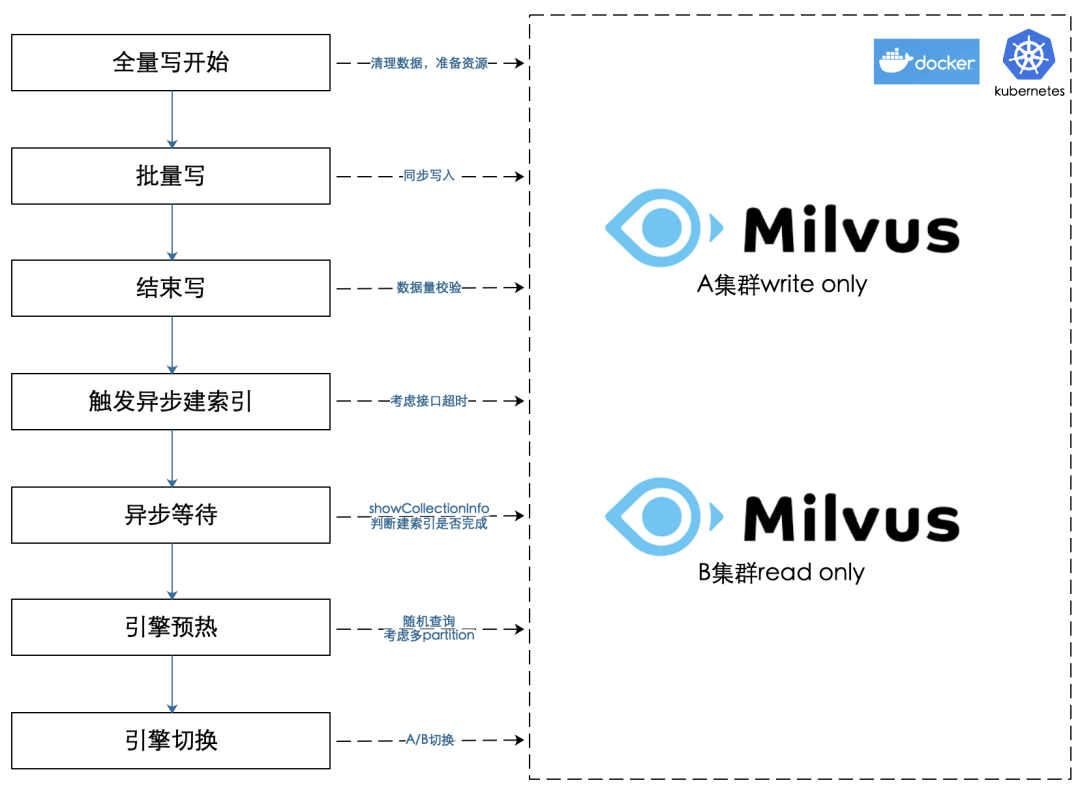
图5展示了数据T+1全量更新的步骤:
-
全量写开始 - 删除Milvus中旧数据,清除内外id映射数据,扩容Milvus写实例。
-
批量写 - 向Milvus写实例批量写入数据,失败重试。
-
结束写 - 检验数据量是否符合预期。
-
触发异步建索引 - 调用Milvus建索引接口(数据量大时建索引接口可能会阻塞)。
-
异步等待 - 调用Milvus建索引接口返回(超时/完成),循环判断是否建索引成功(可以根据showCollectionInfo接口的返回判断)。
-
引擎预热 - 让引擎把数据加载到内存中;多partition时需要遍历所有的partition才能保证所有数据都加载。
-
引擎切换 - A、B引擎集群角色互换,并把对应关系持久化;对原有的读集群缩容。
4.存活检测
在Milvus0.8.0使用过程中,多次出现cpu指令异常,导致Milvus服务退出的情况;但是,由于Milvus没有暴露存活检测的接口,Milvus Pod[14](在kubernetes下,可以认为是一个服务)还被认为可用,还会有流量被负载均衡到,从而引发外部使用报错。
解决方式很直接,我们需要给Milvus0.8.0增加存活检测的接口,并且在kubernets下配置上对Milvus的检测。由[15]可知,kubernetes有readinessProbe、livenessProbe两者存活检测的手段,前者用于检测服务是否正常启动,后者用于检测服务正式在正常运行,如果不正常,会有相应的重启策略。
readinessProbe、livenessProbe的具体实现有exec、httpGet、tcpSocket三种;exec定时到指定容器中执行一个shell命令;httpGet定时请求容器暴露的http接口;tcpSocket是定时请求容器暴露的socket端口;三者根据指定格式的返回结果来判断服务是否正常,根据Probe配置来决定是否重启。具体的配置可以参考[15]。
有了kubernetes的支持,我们剩下需要做的就是如何判断Milvus是否正常;幸运的是,Milvus虽然没有暴露kubernetes指定格式的Probe接口,但是它提供的server_status接口可以判断服务是否正常运行。接下来,我们需要做的,就是如何包装下这个接口,返回kubernetes指定的格式。
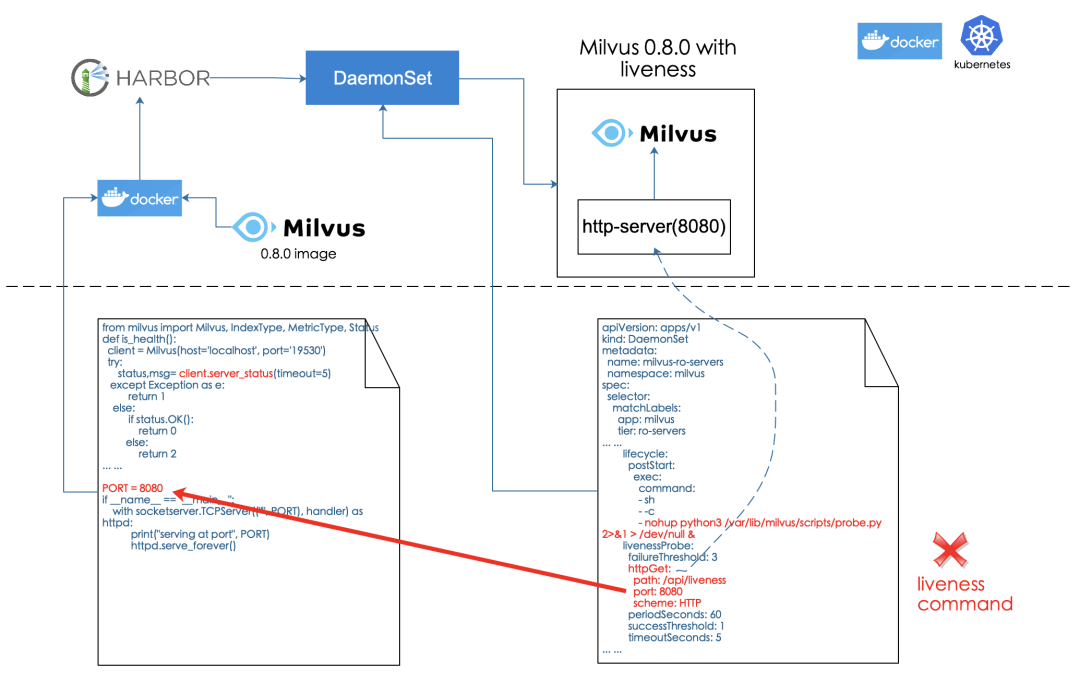
最直接、简单的方案是exec。我们给原生Milvus0.8.0版本的docker镜像增加了执行python脚本功能的能力,并把以下python脚本打包到镜像中,最后exec配置定时调用以下脚本。我们使用这个思路初步解决了问题,但是,在后续的测试验证过程中发现,当同一台机器上存在多个Milvus实例时,服务空转时就消耗了不少的cpu资源。我们由[16]可知,exec最终调用了docker的exec api[17],docker exec api在执行shell命令外,它还做了不少额外工作,从而导致对资源的消耗[18]。
from milvus import Milvus, IndexType, MetricType, Status
client = Milvus(host='localhost', port='19530')
try:
status,msg= client.server_status(timeout=10)
except Exception as e:
print('1')
else:
if status.OK():
print('0')
else:
print('2')
为了解决exec的问题,我们采用了图6的方案。基于以上的分析,我们把python脚本包装成一个http服务器,在容器启动时,将http服务器启动为一个常驻的进程,然后我们采用httpGet方案解决检测的问题。经过实践检验,该方案对性能和资源占用基本没有影响。
5.资源伸缩
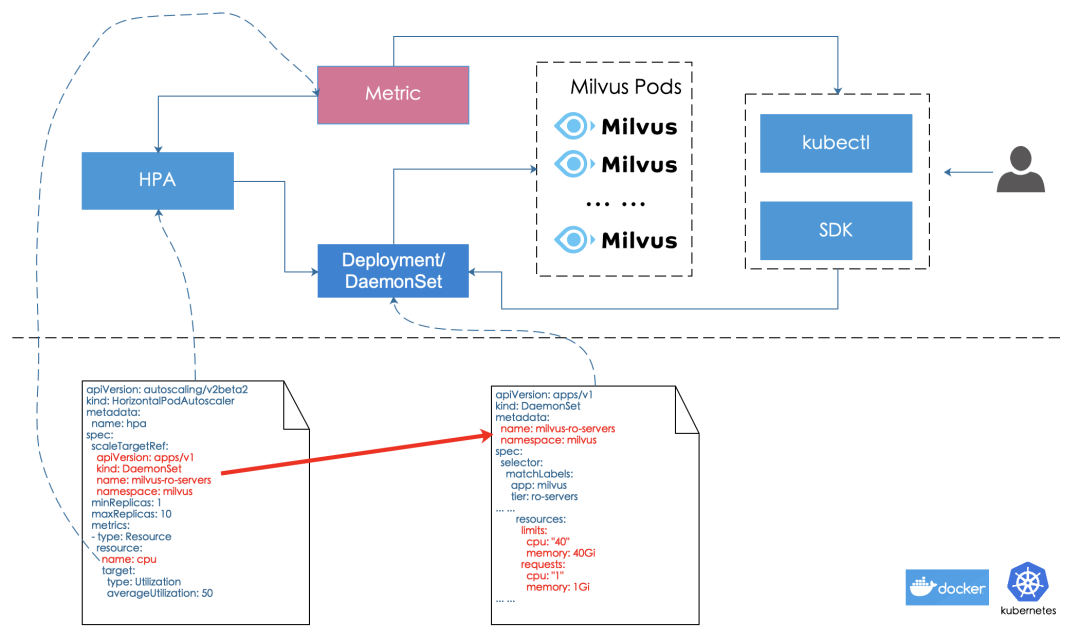
考虑到资源的充分利用(我们重点考虑cpu资源),我们有必要在不使用时,对资源进行回收。对资源的回收有手动和自动两方案,整体思路见图7。
5.1 手动
我们可以使用kubernetes的客户端工具kubectl来更改服务的副本数、cpu/内存占用;也可以通过kubernetes的sdk,把相应功能做为kubernetes管理工具集成到自已的应用中,从而实现资源的个性化调节。
5.2 自动
HPA(Horizontal Pod Autoscaler)[19]是kubernetes下支持的一种资源自动伸缩方案(以pod为单位),它参照监控数据提供的cpu资源利用率,根据配置的具体规则,来实现pod数自动调整。
6.参考文献
-
https://github.com/milvus-io/milvus -
https://www.elastic.co/guide/en/elasticsearch/reference/current/scalability.html -
http://kafka.apache.org/documentation/#min.insync.replicas -
http://kafka.apache.org/documentation/#replication -
https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner -
https://github.com/gluster/gluster-kubernetes/blob/master/docs/setup-guide.md -
https://github.com/heketi/heketi -
https://en.wikipedia.org/wiki/Loop_device -
https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/ -
https://en.wikipedia.org/wiki/Erasure_code -
https://kubernetes.io/docs/concepts/storage/storage-classes/#glusterfs -
https://kubernetes.io/docs/concepts/storage/persistent-volumes/ -
https://github.com/milvus-io/milvus/issues/3093 -
https://kubernetes.io/docs/concepts/workloads/pods/ -
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/ -
https://github.com/kubernetes/kubernetes/blob/18099e1ef7283d9ab09c45c5a4a90e26fdce1161/pkg/kubelet/dockershim/exec.go#L63 -
https://docs.docker.com/engine/reference/commandline/exec/ -
https://github.com/docker/for-linux/issues/466 -
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
作者简介

往期精彩
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏