来自清华大学、中科大和微软亚研的研究者找到 MIM 优异性能的关键所在了。
在过去的几年里,「信号掩码建模(Masked Signal Modeling)」成为了一个普遍而有效的自监督预训练任务,即去掉一部分输入信号并试图预测这些被去掉的信号,这个任务被广泛用于自然语言、视觉和语音等各种领域。近期,图像掩码建模(MIM)也被证明是计算机视觉中广泛使用的有监督预训练方法的有力竞争者,基于 MIM 的预训练模型在不同类型和复杂程度的广泛视觉任务上实现了非常高的微调精度。
然而,图像掩码建模有效性的来源缺乏进一步的解释。来自清华大学、中科大和微软亚研的研究者
基于这一出发点,探究并解答了
几个关键问题:
2. 在公平的对比下,MIM 和有监督预训练模型在不同类型的任务中,如语义理解、几何和运动任务中的可迁移性如何?
![]()
论文地
址:
https://arxiv.org/pdf/2205.13543.pdf
为了研究这些问题,论文从可视化和实验的角度分别对 MIM 和有监督模型进行了比较。
1)从可视化中探索促成 MIM 优异性能的关键机制是什么,发现 MIM 预训练会给模型带来局部性的归纳偏置、注意力头上更大的多样性等,或许是该类方法帮助下游任务优化的关键;
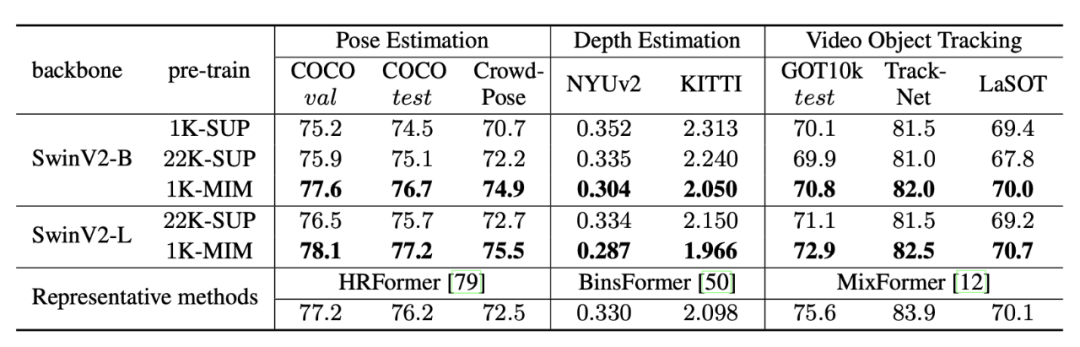
2)从实验中,研究 MIM 和有监督模型在不同类型的任务中的表现,发现 MIM 模型在具有弱语义的几何和运动任务中表现出色。一个标准的 SimMIM 预训练的 SwinV2-L 可以在姿势估计(COCO test-dev 78.9 AP,CrowdPose 78.0 AP)、深度估计(NYUv2 0.287 RMSE,KITTI 1.966 RMSE)和视频物体跟踪(LaSOT 70.7 SUC)上取得SOTA性能。
研究者希望对 MIM 更为深入的理解能够激发这个方向新的、可靠的研究。
![]()
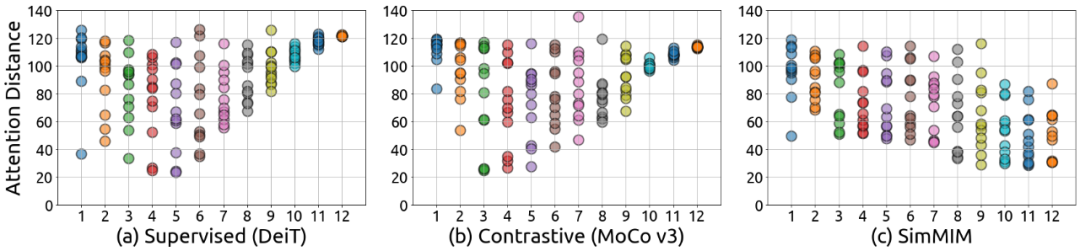
局部性 v.s. 全局性
:首先,上图展示了有监督模型和 MIM 模型在不同层的平均注意力距离,发现 MIM 给训练后的模型带来了局部性的归纳偏置,即在所有层均在某些注意力头中倾向于关注附近的像素。但有监督的模型倾向于在较低层中关注局部像素,而在较深层中关注全局像素。对比学习模型和有监督模型的表现极其相似。
![]()
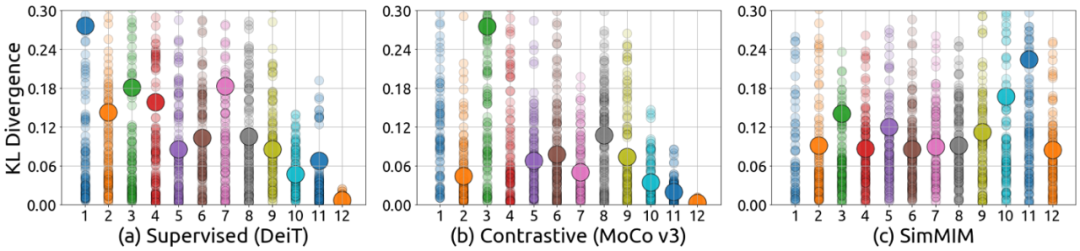
注意力头的多样性
:上图展示了不同模型在每一层中的不同注意力头(Attention Head)关注的像素是否相同。在 MIM 模型中,对所有层,不同的注意力头均倾向于关注不同的像素,即 KL 散度较大。但是对于有监督模型来说,注意力头的多样性随着层数变深而减少,最后三层的多样性已经非常小了。对比学习模型和有监督模型的表现依然极其相似。
![]()
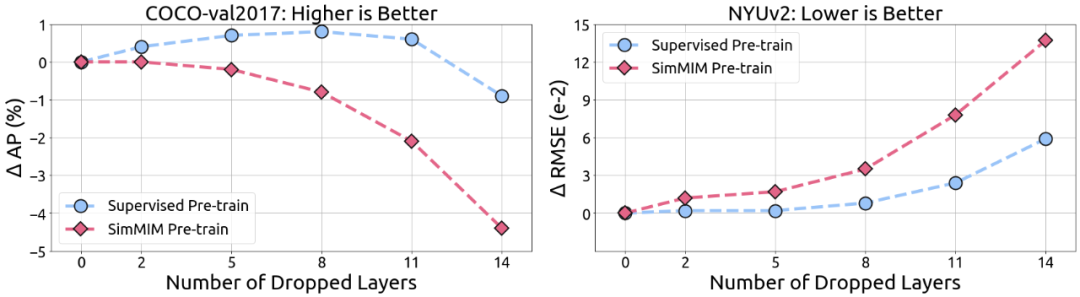
直观理解,注意力头多样性的损失一般会影响模型的表达能力。为了验证这一点,文中尝试了在微调过程中丢掉有监督模型的最后几层,并发现在丢掉合适层数的情况下,下游任务的微调性能不下降(右图)或甚至会上升(左图),然而在 MIM 模型中并没有观察到这一现象。这也进一步验证了注意力头多样性的损失会一定程度上损害下游任务的性能。
![]()
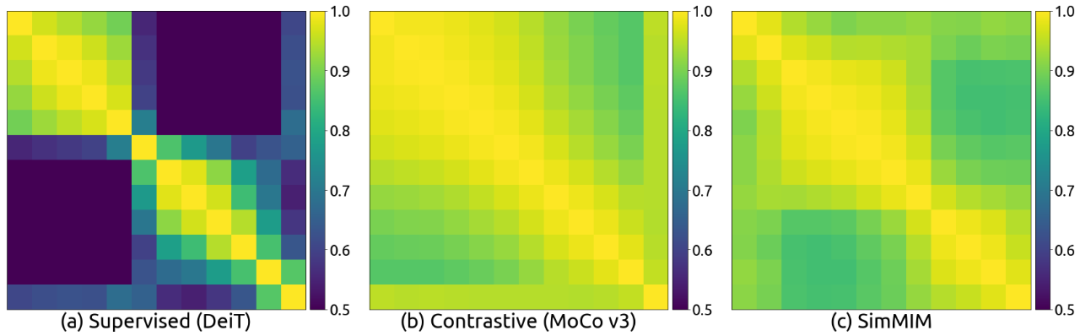
不同层特征之间的表示差异
:上图使用 Centered Kernel Analysis (CKA) 展示了模型在不同层之间学到特征的相似程度。在 MIM 模型中,不同层的特征表示具有非常高的相似性,它们的 CKA 值都非常大([0.9, 1.0])。但对于有监督模型,不同的层学到的特征差异较大。
此外,论文还在附录中提供了关于 Swin Transformer 和 RepLKNet 的更多分析,上述对 ViT 的观察依然成立。对于 RepLKNet,文中发现 MIM 预训练能够帮助基于大卷积核的卷积网络在没有重参数化技巧的情况下进行优化。
为了了解 MIM 模型对哪种类型的任务效果更好,文中进行了大规模的实验研究,比较了在三种类型的任务中 MIM 和有监督模型的微调性能,包括语义理解任务、几何和运动任务,以及同时执行这两种任务的组合任务。
![]()
对于语义理解任务,文中选择了几个代表性和多样性兼具的图像级分类任务。对于那些类别被 ImageNet 的一千类别充分覆盖的分类数据集(如 CIFAR-10/100),有监督模型可以取得比 MIM 模型更好的性能。然而,对于细粒度的分类数据集(如 Food、Birdsnap、iNat18 等)、或具有不同输出类别的数据集(如 CoG),有监督模型中的表示能力难以迁移,由此 MIM 模型的微调表现普遍优于有监督模型。
![]()
几何和运动任务对于语义的需要较弱,而更需要高分辨率的物体定位能力。在这一类任务中 MIM 模型可以大幅度领先于有监督模型。无需特殊设计,一个标准的 MIM 预训练的 SwinV2-L 可以在姿势估计、深度估计和视频物体跟踪这三个具有代表性的几何和运动任务中取得当前最先进的性能。
![]()
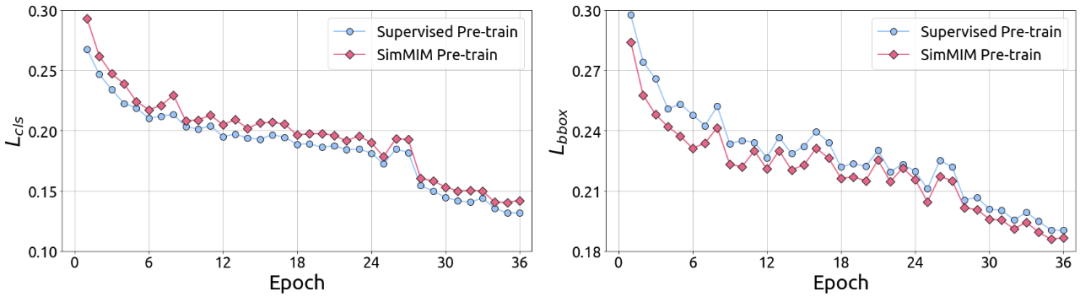
物体检测与语义分割任务较为特殊,需要同时进行语义理解(分类)和几何学习(定位)。对于 COCO 上的物体检测和分割任务,在 box/mask AP 指标中 MIM 模型优于有监督模型。为了进一步理解此过程,上图中展示了在训练过程中物体分类和定位的损失函数的变化情况,可以发现 MIM 模型可帮助定位任务更快地收敛,而有监督模型则由于 COCO 的类别被 ImageNet 完全覆盖而对物体分类任务帮助更大。
总体而言,MIM 模型在语义较弱的几何 / 运动任务或细粒度分类任务中的表现明显优于有监督模型。对于有监督模型擅长的任务(语义覆盖较好的语义理解任务),MIM 模型仍然可以取得极具竞争力的迁移性能。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com