干货 | 携程新风控数据平台建设

作者:刘丹青
前言
近几年,随着电商和互联网金融的发展,各大互联网企业也在逐步加强风控体系的建设,为公司的运营保驾护航。在携程,各BU经常受到恶意注册、登录、恶意刷单、扫号等行为,所以建设了一套数据平台,希望能够从数据中挖掘出有用的信息,不仅可以为风控系统提供数据支持,还可以为其他服务提供支撑。
本文主要从架构和业务的角度介绍下携程信息安全团队的数据平台建设之路,以及如何为业务和风控提供支持的。
一、数据平台1.0的特点
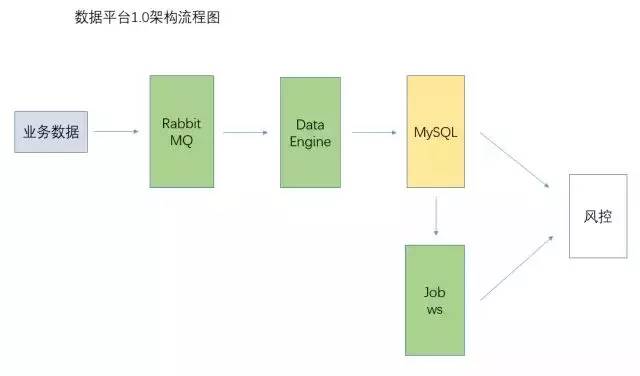
1.0数据平台架构图
为了快速支持风控平台,在早期建设数据平台的时候,我们直接通过RabbitMQ收集业务数据,再使用数据引擎对数据做清洗、计算,再存储在MySQL中,把数据处理以sql的形式写入到代码中,通过高频的定时任务对数据做聚合统计。
在刚开始运行时,数据量和业务量都比较小,恶意攻击的手段也比较简单,所以数据统计还是比较快速及时的,满足我们大多数的需求。
随着业务量的爆炸式增长,数据处理的复杂度提升,我们不得不面对几个问题:
数据来源单一,并强依赖RabbitMQ;数据量过大时,data engine无法快速的处理完数据,导致MQ中堆积的数据越来越多,最终导致服务器内存崩溃
做数据处理的sql语句都是写在代码里,通过quartz去调度定时任务,这样每当需要更新数据处理逻辑时,不得不重新发布代码
二、数据平台2.0的改进
基于这两个痛点,无法提供稳定的数据服务,甚至影响了账户风控平台的业务,所以为了解决这些问题,提供稳定可靠的服务,我们重新设计了数据平台2.0,解决以上痛点,并从下面三个方面考虑,解决以上痛点:
数据采集与整合
数据的实时计算与离线计算
任务调度与热更新
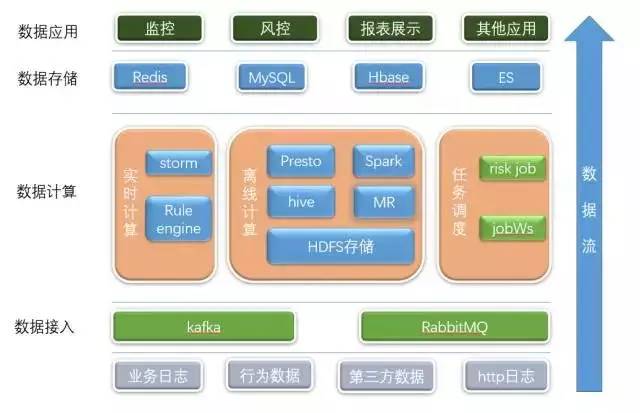
数据平台架构图
那么接下来就谈谈我们具体是怎么去解决这些问题的。
1、数据来源
原来我们只能被动的接收风控平台传过来的数据,数据样本过于单一;在新版本中,需要收集更多的数据,比如业务日志、行为日志、http日志等;这些数据源位于各BU的存储上,通过Kafka或者MQ流式的将这些数据拉取过来后,又由于数据格式各异,通过数据平台创建数据模型,并保存到HDFS存储上。
在风控的场景中,我们需要判断每一个请求是否是恶意攻击,与此同时,又不能影响普通用户的正常体验,那么我们需要对所以的请求数据进行计算,并实时的给出响应,这个时间一般都是秒级范围。
2、流式计算与实时计算
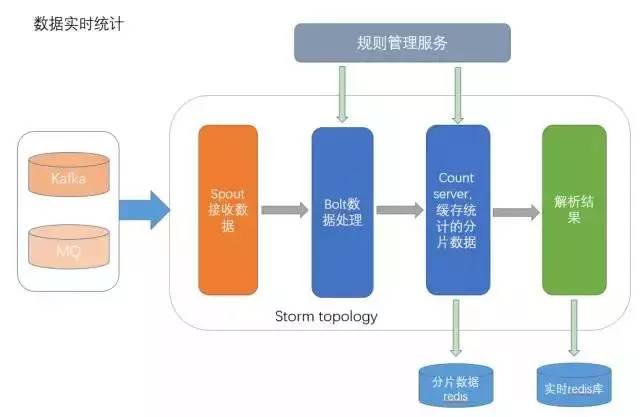
实时统计流程图
所以在这块我们做了两块计算,首先是用流式计算对数据做实时统计,通过Storm去消费Kafka/MQ的数据,并分发各种数据统计规则到bolt里,对数据做个初步计算,再使用count server对数据进行分片,同时进行数据流的继续处理。
通过count server得到的分片数据和最终的数据都会缓存起来,可以为接下来的实时计算提供部分的数据支持。在这里,由于数据是通过Kafka或者MQ传过来,有时候可能出现数据堆积的情况,导致无法进行实时统计,所以在这还做了一个请求-统计的超时监控,这可以帮助我们及时处理数据流问题。
接下来是实时计算,由于实时计算的性能要求很高,所以当用户的请求过来时,在流式计算结果的基础上做增量运算,最终达到一个实时的效果;这个结果也会存到redis中并定期做持久化,可以作为下一次请求的参数,也方便后续的离线计算。
这里大概介绍下count server,这个服务可以满足我们对于数据预热、分片存储的需求。
先举个例子:我们需要计算一个IP在10分钟内的访问次数,原来的做法就是通过索引日志或者直接去DB中查询10分钟内的数据,但是这样的效率还是比较低下的;我们通过count server把每个请求分别存储在一个时间槽里,当我们需要按照时间去统计的时候,直接获取所有槽里的数据,并直接相加就能得到结果。所以这就可以看出来,count server其实就是按照各种维度,对数据进行分片存储。
3、离线计算
在离线计算这块,我们使用了十分流行的解决方案,Hadoop+Spark。随着数据的增长,MapReduce和Spark任务的数量也逐渐的增加,并将计算结果按照不同的应用类型分别保存到MySQL、Redis、Hbase、ES上。
4、任务调度与热更新
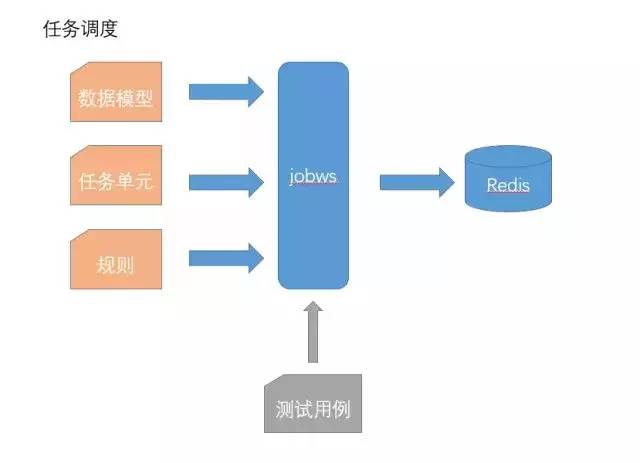
为了方便任务的调度与热更新,我们把任务拆解成任务单元和动态规则;在数据平台中,分别创建任务单元和规则,通过zookeeper将规则打包成规则集推送到不同的任务单元上,实现自动调度与热更新;这样即使规则出现问题,也不需要重新部署整个任务,只需要修改规则并重新推送规则集即可。
同时为了更好的检查任务的正确性,还新增了测试单元,在测试单元中创建测试用例、设置入参与预期结果,然后注入到任务单元中即可完成测试,这样可以极大的提高任务的上线与更新效率。
5、效果
伴随着新平台的上线,每天处理的数据达到近30亿,相较于原来的1.0版本,实现了近30倍的提升;而且拦截了大量的恶意攻击请求;并且整个平台的服务化之后,很大程度上减少了开发人员的参与。
三、尾声
在建设数据平台的过程中,首先是考虑对业务的支持,脱离了业务空谈数据是没有意义的,在对老业务提供支持的同时,积累经验,收集需求,为新业务提供快速的支撑;其次是平台的扩展,随着业务的发展,数据量和数据分析也会要求的越来越多,数据平台不仅要可以快速的横向扩展,还能在原有的数据链路上方便快捷的插入新的操作与功能。
毕竟数据平台的建设与运营并非一朝一夕的工作,也不是一个通过堆砌各种框架组件而成的应用,而是根据自身的需求,合理的制定计划、设计架构,最终达到一个成本和收益的平衡。
End.
相关内容

目前业务主要为:机票(国内/国际)、酒店(国内/海外/惠选/团购)、度假(旅游/票务/租车/邮轮)、商旅(企业商旅)、铁友网(动车/高铁)、订餐小秘书(订餐/婚宴)、社区(驴评网)、松果网、古镇网、途家网、鸿鹄顶级旅游、携程自由行杂志



