不用批归一化也能训练万层ResNet,新型初始化方法Fixup了解一下
选自arXiv
作者:Hongyi Zhang等
机器之心编译
参与:路、思源
批归一化(BN)基本是训练深度网络的必备品,但这篇研究论文提出了一种不使用归一化也能训练超深残差网络的新型初始化方法 Fixup。
前几天,我们介绍了「机器学习领域的七大谣传」,其中一个谣传就是「训练超深度残差网络怎么少得了批归一化(BN)!」。文中介绍了论文《Fixup Initialization: Residual Learning Without Normalization》表明在不引入任何归一化方法的情况下,通过使用原版 SGD,可以有效地训练一个 10,000 层的深度网络。也就是说「训练超深残差网络可以不用批归一化」。
近日,Tesla AI 总监 Andrej Karpathy 也发推提及了这篇论文,这篇论文到底如何,我们一起来看一下吧。

归一化层是当前最优神经网络架构的重要组成部分。人们普遍认为归一化层可以稳定训练、实现较高的学习率、加速收敛并提高泛化能力,尽管其有效的原因仍然是一个活跃的研究课题。这篇论文就挑战了这一「共识」,认为这些好处并不独属于归一化。
研究者提出了一种新型初始化方法 fixed-update initialization (Fixup),试图在训练开始时通过恰当地调整初始化来解决梯度爆炸和梯度消失问题。实验证明,使用 Fixup 训练残差网络与使用归一化训练残差网络一样稳定,甚至在训练 10000 层的深度网络时也是如此。此外,经过恰当的正则化后,Fixup 使残差网络在不使用归一化的情况下也能在图像分类和机器翻译任务中达到当前最优性能。
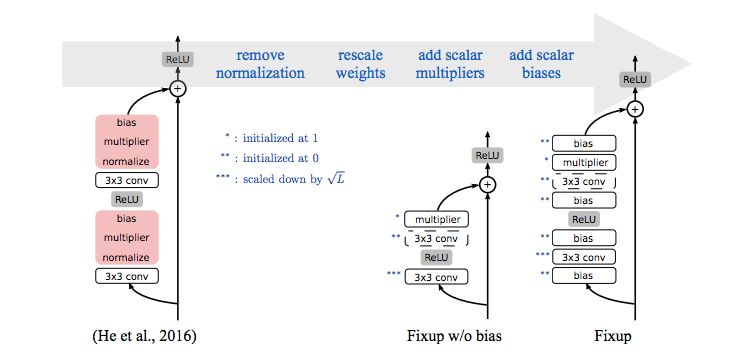
左图是 ResNet,红色为批归一化层。中间图是堆叠在一起也能稳定训练的简单 Fixup 网络(移除了偏置项)。右图是添加偏置项参数后的 Fixup。
作者在论文开头就提出了两个问题:
没有归一化,深度残差网络可以得到可靠的训练吗?
如果可以的话,那么使用和不使用归一化的深度残差网络,在相同学习率和最优化方法时,收敛速率和泛化性能能否一致?
而这篇论文中给出的答案是两个「Yes」!
该研究解释了给出这个答案的原因:
归一化为什么有助于模型训练?论文作者推导出残差网络在初始化时,梯度范数的下界,从而解释了为什么在使用标准初始化时,归一化技术对于用大学习率训练深度残差网络是必需的。
关于不使用归一化的模型训练,作者提出了一种新初始化方法 Fixup。通过调整网络架构对残差分支的标准初始化进行重缩放,Fixup 可使深度残差网络在不使用归一化技术的情况下以最大学习率进行稳定训练。
作者还在图像分类和机器翻译任务上对以上第二点结论进行了验证:
图像分类:作者在图像分类基准数据集 CIFAR-10 上训练 Wide-ResNet、在 ImageNet 数据集上训练 ResNet,但将批归一化技术替换成了 Fixup,结果发现经过恰当正则化的 Fixup 性能堪比使用归一化技术的精调基线模型。
机器翻译:作者在机器翻译基准 IWSLT 和 WMT 上训练 Transformer 模型,但将层归一化替换成了 Fixup,结果发现新模型优于基线模型,且同样的架构输出结果却达到了新高。
深度网络标准初始化的问题
标准初始化方法尝试设置网络的初始参数,以使激活函数不会消失也不会爆炸。但是,据观察在没有归一化技术的时候,标准初始化无法恰当处理残差连接的梯度流,从而导致梯度爆炸。
作者分析后指出了深度残差网络标准初始化的失败模式:某些层的梯度范数下界会随着网络深度增加而无限增长,即梯度爆炸。具体推导过程参见论文第 2 章。
新型初始化方法 Fixup
作者同时指出摆脱该失败模式未必就能带来成功的训练,毕竟我们所关心的是把整个网络作为函数,而不是一个层或一个网络块。因此,作者提出了一种新型初始化方法 Fixup,它使用自上而下的设计,通过调整标准初始化来确保网络函数的更新(Gradient)保持在恰当范围内。作者用 η 表示学习率,将目标设置为:

换言之,其目标是设计一种初始化,使网络函数的 SGD 更新保持在合适的尺度内,且独立于网络深度。
总结来看,该研究提出的新型初始化方法 Fixup 可使在不使用归一化技术的情况下完成残差网络训练。其原理如下:

1. 将分类层和每个残差分支的最后一层初始化为 0。
2. 使用标准方法对其他层执行初始化,然后按
缩放残差分支中的权重层。
3. 在每个分支中添加一个标量乘数((initialized at 1),在每个卷积、线性和元素级激活层前面添加一个标量偏差((initialized at 0)。
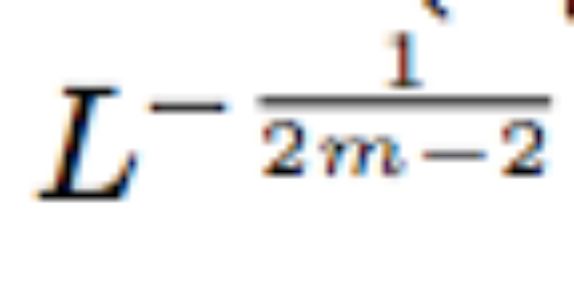
其中规则 2 是必要的。
实验结果
该研究在深度网络和图像分类、机器翻译任务上对这一新方法进行了测试。
深度网络
以默认学习率在 CIFAR-10 数据集上进行第一个 epoch 训练后,Fixup 的性能与批归一化不相上下,甚至对 10000 层的深度网络也是如此。
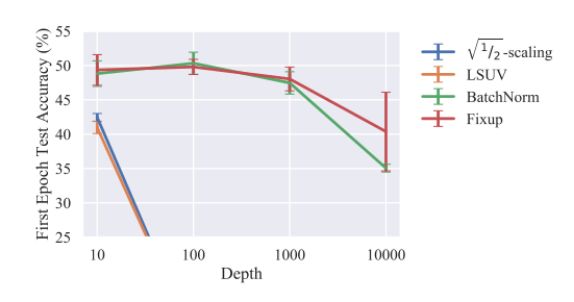
图 3:不同方法以默认学习率在 CIFAR-10 数据集上训练一个 epoch,训练后的残差网络深度和测试准确率对比。从图中可以看到 Fixup 在训练非常深的网络时可以与批归一化具备同样的学习率(越高越好)。
图像识别
研究者在图像分类应用上将批归一化替换成 Fixup,来测试 Fixup 的能力。

表 1:使用 ResNet-110 在 CIFAR-10 数据集上的结果(5 次训练的平均值,分值越低越好)。
Fixup 能够在 CIFAR-10 上以高学习速率训练一个 110 层的深度残差网络,得到的测试集表现和利用批归一化训练的同结构网络效果相当。
作者还在 ImageNet 数据集上进行了测试。
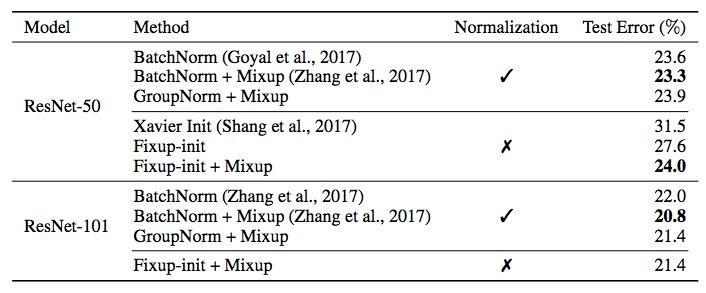
表 2:使用 ResNet 架构在 ImageNet 数据集上的测试结果(分值越低越好)。
机器翻译
为了展示 Fixup 的通用性,研究者还使用 Transformer 在机器翻译任务中进行了测试。
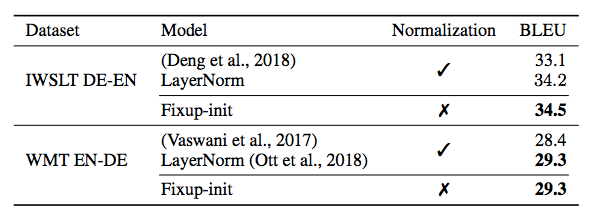
表 3:在机器翻译任务上对比 Fixup 和 LayerNorm(分值越高越好)。

论文链接:https://arxiv.org/pdf/1901.09321v1.pdf
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
