解决Spark数据倾斜(二) 使用Map侧Join代替Reduce侧Join

上一篇讲了《通过分散同一Task的不同Key缓解数据倾斜问题》。本文结合实例分析了使用Map侧Join代替Reduce侧Join的实现方法及适用场景。更多解决数据倾斜的方案请点击“阅读原文”进入作者个人站点阅读或者直接浏览www.jasongj.com/spark/skew/
原理
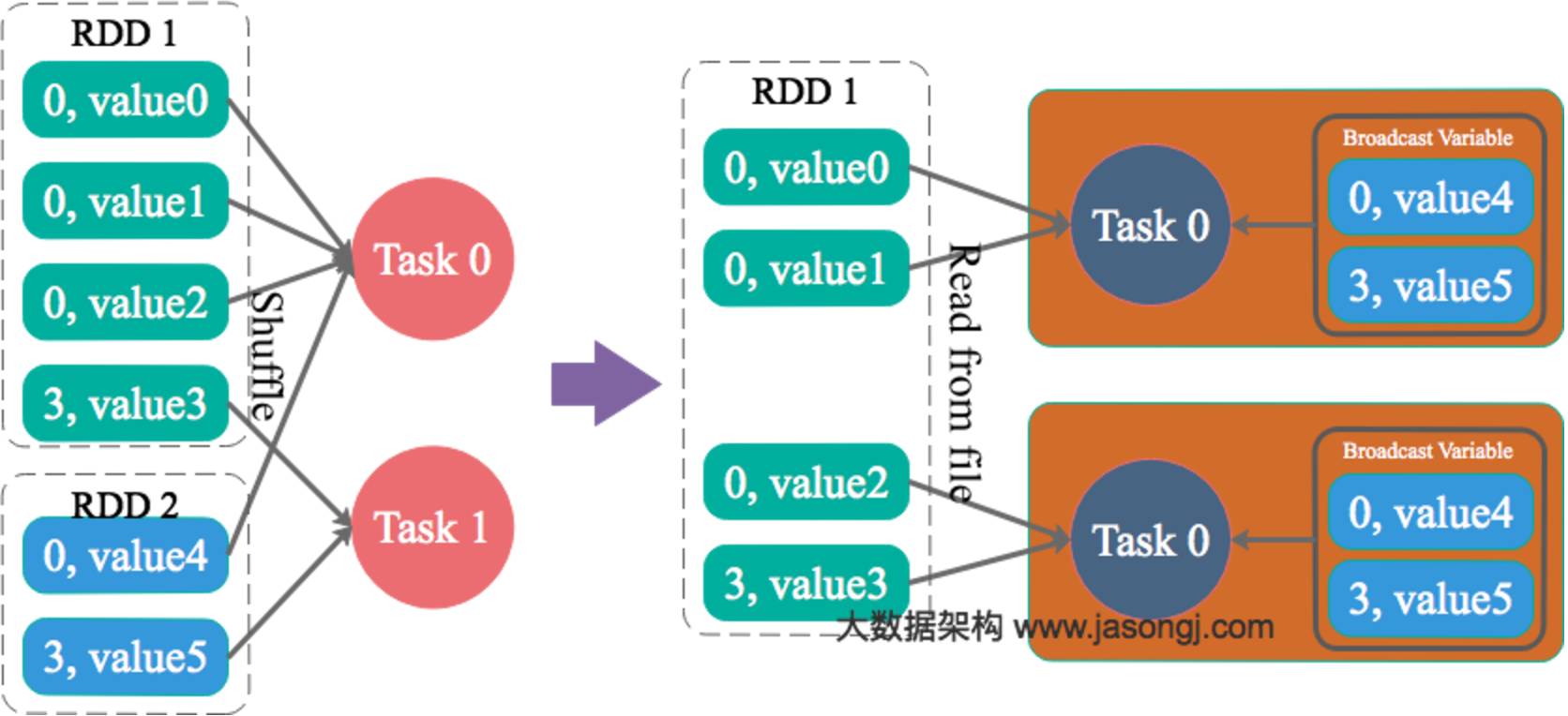
通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle从而完全消除Shuffle带来的数据倾斜。
案例
通过如下SQL创建一张具有倾斜Key且总记录数为1.5亿的大表test。
INSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 980000000 THEN (95000000 + (CAST (RAND() * 4 AS INT) + 1) * 48 )
ELSE CAST(id/10 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
使用如下SQL创建一张数据分布均匀且总记录数为50万的小表test_new。
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/10 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
直接通过Spark Thrift Server提交如下SQL将表test与表test_new进行Join并将Join结果存于表test_join中。
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
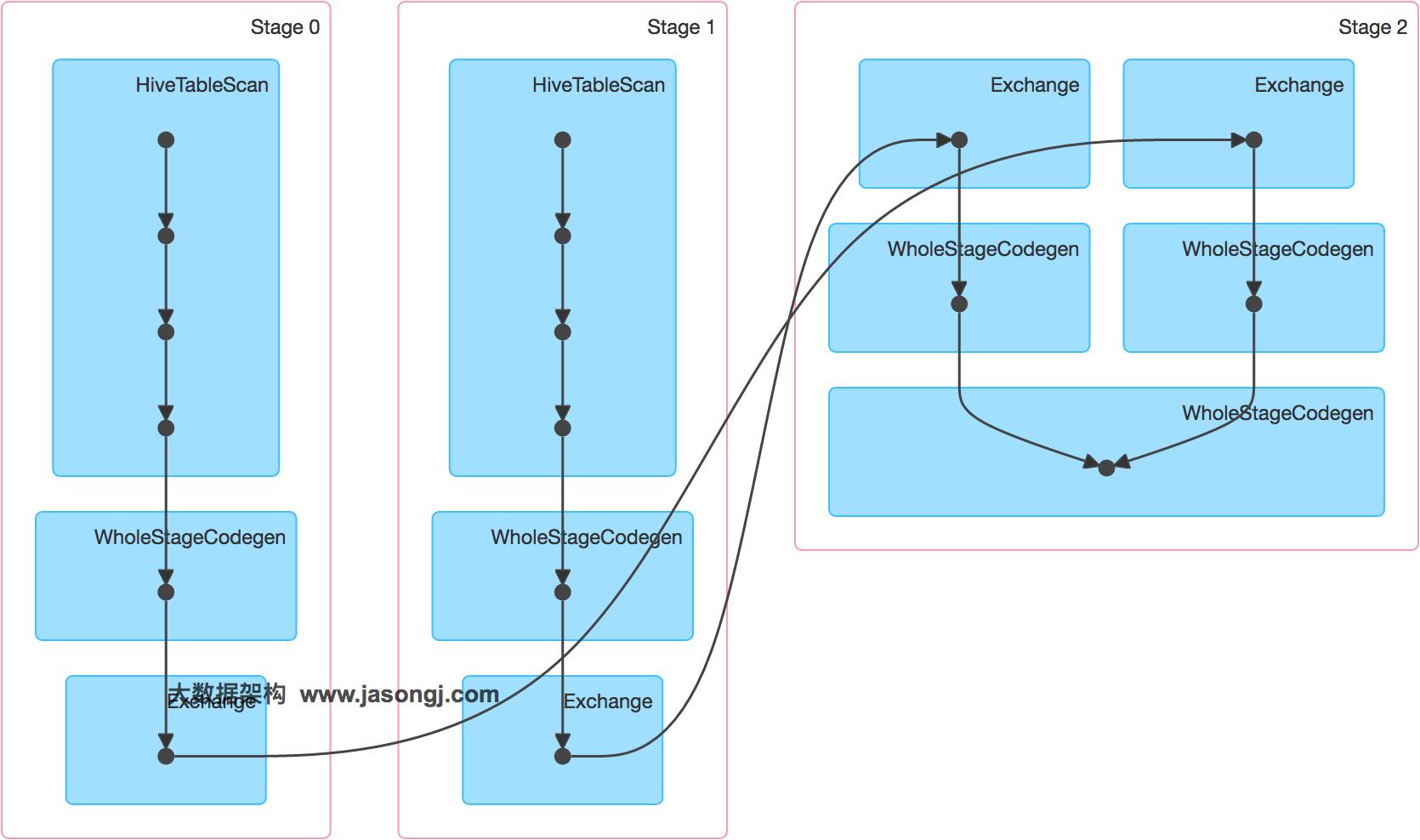
该SQL对应的DAG如下图所示。从该图可见,该执行过程总共分为三个Stage,前两个用于从Hive中读取数据,同时二者进行Shuffle,通过最后一个Stage进行Join并将结果写入表test_join中。
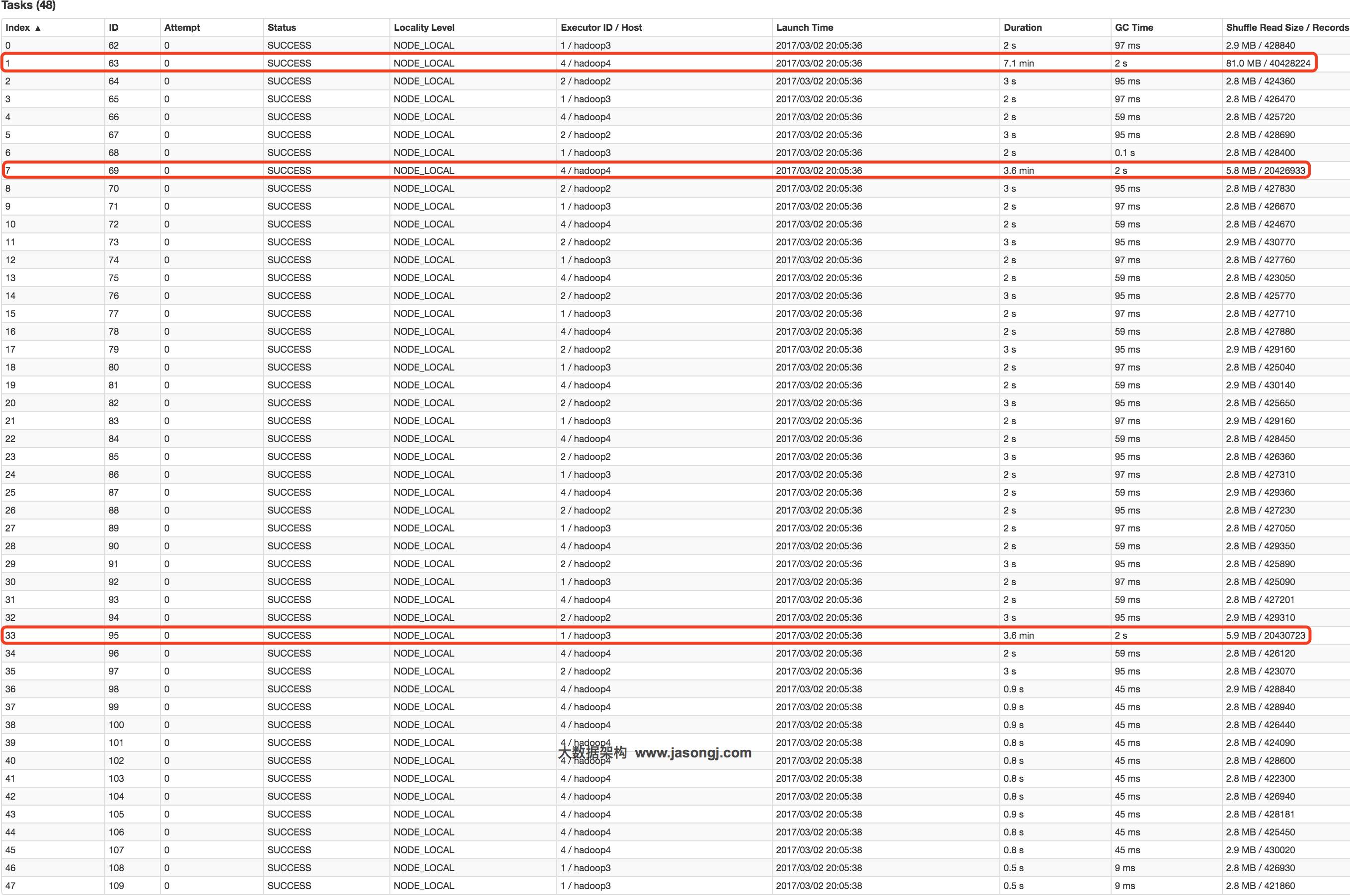
从下图可见,Join Stage各Task处理的数据倾斜严重,处理数据量最大的Task耗时7.1分钟,远高于其它无数据倾斜的Task约2秒的耗时。
接下来,尝试通过Broadcast实现Map侧Join。实现Map侧Join的方法,并非直接通过CACHE TABLE test_new将小表test_new进行cache。现通过如下SQL进行Join。
CACHE TABLE test_new;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
通过如下DAG图可见,该操作仍分为三个Stage,且仍然有Shuffle存在,唯一不同的是,小表的读取不再直接扫描Hive表,而是扫描内存中缓存的表。
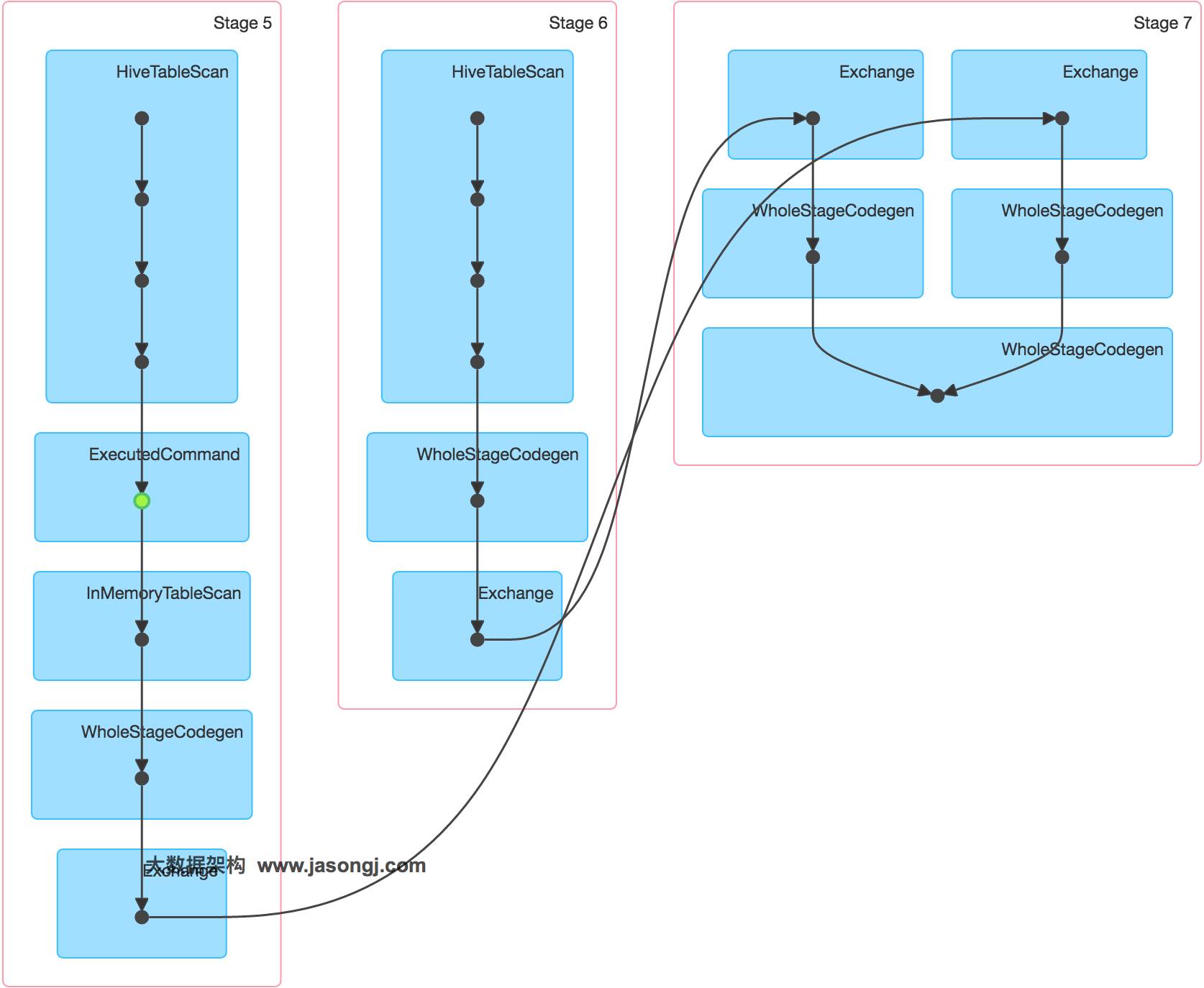
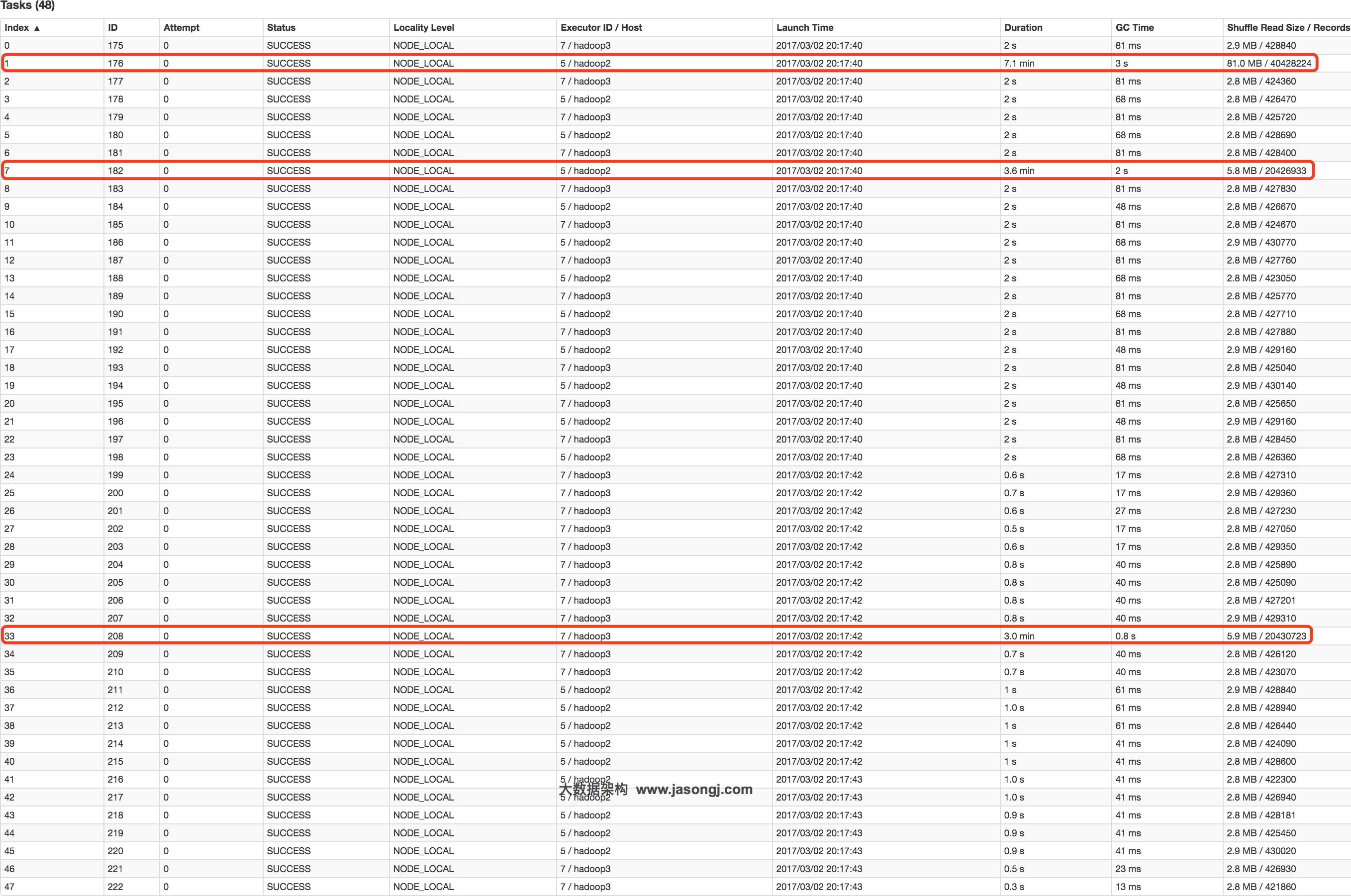
并且数据倾斜仍然存在。如下图所示,最慢的Task耗时为7.1分钟,远高于其它Task的约2秒。
正确的使用Broadcast实现Map侧Join的方式是,通过SET spark.sql.autoBroadcastJoinThreshold=104857600;将Broadcast的阈值设置得足够大。
再次通过如下SQL进行Join。
SET spark.sql.autoBroadcastJoinThreshold=104857600;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
通过如下DAG图可见,该方案只包含一个Stage。
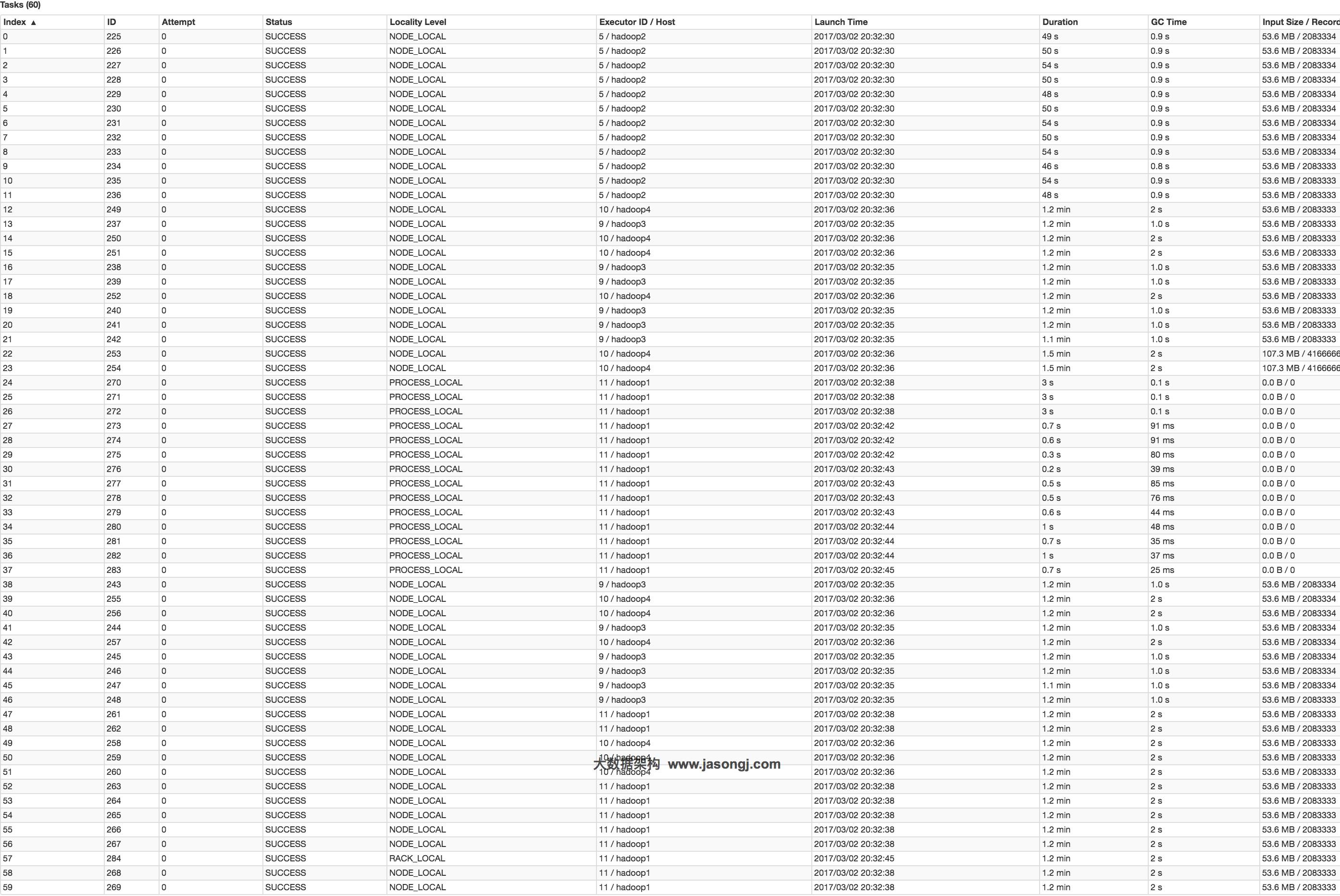
并且从下图可见,各Task耗时相当,无明显数据倾斜现象。并且总耗时为1.5分钟,远低于Reduce侧Join的7.3分钟。
总结
适用场景
参与Join的一边数据集足够小,可被加载进Driver并通过Broadcast方法广播到各个Executor中。
解决方案
在Java/Scala代码中将小数据集数据拉取到Driver,然后通过Broadcast方案将小数据集的数据广播到各Executor。或者在使用SQL前,将Broadcast的阈值调整得足够多,从而使用Broadcast生效。进而将Reduce侧Join替换为Map侧Join。
优势
避免了Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
劣势
要求参与Join的一侧数据集足够小,并且主要适用于Join的场景,不适合聚合的场景,适用条件有限。
解决Spark数据倾斜系列
长按下方二维码可快速关注

原创文章,始发自作者个人博客www.jasongj.com。作者[郭俊(Jason Guo)],一位讲方法论的实践者。转载请在文章开头处注明转自【大数据架构】并以超链接形式注明原文链接http://www.jasongj.com/spark/skew/
点击“阅读全文”,阅读作者个人博客