Python高级技巧:用一行代码减少一半内存占用

本文为 AI 研习社编译的技术博客,原标题 :
Python: How To Reduce Memory Consumption By Half By Adding Just One Line Of Code?
作者 | Alex Maison
翻译 | 邓普斯•杰弗
校对 | 酱番梨 整理 | 菠萝妹
原文链接:https://medium.com/@alexmaisiura/python-how-to-reduce-memory-consumption-by-half-by-adding-just-one-line-of-code-56be6443d524
注:本文的相关链接请点击文末【阅读原文】进行访问

我想与大家分享一些我和我的团队在一个项目中经历的一些问题。在这个项目中,我们必须要存储和处理一个相当大的动态列表。测试人员在测试过程中,抱怨内存不足。下面介绍一个简单的方法,通过添加一行代码来解决这个问题。
图片的结果
下面我来解释一下,它是如何运行的。
首先,我们考虑一个简单的"learning"例子,创建一个Dataltem 类,该类是一个人的个人信息,例如姓名,年龄,地址等。
class DataItem(object):
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
初学者的问题:如何知道一个以上这样的对象占用多少内存?
首先,让我们试着解决一下:
d1 = DataItem("Alex", 42, "-")
print ("sys.getsizeof(d1):", sys.getsizeof(d1))
我们得到的答案是56bytes,这似乎占用了很少的内存,相当满意喽。那么,我们在尝试另一个包含更多数据的对象例子:
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("sys.getsizeof(d2):", sys.getsizeof(d2))
答案仍然是56bytes,此刻,似乎我们意识到哪里有些不对?并不是所有的事情都第一眼所见那样。
直觉不会让我们失望,一切都不是那么简单。Python是一种具有动态类型的非常灵活的语言,对于它的工作,它存储了大量的附加数据。它们本身占据了很多。
例如,sys.getsizeof("")返回33bytes,是的一个多达33个字节的空行!并且sys.getsizeof(1)返回24bytes,一个整个数字占用24个bytes(我想咨询C语言程序员,远离屏幕,不想在进一步阅读,以免对美观失去信心)。对于更复杂的元素,如字典,sys.getsizeof(.())返回272字节,这是针对空字典的,我不会再继续了,我希望原理是明确的,并且RAM的制造商需要出售他们的芯片。
但是,我们回到我们的DataItem类和最初的初学者的疑惑。
这个类,占多少内存?
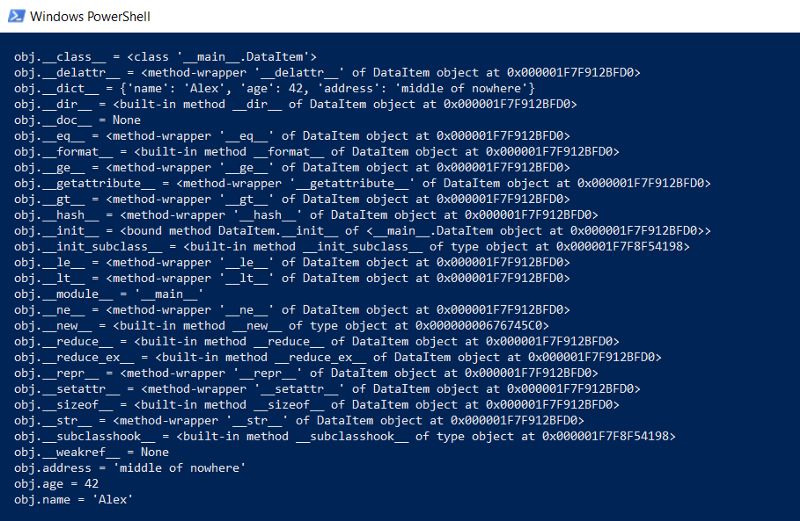
首先,我们一小写的形式将这个类的完整内容输出:
def dump(obj):
for attr in dir(obj):
print(" obj.%s = %r" % (attr, getattr(obj, attr)))
这个函数将显示隐藏的“幕后”使所有Python函数(类型、继承和其他内容)都能够正常工作的内容。
结果令人印象深刻:
这一切内容占用多少内存?
下边有一个函数可以通过递归的方式,调用getsizeof函数,计算对象实际数据量。
def get_size(obj, seen=None):
# From
# Recursively finds size of objects
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return size
让我们试一试:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d2 = DataItem("Boris", 24, "In the middle of nowhere")
print ("get_size(d2):", get_size(d2))
我们获得的答案分别为460bytes和484bytes,这结果似乎是真实的。
使用这个函数,你可以进行一系列的实验。例如,我想知道如果DataItem结构放在列表中,数据将占用多少空间。get_size ([d1])函数返回532bytes,显然,这与上面说的460+的开销相同。但是get_size ([d1, d2])返回863bytes,小于以上的460 + 484。get_size ([d1, d2, d1])的结果更有趣——我们得到了871字节,只是稍微多一点,也就是说Python足够聪明,不会再次为同一个对象分配内存。
现在,我们来看一看问题的第二部分。
是否存在减少内存开销的可能呢?
是的,可以的。Python是一个解释器,我们可以在任何时候扩展我们的类,例如,添加一个新的字段:
d1 = DataItem("Alex", 42, "-")
print ("get_size(d1):", get_size(d1))
d1.weight = 66
print ("get_size(d1):", get_size(d1))
非常好,但是如果我们不需要这个功能呢?我们能强制解释器来指定类的列表对象使用__slots__命令:
class DataItem(object):
__slots__ = ['name', 'age', 'address']
def __init__(self, name, age, address):
self.name = name
self.age = age
self.address = address
更多信息可以在文档(RTFM)中找到,其中写到“__ dict__和__weakref__”。使用__dict__节省的空间非常大”。
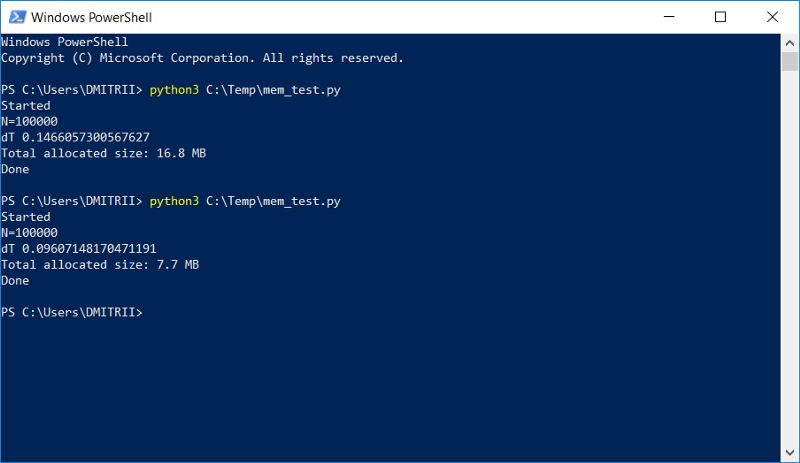
我们确认:是的,确实很重要,get_size (d1)返回…64字节,而不是460字节,即少7倍。另外,创建对象的速度要快20%(请参阅本文的第一个屏幕截图)。
唉,真正使用如此大的内存增益并不是因为其他开销。通过简单地添加元素,创建一个100,000的数组,并查看内存消耗:
data = []
for p in range(100000):
data.append(DataItem("Alex", 42, "middle of nowhere"))
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
total = sum(stat.size for stat in top_stats)
print("Total allocated size: %.1f MB" % (total / (1024*1024)))
我们不使用__slots__占用内存16.8MB,使用时占用6.9MB。这个操作当然不是最好的,但是确实代码改变的最小的。(Not 7 times of course, but it’s not bad at all, considering that the code change was minimal.)
现在的缺点。激活__slots__禁止所有元素的创建,包括__dict__,这意味着,例如,一下代码将结构转换成json将不运行:
def toJSON(self):
return json.dumps(self.__dict__)
这个问题很容易修复,它是足以产生dict编程方式,通过所有元素的循环:
def toJSON(self):
data = dict()
for var in self.__slots__:
data[var] = getattr(self, var)
return json.dumps(data)
也不可能动态给这个类添加新类变量,但是在这个例子中,这并不是必需的。
今天的最后一个测试。有趣的是整个程序需要多少内存。添加一个无限循环的程序,以便它不结束,看看Windows任务管理器中的内存消耗。
没有 __slots__:
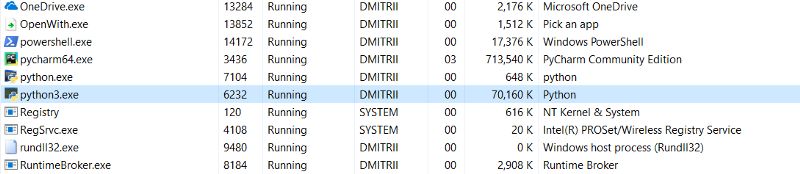
6.9Mb 变成 27Mb … 好家伙, 毕竟, 我们节省了内存, 27Mb 代替 70 ,对于增加一行代码来说并不是一个坏的例子
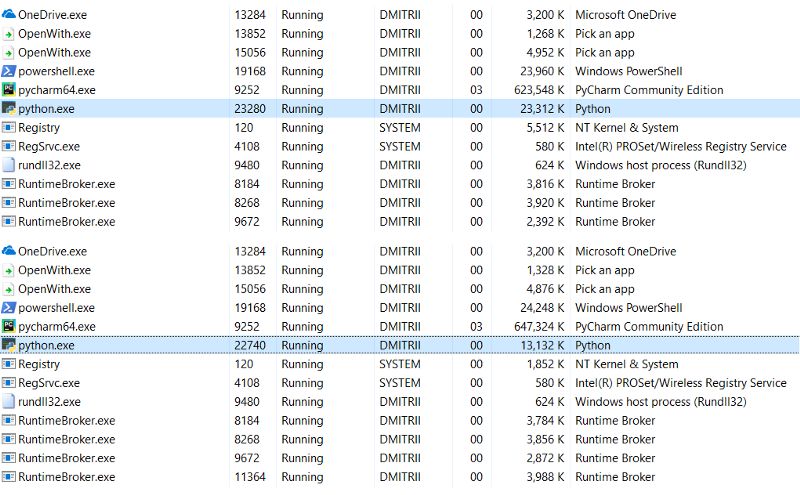
注意:TraceMelc调试库使用了许多附加内存。显然,她为每个创建的对象添加了额外的元素。如果关闭它,总的内存消耗将少得多,截屏显示两个选项:
如果你想节省更多的内存呢?
这可以使用numpy库,它允许您以C样式创建结构,但是在我的例子中,它需要对代码进行更深入的细化,并且第一种方法就足够了。
奇怪的是在Habré从来没有详细分析使用__slots__,我希望本文将填补这一空缺。
结论
这篇文章似乎是一个anti-Python广告,但并不是。Python非常可靠(为了“降低”Python程序,您必须非常努力),它是一种易于阅读和方便编写代码的语言。这些优点在很多情况下都大于缺点,但是如果您需要最大的性能和效率,您可以使用像numpy这样的库,它是用C++编写的,它可以很快和高效地与数据一起工作。
感谢大家的关注,coding快乐!
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1281
AI研习社每日更新精彩内容,观看更多精彩内容:
机器学习 2019:AI 发展趋势分析
迁移学习:如何将预训练CNN当成特征提取器
马克!程序员必须收藏的 10 类工具&库,助你提高效率变大神
如何使用 OpenCV 编写基于 Node.js 命令行界面和神经网络模型的图像分类
等你来译:
预训练模型及其应用
用Pytorch构建一个自动解码器
(Python)3D人脸处理工具face3d
使用迁移学习/数据增强方法来实现Kaggle分类&识别名人脸部
独家中文版 CMU 秋季深度学习课程免费开学!
CMU 2018 秋季《深度学习导论》为官方开源最新版本,由卡耐基梅隆大学教授 Bhiksha Raj 授权 AI 研习社翻译。学员将在本课程中学习深度神经网络的基础知识,以及它们在众多 AI 任务中的应用。课程结束后,期望学生能对深度学习有足够的了解,并且能够在众多的实际任务中应用深度学习。

↗扫码即可免费学习↖
点击 阅读原文 查看本文更多内容↙




