超分辨率在移动实时音视频的应用实践


作者 | 周世付
责编 | 刘静
出品 | CSDN(ID:CSDNnews)
在 RTC 2019实时互联网大会上,声网Agora AI 算法工程师周世付,分享了超分辨率应用于移动端实时音视频场景下,遇到的难点、通用解决方法,以及解决思路。

近年来,超分辨率(简称超分)在图像增强、去噪、细节恢复、图像放大方面展现出广阔的应用前景,成为计算机视觉领域的研究热点,受到学术界和工业界的关注和重视,业界也纷纷举办超分竞赛,比如优酷的视频超分竞赛、声网的图像超分竞赛和深圳市政府举办的AI+4K HDR竞赛,旨在吸引更多的人参与超分算法的研究和促进超分算法的落地。因为超分算法的大规模应用落地还存在一些亟需解决的问题。

目前,移动端实时音视频应用目前存在的一个痛点问题是传输的视频分辨偏低,而终端显示屏的分辨率高,存在分辨率不匹配的问题。实时传输的视频分辨率普遍偏低,是由于受到传输带宽的限制和实时性的要求。低分辨率视频不能有效的展现图像细节,因而带来的用户体验有限。为了解决传输视频与终端显示屏分辨率不匹配的问题,通常的做法是将低分辨率视频进行放大。
传统最常用的放大方法是插值法,如bicubic、nearest、bilinear等,优点是速度快,但缺点也很明显,即图像放大后,图像存在模糊、细节丢失的现象。

而随着深度学习的出现,基于深度学习的超分已经成为了新的解决方案,也是学术界与工业界都在研究的方法。它能有效地恢复图像的细节,并保持图像清晰度。但基于深度学习的超分算法在落地应用的过程中,也面临着挑战,主要表包括:(1)超分模型过大;(2)超分算法运算复杂。
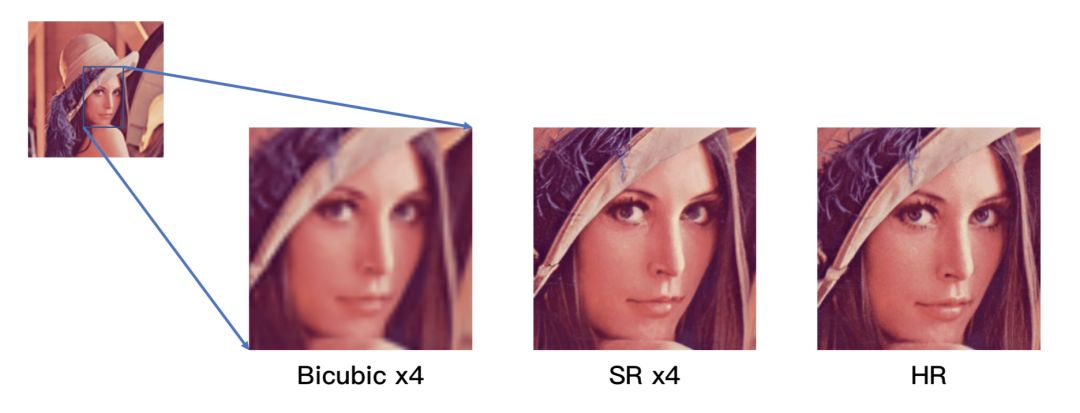
超分与Bicubic对比
目前学术界有两个经典超分模型SRGAN和ESRGAN,如下表所示,我们列出了两个模型的参数量和算法复杂度。SRGAN和ESRGAN的参数量分别达到150万和1600万,所需要的存储空间分别是6MB和63MB。对于移动设备来说,模型太大,会占用过多存储。
再看运算复杂度方面。以360x480大小的图像作为输入,进行4倍的放大,SRGAN和ESRGAN的运算复杂度分别可以达到446GFLOPs和3100GFLOPs。而目前主流的手机iphone XR的gpu的运算能力大约为500GFLOPs。由此可见,目前的移动设备的运算能力,还无法实时运行现有的超分模型,需要降低模型的算法复杂度和减小模型的体积,才能可能让实时超分模型在移动设备实时运行。
Model |
Size |
Gflops |
parameters |
Model Size |
SRGAN |
360x480 |
446 |
1554499 |
6 MB |
ESRGAN |
360x480 |
3100 |
16697987 |
63 MB |

降低模型的算法复杂度和减小模型的体积的方法,通常是模型压缩和模型加速。模型压缩的目的,是通过减小模型中冗余的权重,去掉对模型性能贡献小的分支,从而达到减小模型的参数量,降低模型的运算量。而模型加速,则是侧重降低卷积运算的开销,提高卷积运算的效率,从而提高模型的运行速度。模型压缩和模型加速,是相辅相成的,通过合理的模型压缩算法和模型加速算法的结合,能够有效地减小模型体积和提高模型的运算速度。
模型压缩方法,可以分为权重优化和模型结构设计。权重优化也可分为剪枝和量化。
剪枝,是将模型中冗余的权重去掉,以达到模型瘦身的目的。比如,Deep compression[1],通过权值剪枝、权值量化和权值编码,能够将模型的体积减小49倍。
权重量化,则将权值以低码率进行存储,从而减小模型的体积,比如,XNornet[2]模型,对输入的featuremaps和权值均进行二进制量化,实现58x的模型压缩和32倍的加速。
经典的轻量级模型有suqeezenet[3]、mobilenet[4]和shufflenet[5]。他们从模型结构设计角度来讲,通常会采用小卷积核替代大卷积核,如用3x3替代5x5、7x7, 或者1x1替代3x3。在同等条件下,3x3的运算是5x5、7x7的9/25、9/49,而且1x1是3x3的1/9。
模型加速方法,在convolution的基础上,衍生出了depth-wise convolution、group convolution,point-wise convolution。在mobilenett模型中,大量使用了depth-wise convolution和point-wise convolution。而在shufflenet模型中,则采用了group convolution和point-wise convolution。
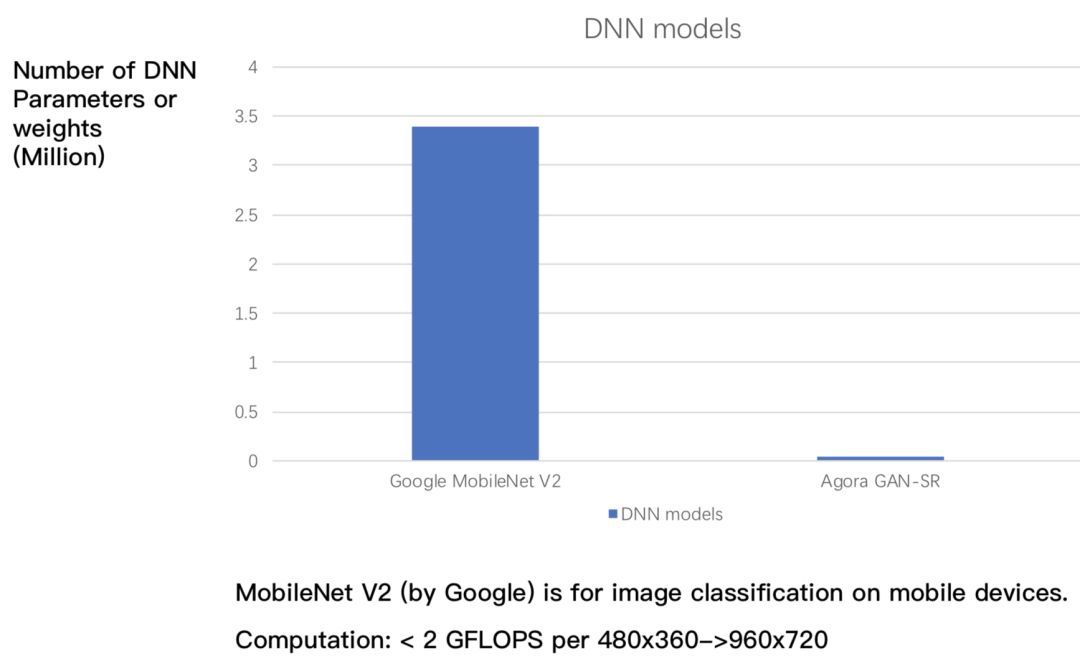
在以上的研究基础之上,声网也自研了超分算法。声网的超分模型的体积,比mobilenet v2还要小。对360p的图像进行2倍的放大时,其运算复杂度小于2GFLOPs,可实现在移动设备上的实时运行。在运算速度和超分效果实现较好的前提下,有效地提高移动实时音视频的用户体验。
1. Han S, Mao H, Dally W J, et al.Deep Compression: Compressing Deep Neural Networks with Pruning, TrainedQuantization and Huffman Coding[J]. arXiv: Computer Vision and PatternRecognition, 2015.
2. Rastegari M, Ordonez V, RedmonJ, et al. XNOR-Net: ImageNet Classification Using Binary Convolutional NeuralNetworks[C]. european conference on computer vision, 2016: 525-542.
3. Iandola F, Han S, Moskewicz MW, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and<0.5MB model size[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
4. Howard A G, Zhu M, Chen B, etal. MobileNets: Efficient Convolutional Neural Networks for Mobile VisionApplications[J]. arXiv: Computer Vision and Pattern Recognition, 2017.
5. Zhang X, Zhou X, Lin M, et al.ShuffleNet: An Extremely Efficient Convolutional Neural Network for MobileDevices[J]. arXiv: Computer Vision and Pattern Recognition, 2017.

热 文 推 荐
☞天猫回应“双11数据造假”:已启动司法流程;小米折叠手机专利曝光;ASP.NET感染勒索软件|极客头条
☞重大利好!人民日报海外版整版报道:区块链“链”向未来,既要积极又要稳妥
点击「阅读原文」,查看RTC 2019大会演讲 PPT 及视频回放


