![]()
![]()
视觉定位是一个估计6自由度(DoF)相机姿态的问题,从中获取一个给定的图像相对于一个参考场景表示。视觉定位是增强、混合和虚拟现实等应用以及机器人技术(如自动驾驶汽车)的关键技术。
为了评估较长时间内的视觉定位,官方提供了基准数据集,旨在评估由季节(夏季、冬季、春季等)和照明(黎明、白天、日落、夜晚)条件变化引起的较大外观变化的6自由度姿态估计精度。每个数据集由一组参考图像及其相应的地面真实姿态和一组查询图像组成。官方为每个数据集提供一个三角化的三维模型,并可用于基于结构的定位方法。
主页地址[1]:
https://www.visuallocalization.net
![]()
上面官方介绍中已经说明,该比赛的难点就是
如何在场景变化时进行定位
。场景变化主要在光照变化以及视角变化等。对于光照变化带来的问题可以通过上图进行阐述。上图分别展示了三角化的3D模型(上)以及同一个场景但是在不同光照条件下拍摄的图像(下四图)。假如建图时的光照左下图,定位时为后续的三种光照,由于光照条件已经发生了较大的差改变,即使使用人眼仍需要仔细辨别才能判定这是同一个地点,但如何让计算机理解这是同一个地点同时计算出此时相机的位姿呢?这就是该比赛面对的一个难点。对于视角变化的难点在此不做赘述,各位同学可以查看数据集进行查看。
https://www.visuallocalization.net/datasets
方案名称:Hierarchical Localization - SuperPoint + SuperGlue(简称,Hloc+SP+SG)[6,7]
![]()
本方案采用了分级定位(Hierarchical Localization[
2
])的方案,即先粗定位再细定位。该方案的主要特点在于特征匹配阶段使用了最近比较火的
SuperPoint
+
SuperGlue
(后续简称
「SP+SG」
),这两个网络在之前有过介绍(点击二者名字进行查看),当时只是提到了二者在大视角特征匹配时效果极佳。本方案的成功应用,可见这两个网络在该定位任务中也能发光发热。
https://github.com/cvg/Hierarchical-Localization/blob/master/pipeline_Aachen.ipynb
由于该比赛官方提供了已经用COLMAP+SIFT特征建好的模型(相机位姿以及地图点),本方案并不是使用「SP+SG」对整个场景重新进行,否则时间消耗是巨大的。本方案使用了已经建好的模型提供的「scene graph」得到与当前帧共视最好的前20张图像,然后再去提取SP特征+SG进行匹配,得到2D-2D数据关联。接下来就是三角化,本方案沿用了COLMAP的三角化方案,只是位姿换成了官方模型的位姿,数据关联就是「SP+SG」提供的2D-2D关联,三角化输出是3D地图点。
本阶段的目标是从上面建好地图中定位输入的图像对应相机的位姿。
粗定位:NetVLAD[3,4] retrieval (trained on Pitts-30k, top 50)
细定位:SP+SG+RANSAC PnP
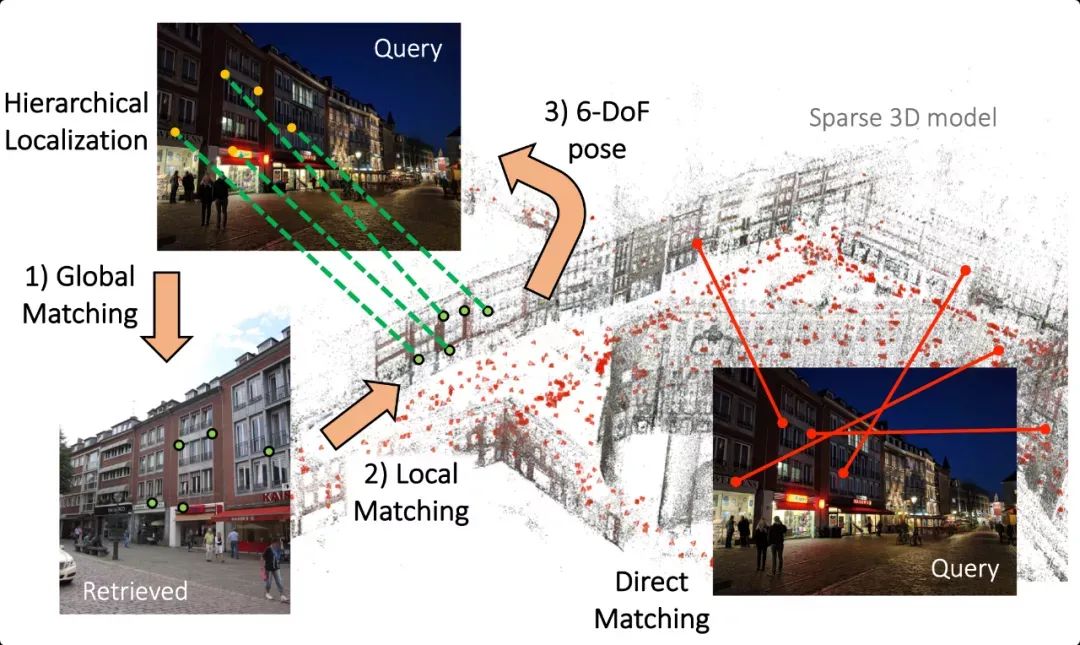
下图展示了查询图像与地图中图像的匹配效果。
![]()
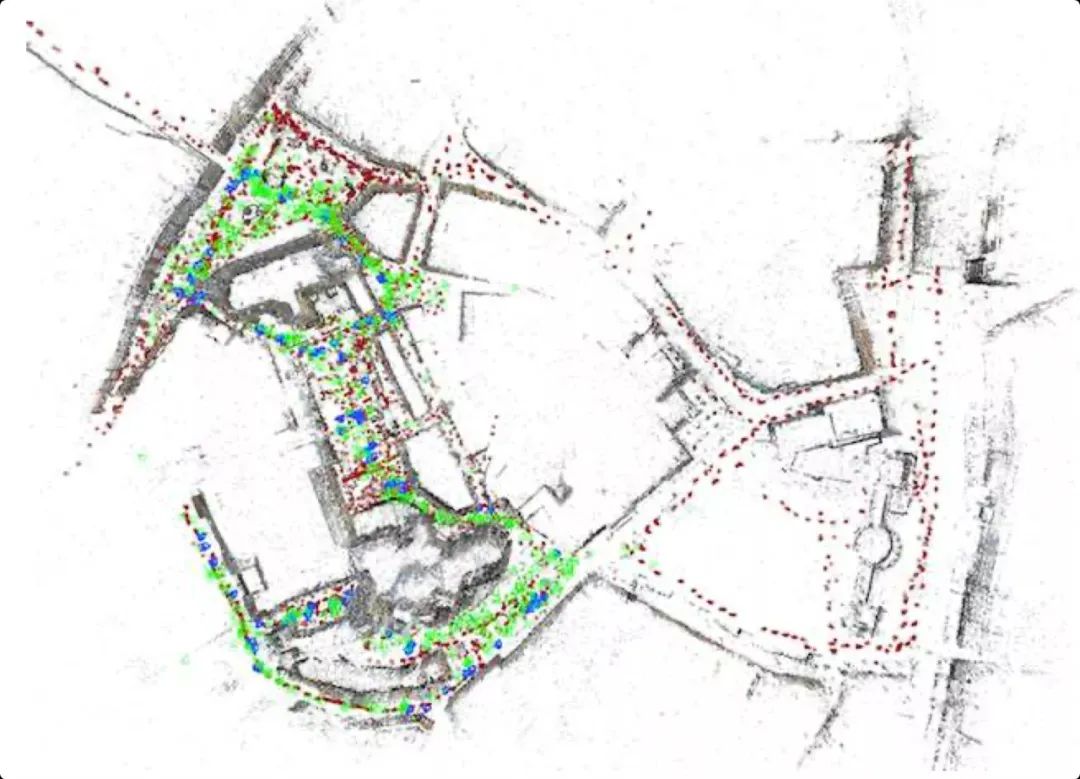
下图展示了根据Aachen Day-Night数据集建立的3D模型 (database (red), day-time query (green), night-time query images (blue))
![]()
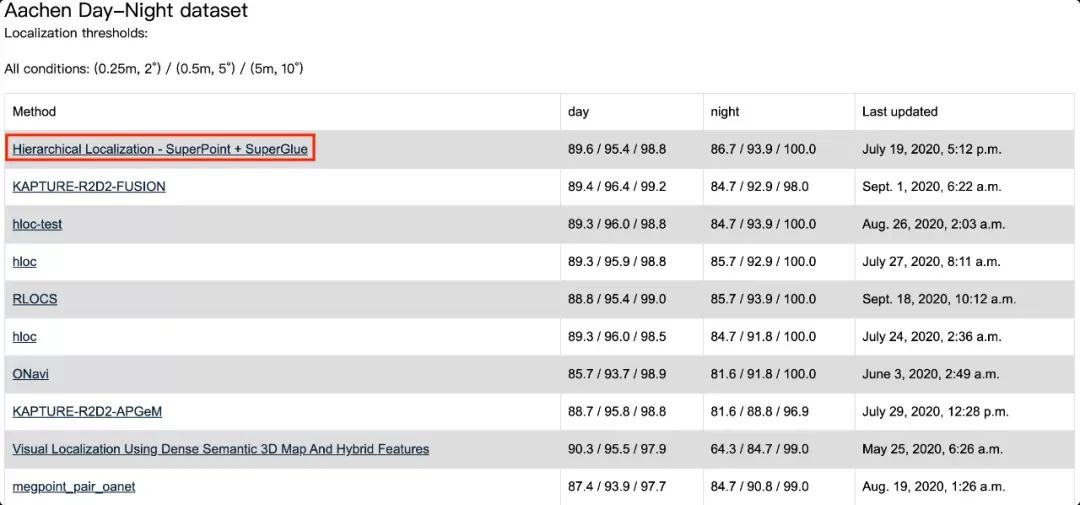
在上述数据集,不同定位阈值下的召回率排名如下图,本方案能够以较明显的优势取胜。
![]()
上文主要对视觉定位挑战赛以及CVPR 2020的冠军方案进行了介绍。基于深度学习的相似图像召回,图像特征点匹配扮演了重要的角色。
虽然目前方案能够获得出色的性能表现,但笔者认为定位性能仍然具有提升空间。例如,由于目前建图阶段并不考虑实时性,此时可以使用SP+SG对整个场景进行重建,这样可以弥补SIFT在大视角变化时无法应对的数据关联。此外,相似图像召回的方法不限于NetVLAD (CVPR 2016),可以使用性能更好的算法如[5]中提到的方案。注意到Hloc使用的是分级定位的思想,这使得分模块实现/优化变得比较轻松,例如上述改进方法;但值得思考的是这种“局部最优”拼凑起来的效果一定是“全局最优”吗?匹配做的好,位姿结算一定准确吗?后续的工作可以对此进行更多地讨论与研究(谷歌公布2020图像匹配挑战对该问题进行了较为详细的说明,建议阅读[8])。
参考
[1]. 视觉定位挑战赛主页, https://www.visuallocalization.net
[2]. From Coarse to Fine: Robust Hierarchical Localization at Large Scale, https://arxiv.org/abs/1812.03506
[3]. NetVLAD: CNN architecture for weakly supervised place recognition, http://xxx.itp.ac.cn/pdf/1511.07247v3
[4]. Hloc+SP+SG方案中NetVLAD地址, https://github.com/uzh-rpg/netvlad_tf_open
[5]. 深度学习图像召回, https://github.com/almazan/deep-image-retrieval
[6]. Hloc+SP+SG源码, https://github.com/cvg/Hierarchical-Localization
[7]. Hloc+SP+SG方案提交地址, https://www.visuallocalization.net/details/10931
[8]. 笔记:CVPR2020图像匹配挑战赛,新数据集+新评测方法,SOTA正瑟瑟发抖!https://vincentqin.tech/posts/2020-image-matching-cvpr
推荐阅读
![]()
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()