开发 | 谷歌开源强化学习深度规划网络 PlaNet

AI 科技评论按:近日,谷歌在官方博客上开源了强化学习深度规划网络 PlaNet,PlaNet 成功解决各种基于图像的控制任务,最终性能与先进的无模型智能体相比,在数据处理效率方面平均提高了 5000%。

针对人工智能体如何随着时间的推移改善自身决策机制的研究,当下用得最多的方法是强化学习。技术实现上,智能体会在选择动作(如马达命令)的过程中观察来自知觉输入的流信息(如相机图像),有时还会接收到实现指定目标的奖励。这种无模型的强化学习方法可以直接预测经过知觉观察后的行为,使 DeepMind 的 DQN 能够玩 Atari 游戏以及使用其他智能体来操控机器人。然而,这种具有「黑箱」性质的方法往往需要数周的模拟交互,经过反复的试验与试错才能完成学习,由此限制了在现实中的应用。
与此相对的是,基于模型的强化学习试图让智能体习得现实世界的日常运行规律。并非将观察结果直接转化为行动,这种方法允许智能体明确提前做出计划,通过「想象」长期回报从而更谨慎地采取行动。这种基于模型的强化学习方法实际上已取得了实质性成功,最著名如 AlphaGo,能在熟知规则的游戏虚拟板上进行移动操控。如果要将方法扩大至未知环境中进行运用(例如操控仅有像素作为输入的机器人),智能体必须懂得自己从经验中习得规则。只有实现了这种动态模型,我们原则上才有可能进行更高效与自然的多任务学习。创建出足够准确用于进行规划的模型,一直是强化学习的长期目标。
为了让该难点早日取得突破,我们联手 DeepMind 推出了深度规划网络(PlaNet)智能体,该智能体仅凭图像输入即可习得关于世界的模型,有效扩大模型的规划范围。PlaNet 成功解决各种基于图像的控制任务,最终性能与先进的无模型智能体相比,在数据处理效率方面平均提高了 5000%。我们在社区开源了相关代码:
开源网址:https://github.com/google-research/planet
PlaNet 的工作原理
简单来说,PlaNet 能在给定图像输入的情况下习得动态模型,并通过它高效吸收新的经验。与过去基于图像进行规划的方法相比,我们依靠的是隐藏或潜在状态的紧凑序列。之所以被称作潜在动态模型,是因为它不再是从一个图像到一个图像来进行直接预测,而是先预测未来的潜在状态,然后再从相应的潜在状态中生成每一个步骤的图像与奖励。通过这种方式压缩图像,智能体将能自动习得更多抽象表示,比如物体的位置和速度,无需全程生成图像也能对未来的状态进行预测。
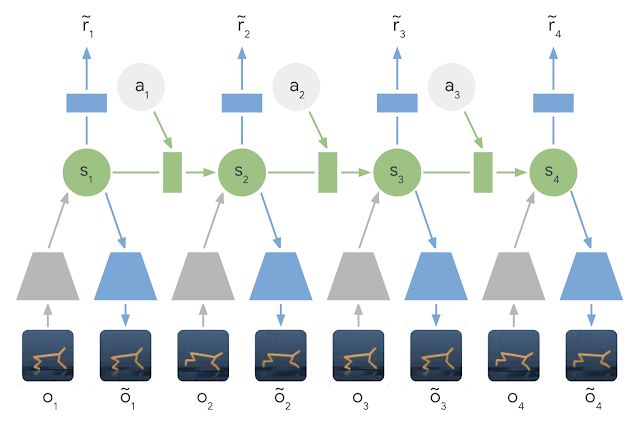
潜在动态学习模型:在潜在动态学习模型中,输入图像的信息将通过编码器网络(灰色梯形)集成到隐藏状态(绿色)中。然后隐藏状态再向前映射以预测未来的图像(蓝色梯形)与奖励(蓝色矩形)。
为了让大家准确把握潜在动态学习模型,我们向大家推介:
循环状态空间模型(A Recurrent State Space Model):兼具确定性与随机性因素的潜在动态学习模型,可以在牢记过程诸多信息的情况下,预测实现鲁棒性规划所需的各种可能未来。最终的实验表明,这两种因素对于高规划性能的实现至关重要。
潜在的超调目标(A Latent Overshooting Objective):潜在空间中的一步与多步预测之间被强行达到一致性,我们为潜在动态学习模型提炼出用于训练多步预测的目标。这便产生了一个能够快速、有效增进长期预测性能的目标,可与任意的潜在序列模型相兼容。
虽然预测未来图像允许我们对模型进行「传授」,然而图像的编码和解码(上图中的梯形)过程有赖于大量运算,这将降低我们的规划效率。无论如何,在紧凑的潜在状态空间中进行规划依然是高效的,因为我们仅需通过预测未来的奖励而非图像来评估动作序列。举个例子,即便场景无法可视化,智能体也能自行想象球的位置以及它与目标的距离将如何因为某些动作而被改变。这也意味着,每次智能体在选择动作时,可与大批量将近 10,000 个想象动作序列进行对比。最后通过执行找到最佳序列的首个动作,我们再据此重新规划下一步。
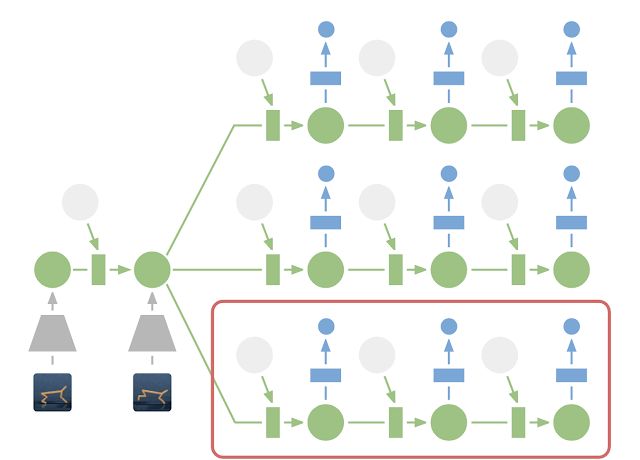
潜在空间中进行规划:为了进行规划,我们将过去的图像(灰色梯形)编码变为当前的隐藏状态(绿色)。据此我们有效预测多个动作序列的未来奖励。请注意上图里基于过去图像的图像解码器(蓝色梯形)是如何消失的。最后通过执行找到最佳序列的首个动作(红色框)。
与之前关于世界模型(world models)的工作相比,PlaNet 无需任何政策指导即可运作——它纯粹通过规划来选择行动,因此可以从实时的模型改进中受益。有关技术细节可以查看:
在线论文:https://planetrl.github.io/
PDF 文件:https://danijar.com/publications/2019-planet.pdf
PlaNet与无模型方法对比
我们利用连串控制任务上对 PlaNet 的表现进行考察。实验中这些智能体仅会获得图像观察与奖励。这些任务涵盖了各种不同类型的挑战:
cartpole 上升任务,带有固定摄像头,因此 cart 可以放心移出视线。智能体必须吸收并记住多个帧的信息。
手指旋转任务,需要对两个单独的对象以及它们之间的交互关系进行预测。
猎豹奔跑任务,难点包括难以准确预测的地面接触,需要一个可以预测多种可能未来的模型。
杯子任务,球被抓住时只会提供稀疏的奖励信号,这就意味着需要一个能够准确预测未来以规划精确行动序列的模型。
步行者任务,模拟机器人一开始会躺在地上,必须使它学会站起来并走路。

PlaNet 智能体会接受各种基于图像的控制任务的训练。这些任务涵盖了不同的挑战:部分可观察性、与地面的接触、用于接球的稀疏奖励以及控制具有挑战性的双足机器人。
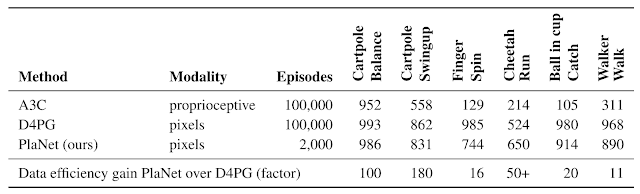
我们是第一个利用学习模型进行基于图像任务的规划,然后结果优于无模型方法的工作。下表将 PlaNet 与著名的 A3C 智能体和 D4PG 智能体进行了对比,两者的结合正好代表了无模型强化学习方法的最新进展。基线的编号均取自 DeepMind Control Suite。最终结果显示,PlaNet 在所有任务上的表现都明显优于 A3C,并接近 D4PG 的最终性能,在与环境的交互频次上平均减少了 5000%。
搞定所有任务的万能智能体(One Agent)
此外,我们还训练了用于解决所有六项任务的 PlaNet 万能智能体。该智能体在不指定任务目标的情况下被随机放置至不同环境中,需要靠自己从图像观察中来推断出任务。在不更改超参数的情况下,多任务智能体达到与万能智能体同样的平均性能水平。万能智能体虽然在 cartpole 上升任务中学习速度较缓慢,然而在需要自行进行更多探索、更具有挑战性的步行者任务上表现出更高的学习能力与性能水平。

PlaNet 智能体在多个任务上进行训练的预测视频。经过训练的智能体收集信息过程展示如上,下方是 open-loop 幻觉智能体。万能智能体将前 5 帧视为上下文语境来推断任务和状态,并在给定一系列动作的情况下准确预测往后的 50 个步骤。
结论
我们的研究结果展示了用来建立自主强化学习智能体的动态学习模型的前景。我们建议往后的研究可以将重点放在如何使其通过更高难度的任务来习得更精确的动态学习模型,比如在 3D 环境和现实世界中的机器人任务。一个可能该研究进一步取得突破的因素是 TPU 处理能力。我们对基于模型的强化学习方法在开源后的可能性感到异常兴奋,其中可能受惠的领域包括多任务学习、分层规划和通过不确定性进行估计的主动探索任务等。
via:
https://ai.googleblog.com/2019/02/introducing-planet-deep-planning.html





