李飞飞团队造出“窥视未来”新AI:去哪干啥一起猜,准确率压倒老前辈
晓查 乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
道路千万条,你走哪一条?
AI知道。
不仅知道,还能预测出你要干什么。
这种全面“窥视未来”的能力,出自李飞飞团队的最新研究。
我们来(假装)看一段街头小视频。
一个人,从车后绕过来……
⏸️
画面定格,引来保安终极三问:他是谁?要去哪?干什么?
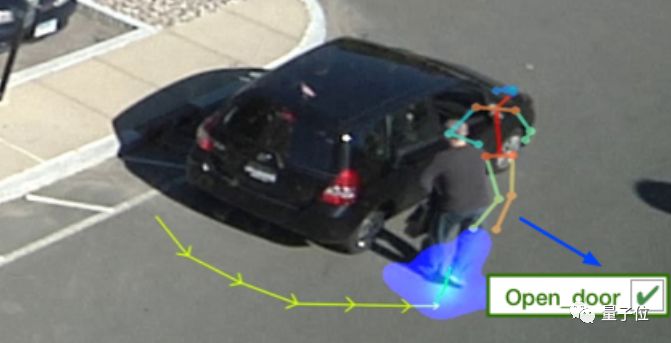
当然是继续走向车门旁边,伸手开门。
AI回答正确。(“是谁”超纲了,由其他AI负责)
提高一点难度,多拍几个人试试:
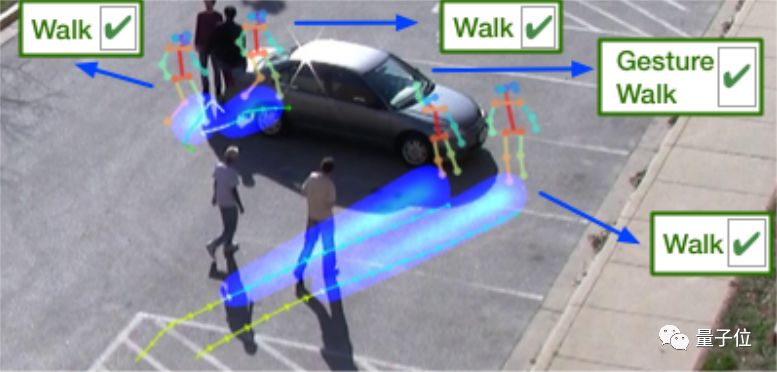
李飞飞团队的新AI还是能答对。系好安全带,发车~
这项研究,由卡耐基梅隆大学(CMU)、Google AI和斯坦福大学共同完成。
他们运用一个端到端的多任务学习系统,从画面中识别人类行为和TA与周围环境的互动情况,然后根据这些信息,预测出这名行人未来的路径和行为。
无论是预知的范围还是准确率,都比以往的研究更强。
比一比
在此之前,“窥视未来”的研究也不少,不过都只是预测人接下来的行走路径,无法预测他们干什么。
比如2018年李飞飞夫妇团队发表在CVPR上的Social GAN,代表了当时最先进的水平,却也只能预测“要去哪儿”。
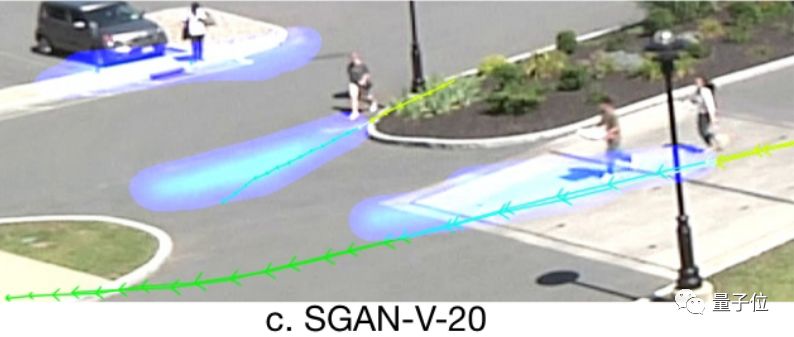
而这项最新的研究,不仅预测了人的路径,还预测出了这些人的活动。
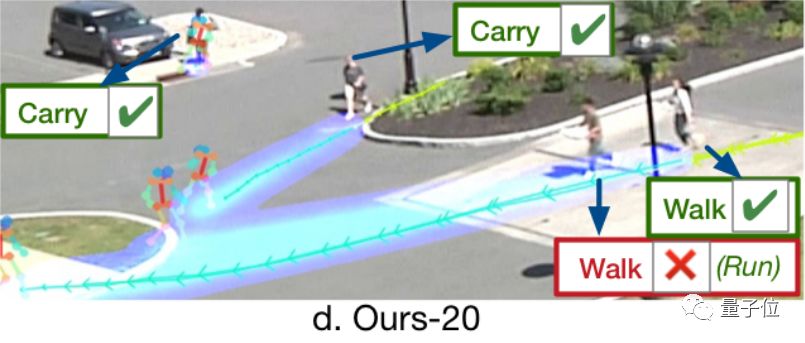
论文中说,这是首次同时预测人未来路径和活动的研究。
如果你仔细观察上图的蓝色预测轨迹,还会发现:新研究的轨迹预测能力也比以前更强了。
当然,这些是主观定性的感受,放到定量的分析中,它对路径预测的误差平均下来也是最小的。
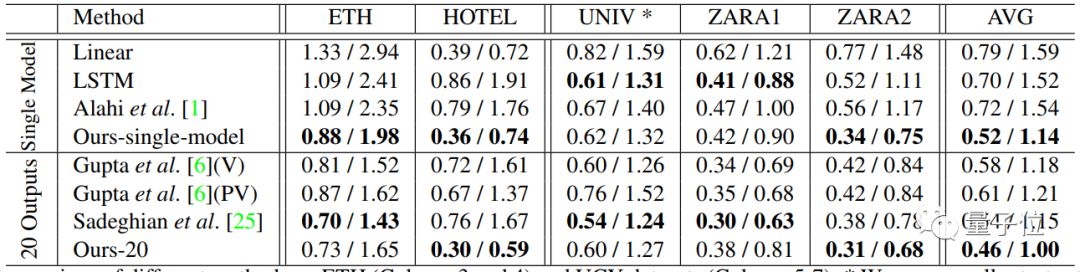
上图是各种算法在五个场景人物路径预测数据上的表现。
为了充分证明模型的性能,分成了两类,一是对单一模型结果的比较(Single Model),一是比较20个模型输出结果最优情况(20 Outputs)。
这五个场景来自两个公开的数据集。
一是ETH数据集,包括ETH(大学外部)和HOTEL(公共汽车站),二是UCY数据集,包括UNIV(大学)、ZARA1(购物街)和ZARA2(购物街)。
图表中的数据,表示人物接下来路径中12个点的预测误差,“/”左侧数据代表平均位移误差,右侧数据代表最终位移误差,数据越小越好。
各个场景平均来看(AVG),这项最新研究单一模型的平均误差比其他模型要少0.2,最终误差少0.4。20个模型输出结果最优情况中,平均误差和最终误差也都少了0.1左右。
一个算法,既能预测轨迹,又能预测行为,误差还比其他方法低。那么问题来了——
怎么做到的?
预测运动轨迹这件事,和预测行为本来就是相辅相成的。
人类走路是以特定目的为导向,了解一个人的目的,有助于推测他要去哪。
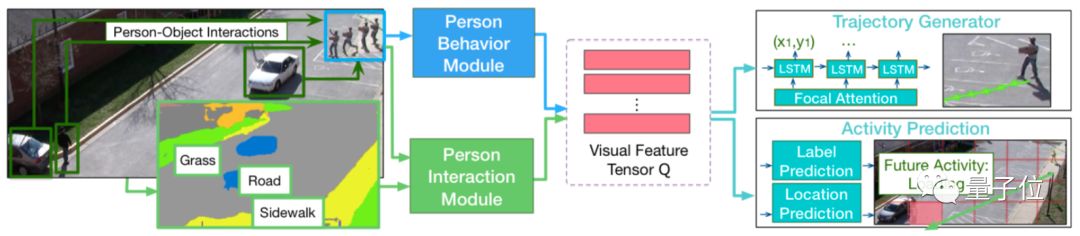
△预测模型的神经网络架构。
既然要同步预测运动轨迹和行为,就不能像以往那些研究一样,把人简化成一个点了。
这个神经网络,总共包含4部分:
人物行为模块、人物交互模块、轨迹生成器、活动预测
其中前两个模块是图像识别的部分,分别负责识别场景中每个人的动作和相互关系。
获得的信息交给LSTM编码器,压缩成一个“视觉特征张量”Q,交给剩下两部分生成轨迹和活动的预测结果。
另外,活动预测模块还能对活动即将发生的位置进行预测,弥补轨迹生成器的误差。
这四个模块的功能和工作原理,具体来说是这样的:
1、人物行为模块
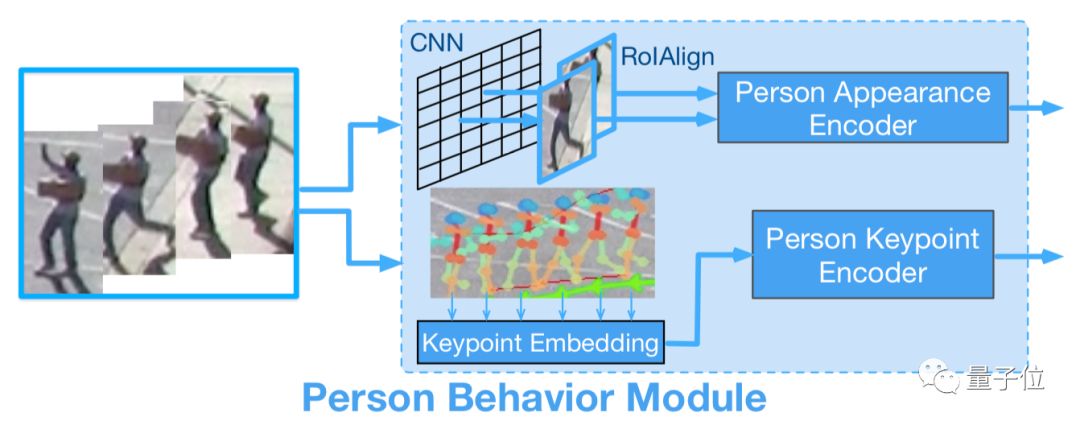
这个模块负责对场景中每个人的图像信息进行编码,除了标记人的轨迹点以外,还要对身体活动进行建模。
为了对人在场景中的变化进行建模,这里用一个预训练的带有“RoAlign”的物体检测模型,来提取每个人边界框的固定尺寸CNN特征。
除了场景以外,人物行为模块还需要获取肢体活动的信息,本文使用了一个MSCOCO数据集上训练的检测模型,来提取人体关键点信息。
以上两个部分分别输入LSTM编码器,获得场景和肢体动作的特征表示。
2、人物交互模块
这个模块负责查看人与周围环境的交互,包含人与场景、人与对象的交互。
其中人与场景的交互是为了对人附近的场景进行编码。
首先使用预训练的场景分割模型导出每一帧的像素级场景语义分类,划分出场景中的道路、人行道等部分。
然后选取适当的尺寸大小来确定模型需要识别的环境区域。例如把数值设定为3,表示选取人周围3×3大小的范围作为观察区域。
将以上不同时刻获取的信息输入LSTM编码器,最终获得了人与场景关系的特征。
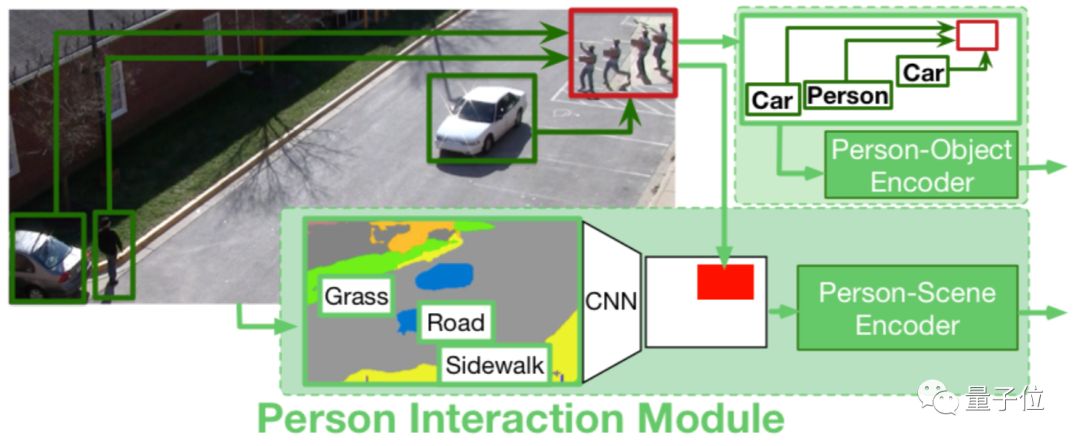
与前人的研究不同,“人与对象的交互”模块可以对场景中所有对象与人的几何关系和类型进行建模,并根据几何距离来计算人与其他对象的关系,而不仅仅只关注与周围近邻的关系。
但是人的轨迹更容易受到近距离物体或人的影响,文中使用对数函数作为权重,来反映不同距离人或物体对轨迹的影响。实际效果也证明了这种编码方式是有效的。
下一步,将某个时刻的几何特征和对象类型特征嵌入到多维向量中,并将嵌入的特征馈送到LSTM编码器中。
由人与其他人、汽车之间的距离,可以获得人与物体的关系特征;由人是靠近人行道还是草地,可以判定人物场景特征。
将这些信息提供给模型,让它能学习到人类的活动方式。比如一个人在人行道上比在草地上走得更频繁,并且会倾向于避免撞到汽车。
3、轨迹生成器
上面两个模块提取的4种特征,包括场景、肢体动作、人与场景和人与对象关系等信息,由单独的LSTM编码器压缩成视觉特征张量Q。
接下来使用LSTM解码器直接解码,在实际平面坐标上预测未来的轨迹。
这项研究用了一种焦点注意力的机制。它起初源于多模态推理,用于多张图片的视觉问答。其关键之处是将多个特征投射到相关空间中,在这个空间中,辨别特征更容易被这种注意力机制捕获。
焦点注意力对不同特征的关系进行建模,并把它们汇总到一个低维向量中。
4、活动预测
活动预测模块有两个任务,确定活动发生的地点和活动的类型。
相应地,它包含两个部分,曼哈顿网格的活动位置预测和活动标签预测。
活动标签预测的作用是猜出画面中的人最后的目的是什么,预测未来某个瞬间的活动。活动标签在某一时刻并不限于一种,比如一个人可以同时走路和携带物品。
而活动位置预测的功能,是为轨迹生成器纠错。

轨迹生成器有个缺点,预测位置的误差会随着时间累计而增大,最终目的地会偏离实际位置。
为了克服这个缺点,就有了“活动位置预测”这项辅助任务。它确定人的最终目的地,以弥补轨迹生成器和活动标签预测之间的偏差。包括位置分类和位置回归两个任务。
位置分类的目的是预测最终位置坐标所在的网格块。位置回归的目标是预测网格块中心(图中的蓝点)与最终位置坐标(红色箭头的末端)的偏差。
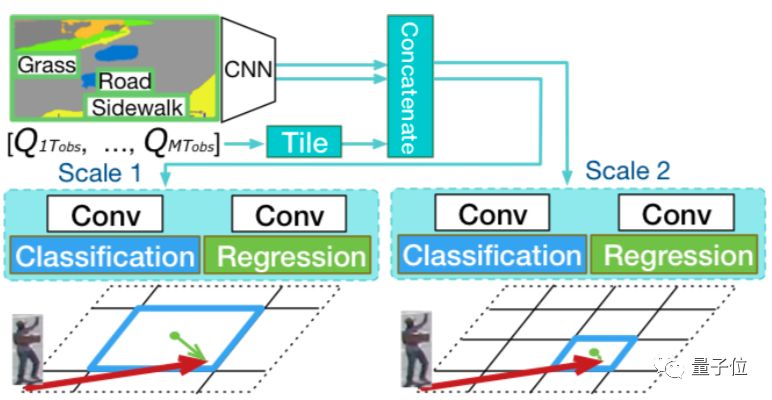
添加回归任务的原因是,它能提供比网格区域更精确的位置。
还有很长的路要走
虽然模型设计中,考虑的非常周到,但面对现实情况时,仍旧会出现种种失败案例:
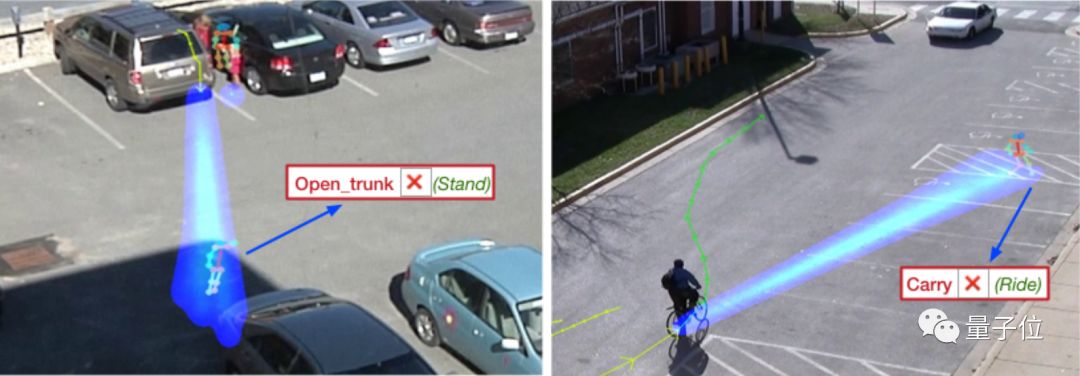
左边,预测人物要打开后备箱,但实际上是他只是站着。
右边,预测任务将会向右前方前进,提着一些东西,但实际上他一直骑行,并向左前方拐弯,全然不顾前方即将到来的车辆。
从这些情况来看,模型应对一些场景还有些吃力。
此外,这个AI目前仅适用于美国国家标准局提供预定义的30个人类活动,例如关门、开门、关后备箱、开后备箱、提东西、打招呼、推、拉、骑自行车、跑、步行等等。

研究道路千万条,这是第一条。
随着研究的成熟,在自动化社会中,人类这一最不稳定的变量也就将会在控制之中。
未来,自动驾驶的汽车,可能再也不用担心横冲直撞的行人了,机器人也会与人类“和谐相处”了,毕竟人类想要干什么,系统都了如指掌。
如果你对这个领域感兴趣,还请收好这篇论文的传送门:

Peeking into the Future:Predicting Future Person Activities and Locations in Video
https://arxiv.org/abs/1902.03748
— 完 —
加入社群
量子位现开放「AI+行业」社群,面向AI行业相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群,在量子位公众号(QbitAI)对话界面回复关键词“行业群”,获取入群方式。行业群会有审核,敬请谅解。
此外,量子位AI社群正在招募,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式。
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !


