【干货】PyTorch实例:用ResNet进行交通标志分类
来源:专知
【导读】本文是机器学习工程师Pavel Surmenok撰写的一篇技术博客,用Pytorch实现ResNet网络,并用德国交通标志识别基准数据集进行实验。文中分别介绍了数据集、实验方法、代码、准备工作,并对图像增强、学习率、模型微调、误差分析等步骤进行详细介绍。文章中给出了GitHub代码,本文是一篇学习PyTorch和ResNet的很好的实例教程。

ResNet for Traffic Sign Classification With PyTorch
德国交通标志识别基准数据集:可能是自动驾驶汽车领域最受欢迎的图像分类数据集。 自动驾驶车辆需要对交通标志进行检测和分类,以了解应用于路段的交通规则。 也许,这个数据集太小而且不完整,无法用于实际应用。 不过,它是计算机视觉算法的一个很好的baseline。
数据集链接:
[http://benchmark.ini.rub.de/?section=gtsrb&subsection=about]
▌数据集
数据集由两部分组成:训练集和测试集。 训练集包含39209张交通标志图片, 共分为43类,例如停车标志,自行车穿越和速度限制30 km / h。

数据集的样本类别非常不均衡(imbalanced)。例如,“速度限制(50 km / h)”符号有1800个样本,但“危险曲线向左”符号只有168个。
测试集具有12630张图片。2011年IJCNN就是用这个数据集进行了一场比赛.
您可以从官方网站下载数据集。
http://benchmark.ini.rub.de/?section=gtsrb&subsection=dataset
▌实验方法
我尝试使用在ImageNet数据集上预训练的ResNet34卷积神经网络来进行迁移学习。
我在fast.ai最新版本的“深入学习编码器”课程中学到了解决计算机视觉问题的方法。去年我在旧金山大学参加了该课程的离线版本。该课程使用fastai,这是一个建立在PyTorch之上的深度学习库。它提供了易于使用的模块来训练深度学习模型。
我大部分时间都在优化超参数和调整图像增强。
▌代码
我在GitHub上发布了我的代码。您可以下载Jupyter笔记本,其中包含从下载数据集到创建基于未标记测试集的提交文件的所有步骤。CNN模型的训练代码大多基于fast.ai的CNN课程。
https://github.com/surmenok/GTSRB/blob/master/german-traffic-signs.ipynb
https://github.com/surmenok/GTSRB
我们来完成训练和评估模型的步骤。
▌准备工作
准备环境。我必须安装fastai库及其所有依赖项。
下载数据集并解压缩。将训练集(39209图像)分成训练和验证集,并将文件移动到正确的文件夹。我用80%的样本进行训练,20%的样本用于验证。
分割数据集时要小心。该数据集包含每个交通标志的30张照片。根据文件名区分类别是很容易的。如果您只是随机分割数据集,那么将会有验证集中的信息泄漏到训练集。
我在一开始就犯了这个错误。我随机分割数据集,获得了超过99.6%的惊人的良好验证准确性。当测试准确性仅为87%时,我感到很惊讶: 测试准确性和验证准确性之间的巨大差异是验证集设计不当或过度拟合验证集。
正确的方法是找到一系列图像,并将每个系列全部放入训练或验证集中,确保它们不会分割成两个。要了解关于创建一个好的验证集的更多信息,请阅读Rachel Thomas撰写的这篇文章。
www.fast.ai/2017/11/13/validation-sets/
▌探索性分析
探索数据集。检查类分布,查看每个类的几个图像示例。
图像有不同的大小。看看大小直方图。它会让你了解CNN的输入尺寸应该是什么。
▌训练
加载在ImageNet数据集上预训练的ResNet34模型。删除最后一层并在顶部添加一个新的softmax层。
arch = resnet34
learn = ConvLearner.pretrained(arch, data, precompute=False)
为了加快训练速度, 我挑选了一些尺寸较小的图片作为输入,(我从32x32图像大小开始)并缩小训练轮次(总共7个epochs)。理想情况下,实验不应超过几分钟。
另外,我尝试优化batch size。尝试使batch size与GPU内存允许的一样大。较大的批量有助于缩短培训时间。但是,在实验中,我发现过大的batch(例如1024个样本和更多)会导致较低的验证准确度。我猜这个模型很早就开始过度配合。我最终batch size为256。
在找到一组合适的超参数后,我才切换到在更大的图像上进行更长时间的细粒度训练。我最终使用96x96图像和19个epoch的训练。
▌图像增强
设置图像增强。这是一种帮助模型更好地泛化的技术。你可以在训练集中增加很多人为的样本。这些样本是基于现有的图片的,你只需要稍微加点操作:旋转几度,更改光照,放大等。
sz = 96
# Look at examples of image augmentation
def get_augs():
x,_ = next(iter(data.aug_dl))
return data.trn_ds.denorm(x)[1]
aug_tfms = [RandomRotate(20), RandomLighting(0.8, 0.8)]
tfms = tfms_from_model(arch, sz, aug_tfms=aug_tfms, max_zoom=1.2)
data = ImageClassifierData.from_paths(path, tfms=tfms, test_name='test')
ims = np.stack([get_augs() for i in range(6)])
plots(ims, rows=2)

我使用了以下转换的组合:旋转20度,照明变化80%,并放大至20%。
亮度增强非常重要。 在项目的早期阶段,我注意到比较暗的图像的结果往往不好,在使用了亮度增强之后, 结果提高了3%以上。 亮度改变是通过直接改变R,G和B通道的值来完成的。 有关详细信息,请参阅RandomLighting类。
当然, 我也试过其他东西, 比如:用直方图均衡化以提高对比度,随机模糊,填充, 但是他们都不work.
▌学习率
使用这里描述的算法搜索一个好的起始学习率。
https://towardsdatascience.com/estimating-optimal-learning-rate-for-a-deep-neural-network-ce32f2556ce0
def plot_loss_change(sched, sma=1, n_skip=20, y_lim=(-0.01, 0.01)):
"""
Plots rate of change of the loss function.
Parameters:
sched - learning rate scheduler, an instance of LR_Finder class.
sma - number of batches for simple moving average to smooth out the curve.
n_skip - number of batches to skip on the left.
y_lim - limits for the y axis.
"""
derivatives = [0] * (sma + 1)
for i in range(1 + sma, len(learn.sched.lrs)):
derivative = (learn.sched.losses[i] - learn.sched.losses[i - sma]) / sma
derivatives.append(derivative)
plt.ylabel("d/loss")
plt.xlabel("learning rate (log scale)")
plt.plot(learn.sched.lrs[n_skip:], derivatives[n_skip:])
plt.xscale('log')
plt.ylim(y_lim)
learn.lr_find()
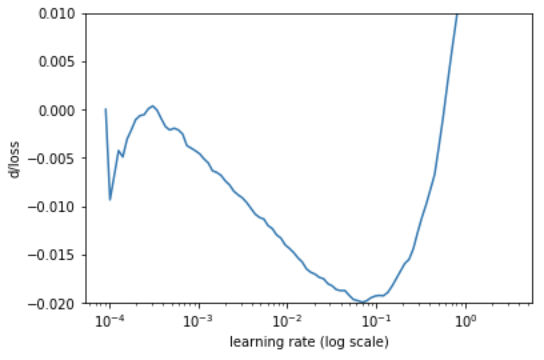
▌微调最后一层
冻结除最后一层之外的所有层的参数。 用这种学习速度训练模型一个epoch。 就我而言,学习率为0.01。 这是为了获得最后一层的合理权重。 如果我们不这样做,比如稍后再训练一个未冻结的模型那么低层的参数会非常混乱,因为梯度会更大。 我尝试了两种选择,并且对最后一层进行训练,一个epoch的验证精度提高了1%。 我也使用了权重衰减进行一些小改进。
wd = 5e-4
learn.fit(0.01, 1, wds=wd)
▌微调整个模型
取消冻结所有层。 训练三个迭代。
learn.unfreeze()
learn.fit(0.01, 3, wds=wd)
然后训练使用随机梯度下降与热重启(SGDR)训练几个迭代。
learn.fit(lr, 4, cycle_len=1, cycle_mult=2, wds=wd)
我试图使用discriminative fine-tuning,为模型的不同部分设置不同的学习率。在这种情况下,我们训练模型的第一层比最后一层少。第一层比其他层更通用。在ImageNet数据集上进行训练时,这些层会学习对我们的任务非常有用的模式,而且我们不想丢失这些知识。另一方面,最后一层跟任务非常相关, 我们需要重新训练以更好的完成我们的目标。可惜,这并没有帮助改进任何指标。如果您对所有层应用较大的学习率,模型训练会更好。我想这是因为交通标志与狗,猫和飞机非常不同,因此较低层的信息不如在其他计算机视觉应用中那样有用。
验证集合中最佳模型的准确度为99.0302%。
▌误差分析
除了像混淆矩阵这样的常用工具外,您还可以通过检查几个极端情况来分析错误:大多数不正确的预测,最正确的预测,最不确定的预测。
要为每个类找到最不正确的预测,您必须在验证集上运行推理,并选择正确类的预测概率最小的示例。
log_preds,y = learn.predict_with_targs()
preds = np.exp(log_preds)
pred_labels = np.argmax(preds, axis=1)
results = ImageModelResults(data.val_ds, log_preds)
results.plot_most_incorrect(1)

这些图像看起来太模糊,太亮。
同样,你可以找到例子,其中最高的概率分配给正确的类(“最正确的”)和例子,其中正确的类的概率接近1 / num_classes(“最不确定”)。
此分析的结果可帮助您调整图像增强参数,并可能调整模型的某些超参数。
▌重新训练整个训练集
在之前的所有步骤中,我们使用了80%的训练集和20%的训练集进行了验证。现在,当我们找到了好的超参数时,我们不再需要验证集,并且可以将这20%的图像添加到训练集中,以进一步改善模型。
在这里,我只是用相同的参数重新运行所有训练步骤,但使用所有32909训练图像进行训练。
▌在测试集上进行测试
测试集(12630幅图像)旨在测试最终模型的性能。我们没有在前面的步骤中查看测试集以避免过度拟合测试集。现在,我们可以在测试集上评估模型。我在测试集上获得了99.2953%的准确度。非常好!那么我们可以进一步改进吗?
▌测试时间增加
测试时间增加(Test-time augmentation, TTA)通常有助于提高精度。诀窍是创建输入图像的几个增强版本,对它们中的每一个运行预测,然后计算平均结果。这背后的思想是,模型在分类某些图像时可能是错误的,但稍微改变图像可以帮助模型更好地对其进行分类。就好像一个人想分类一个物体,然后他们从不同的角度看它,改变一点点光线,把它移近眼睛,直到它们能找到最有利于最有把握地识别物体的视点。
log_preds,_ = learn.TTA(n_aug=20, is_test=True)
preds = np.mean(np.exp(log_preds),0)
accuracy_np(preds, y_true)
事实上,TTA帮助我将准确度从99.2953%提高到了99.6120%。 它将误差降低了45%(从0.7047%降至0.388%)。
▌它有多好?
测试集的准确度为99.6120%。 我们来比较几个benchmarks。
最好的技术是Mrinal Haloi提供的基于Inception的CNN(https://arxiv.org/abs/1511.02992)。达到99.81%。 错误率比我的好两倍。
2011年IJCNN竞赛排行榜排名:
• CNN与ÁlvaroArcos-García等人的3个空间变换器99.71%
• DanCireşan等人的CNN。99.46%
• 基于颜色斑点的COSFIRE过滤器,用于由Baris Gecer进行物体识别,98.97%
如果我的模型参加了比赛,那将是第二名。 总的来说,这几天的工作不错。
▌参考链接:
德国交通标志识别基准数据集:
benchmark.ini.rub.de/?section=gtsrb&subsection=about
fast.ai最新版本的“深入学习编码器”课程:
course.fast.ai
GitHub:
https://github.com/surmenok/GTSRB
fastai:
https://github.com/fastai/fastai
CNN with 3 spatial transformers:
https://linkinghub.elsevier.com/retrieve/pii/S0893608018300054
Committee of CNNs:
https://www.sciencedirect.com/science/article/pii/S0893608012000524?via%3Dihub
Color-blob-based COSFIRE blters for object recognition:
dx.doi.org/10.1016/j.imavis.2016.10.006
参考链接:
https://towardsdatascience.com/resnet-for-traffic-sign-classification-with-pytorch-5883a97bbaa3
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【深度】DeepMind提出图形的「深度生成式模型」,可实现「任意」图形的生成
☞【学界】CVPR 2018 | 优于Mask R-CNN,港中文&腾讯优图提出PANet实例分割框架
☞【深度】用可组合的构建块丰富用户界面?谷歌提出「可解释性」的最新诠释



