用卷积神经网络模型辨认不同时尚服装,四种方法对比
在实体店买衣服的过程中,我们会被眼花缭乱的信息轰炸。要兼顾某件衣服的款式、价格、商场优惠还不够,商场的灯光、拥挤的过道,无时无刻不在考验着人们分辨信息的能力。
那么,电脑能自动检测衬衫、裤子、连衣裙或运动鞋的照片吗?事实证明,如果有高质量的训练数据,准确地对时尚单品图片进行分类是很很容易做到的。在本文中,我们将讲解如何用Fashion-MNIST数据集搭建一个用于辨认时尚单品的机器学习模型。我们会提到如何训练模型、针对类别分类设计输入和输出以及每个模型的最终结果。
图像分类
这一任务中涉及到的问题包括视角的变化、尺度变化、同类的多种变化、照片形变、照片遮挡、光线条件、背景等问题。如何写出一套可以区分图片类型的算法呢?计算机视觉研究人员提出了一种数据驱动的方法来解决。过去,人们会了解每一图片类别的代码,从而进行分类。现在,研究人员从每类图像中都选出一些样本,训练深度学习算法学习每种类别的特点。换句话说,他们首先收集带标签的训练数据集,然后输入到计算机中,让计算机熟悉这些数据。
主要步骤如下:
输入的是一个含有N张图片的数据集,每张图片都带有类别标签,数据集中共有K个不同的类别。
之后,我们用训练集去训练一个分类器,学习每种类别的样式。
最后,让分类器对陌生图片进行标签预测,从而对分类器质量进行评估。之后我们会比较真实标签和分类器的预测标签。
Fashion MNIST数据集
去年八月份,德国研究机构Zalando Research在GitHub上推出了一个全新的数据集,其中训练集包含60000个样例,测试集包含10000个样例,分为10类,其中的样本都来自日常穿着的衣裤鞋包,每个都是28×28的灰度图像,其中总共有10类标签,每张图像都有各自的标签。

10种标签包括:
0:T-shirt/上衣
1:裤子
2:套头衫
3:连衣裙
4:大衣
5:凉鞋
6:衬衣
7:运动鞋
8:包
9:高帮鞋
Fashion MNIST的可视化嵌入
嵌入是一种将分散目标(图像、文字等等)映射到高维向量中的方法。这些向量中的每个维度通常都没有内在意义,机器学习运用的是想两件的距离和总体的模式。在这里,我打算用TensorBoard表示高维的Fashion MNIST数据。阅读了数据并创建测试标签后,我用以下代码创建了TensorBoard的嵌入投射器:
from tensorflow.contrib.tensorboard.plugins import projector
logdir = 'fashionMNIST-logs'
# Creating the embedding variable with all the images defined above under X_test
embedding_var = tf.Variable(X_test, name='fmnist_embedding')
# Format: tensorflow/contrib/tensorboard/plugins/projector/projector_config.proto
config = projector.ProjectorConfig()
# You can add multiple embeddings. Here I add only one.
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(logdir, 'metadata.tsv')
# Use this logdir to create a summary writer
summary_writer = tf.summary.FileWriter(logdir)
# The next line writes a projector_config.pbtxt in the logdir. TensorBoard will read this file during startup.
projector.visualize_embeddings(summary_writer,config)
# Periodically save the model variables in a checkpoint in logdir.
with tf.Session() as sesh:
sesh.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sesh, os.path.join(logdir, 'model.ckpt'))
# Create the sprite image
rows = 28
cols = 28
label = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
sprite_dim = int(np.sqrt(X_test.shape[0]))
sprite_image = np.ones((cols * sprite_dim, rows * sprite_dim))
index = 0
labels = []
for i in range(sprite_dim):
for j in range(sprite_dim):
labels.append(label[int(Y_test[index])])
sprite_image[
i * cols: (i + 1) * cols,
j * rows: (j + 1) * rows
] = X_test[index].reshape(28, 28) * -1 + 1
index += 1
# After constructing the sprite, I need to tell the Embedding Projector where to find it
embedding.sprite.image_path = os.path.join(logdir, 'sprite.png')
embedding.sprite.single_image_dim.extend([28, 28])
# Create the metadata (labels) file
with open(embedding.metadata_path, 'w') as meta:
meta.write('Index\tLabel\n')
for index, label in enumerate(labels):
meta.write('{}\t{}\n'.format(index, label))
该投射器有三种对数据集降维的方法,两种线性方法,一种非线性方法。每种方法都能用于创建二维或三维场景。
PCA:PCA是一种用于直接降维的技术,嵌入投射器计算前十位的主要成分,通过菜单,我们可以将那些成分投射成任意两种或三种的结合上。PCA是一个线性工具,通常在检查全局几何结构上非常高效。

t-SNE:这是一种流行的非线性降维方法,嵌入投射器会同时提供二维和三维的t-SNE视图。在客户端可以看到平面图,能展示出每一步算法。由于t-SNE通常会保留一些局部结构,这在探索局部近邻、找寻聚类中是很有用的。

Custom:我还可以基于文本搜索创建特殊的线性投射器,用于在空间中寻找有意义的方向。程序可以计算这些点集的中心点,他们的标签可以与搜索匹配,利用向量之间的不同作为投射器的轴。

查看完成的可视化步骤代码,可点击此网址:github.com/khanhnamle1994/fashion-mnist/blob/master/TensorBoard-Visualization.ipynb
在Fashion MNIST上训练CNN模型
接下来,我会创建多个基于CNN的分类模型,在Fashion MNIST上评估模型性能。我会用Keras框架搭建模型,想了解框架的更多信息,可以点击此网址:keras.io/。下面是我想要比较的四种模型:
有一层卷积层的CNN
有三层卷积层的CNN
有四层卷积层的CNN
经过与训练的VGG-19模型
除了预训练模型,我的实验方法如下:
将原始训练数据(共60000张图片)分成训练集和验证集两部分,80%是训练集,20%是验证集,另外还有10000张测试图片,用于最终测试模型在陌生图像上的表现。这可以研究模型是否在训练数据上过度拟合,以及是否应该降低学习速率。
用256的batch size训练模型10个epoch,同时用categorical_crossentropy损失函数和Adam优化器共同编译。
之后进行数据增强,可以通过旋转、变化、缩放生成新的训练样本,再通过50个epoch对模型进行训练。
以下是下载数据并分离数据的代码:
# Import libraries
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# Load training and test data into dataframes
data_train = pd.read_csv('data/fashion-mnist_train.csv')
data_test = pd.read_csv('data/fashion-mnist_test.csv')
# X forms the training images, and y forms the training labels
X = np.array(data_train.iloc[:, 1:])
y = to_categorical(np.array(data_train.iloc[:, 0]))
# Here I split original training data to sub-training (80%) and validation data (20%)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=13)
# X_test forms the test images, and y_test forms the test labels
X_test = np.array(data_test.iloc[:, 1:])
y_test = to_categorical(np.array(data_test.iloc[:, 0]))
下载数据后,我会重新处理它们,让它们的值处于0到1之间。此前,训练数据都被存储在一个(60000,28,28)的数组中,其中的值在0到255之间。
# Each image's dimension is 28 x 28
img_rows, img_cols = 28, 28
input_shape = (img_rows, img_cols, 1)
# Prepare the training images
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_train = X_train.astype('float32')
X_train /= 255
# Prepare the test images
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
X_test = X_test.astype('float32')
X_test /= 255
# Prepare the validation images
X_val = X_val.reshape(X_val.shape[0], img_rows, img_cols, 1)
X_val = X_val.astype('float32')
X_val /= 255
一层卷积层CNN
下面是只有一层卷积层的CNN代码:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
cnn1 = Sequential()
cnn1.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
cnn1.add(MaxPooling2D(pool_size=(2, 2)))
cnn1.add(Dropout(0.2))
cnn1.add(Flatten())
cnn1.add(Dense(128, activation='relu'))
cnn1.add(Dense(10, activation='softmax'))
cnn1.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
训练完模型后,下面是测试损失和测试精确度:

进行数据增强后的测试损失和测试精确度:

训练和验证精确度和损失的可视化:
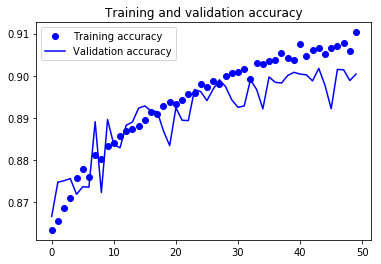
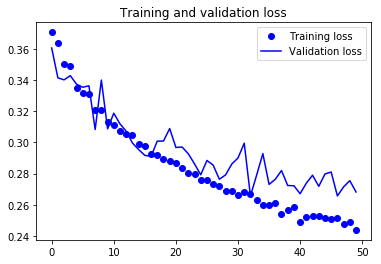
完整代码请点击:github.com/khanhnamle1994/fashion-mnist/blob/master/CNN-1Conv.ipynb
三层卷积层CNN
有三层卷积层的CNN代码:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
cnn3 = Sequential()
cnn3.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
cnn3.add(MaxPooling2D((2, 2)))
cnn3.add(Dropout(0.25))
cnn3.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
cnn3.add(MaxPooling2D(pool_size=(2, 2)))
cnn3.add(Dropout(0.25))
cnn3.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
cnn3.add(Dropout(0.4))
cnn3.add(Flatten())
cnn3.add(Dense(128, activation='relu'))
cnn3.add(Dropout(0.3))
cnn3.add(Dense(10, activation='softmax'))
cnn3.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
训练模型后,测试损失和测试精确度:

数据增强后的测试损失和精确度:

训练和验证的精确度和损失:
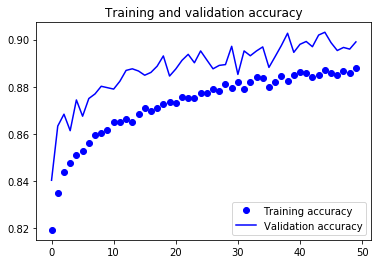
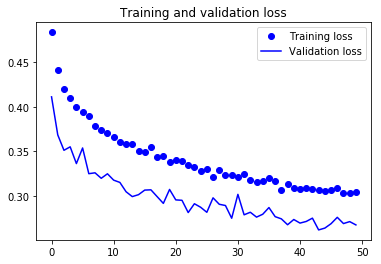
完整代码请点击:github.com/khanhnamle1994/fashion-mnist/blob/master/CNN-3Conv.ipynb
四层卷积层的CNN
下面是四层卷积层的CNN代码:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, BatchNormalization
cnn4 = Sequential()
cnn4.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
cnn4.add(BatchNormalization())
cnn4.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(MaxPooling2D(pool_size=(2, 2)))
cnn4.add(Dropout(0.25))
cnn4.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.25))
cnn4.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(MaxPooling2D(pool_size=(2, 2)))
cnn4.add(Dropout(0.25))
cnn4.add(Flatten())
cnn4.add(Dense(512, activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.5))
cnn4.add(Dense(128, activation='relu'))
cnn4.add(BatchNormalization())
cnn4.add(Dropout(0.5))
cnn4.add(Dense(10, activation='softmax'))
cnn4.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
训练模型后的测试损失和精确度:

数据增强后的测试损失和精确度:

训练和验证的精确度和损失:
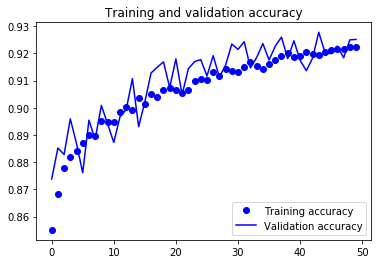
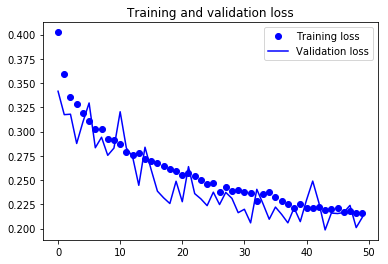
完整代码请点击:github.com/khanhnamle1994/fashion-mnist/blob/master/CNN-4Conv.ipynb
迁移学习
在小数据集上常用的一种高效深度学习方法就是使用预训练网络。一种预训练网络是此前在大型数据集上训练过的网络,通常处理过大型图像分类任务。如果这样的原始数据集足够大并且足够通用,那么预训练网络学习到的特征空间分层可以用于视觉世界的普通模型,它的特征可以解决很多不同的计算机视觉问题。
我尝试使用VGG19预训练模型,这在ImageNet中广泛使用的ConvNets架构。以下是所用的代码:
import keras
from keras.applications import VGG19
from keras.applications.vgg19 import preprocess_input
from keras.layers import Dense, Dropout
from keras.models import Model
from keras import models
from keras import layers
from keras import optimizers
# Create the base model of VGG19
vgg19 = VGG19(weights='imagenet', include_top=False, input_shape = (150, 150, 3), classes = 10)
# Preprocessing the input
X_train = preprocess_input(X_train)
X_val = preprocess_input(X_val)
X_test = preprocess_input(X_test)
# Extracting features
train_features = vgg19.predict(np.array(X_train), batch_size=256, verbose=1)
test_features = vgg19.predict(np.array(X_test), batch_size=256, verbose=1)
val_features = vgg19.predict(np.array(X_val), batch_size=256, verbose=1)
# Flatten extracted features
train_features = np.reshape(train_features, (48000, 4*4*512))
test_features = np.reshape(test_features, (10000, 4*4*512))
val_features = np.reshape(val_features, (12000, 4*4*512))
# Add Dense and Dropout layers on top of VGG19 pre-trained
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(10, activation="softmax"))
# Compile the model
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
模型训练后,测试损失和精确度如下:

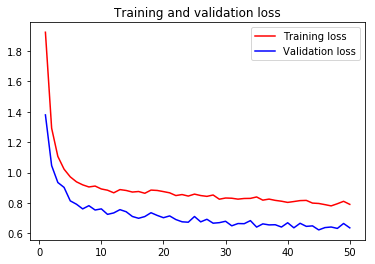
可视化:
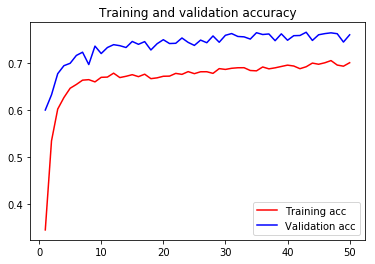
结语
时尚领域是计算机视觉和机器学习应用的热门,由于其中的予以复杂性,导致问题难度增加。希望这篇文章能对你在图像分类任务上有所启发。
原文地址:towardsdatascience.com/the-4-convolutional-neural-network-models-that-can-classify-your-fashion-images-9fe7f3e5399d

星标论智,每天获取最新资讯