如何加速训练和预测?增大模型吧

相关阅读推荐:更小的模型!迈向更快更环保的NLP
模型训练可能很慢
在深度学习中,使用更多计算,例如增加模型大小,数据集大小或训练步骤,通常会导致更高的准确性。尤其是考虑到像BERT这样的无监督预训练方法最近取得成功之后,这种方法可以将训练扩展到非常大的模型和数据集。不幸的是,大规模训练在计算上非常昂贵。因此,实践中的目标通常是在不超出硬件预算和训练时间的情况下获得尽可能的高精度。
对于大多数训练预算来说,非常大的模型似乎不切实际。取而代之的是,要使训练效率最大化,首选策略是使用具有较小hidden size或较少层的模型,因为这些模型运行速度更快且使用的内存更少。
更大的模型训练更快
但是,在最近的论文,Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers[1]中,指出减小模型大小的这种常规做法实际上与最佳计算效率的训练策略恰恰相反。在有限预算条件下训练Transformer模型时,要大幅度增加模型大小,但要尽早停止训练。换句话说,这篇论文通过展示在牺牲收敛性的同时增加模型大小,来重新思考模型必须被训练直到收敛的隐含假设。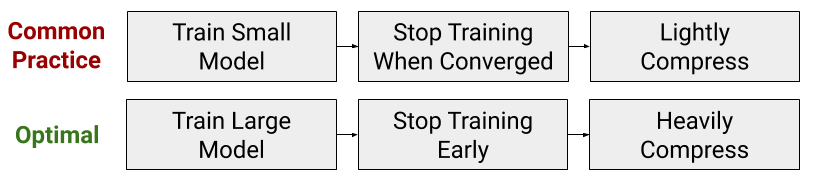
在下面的两条训练曲线中证明了这种趋势。
-
在左侧,绘制了RoBERTa的验证误差。在给定的时间内,较深的RoBERTa模型比较浅的模型具有更低的困惑度(论文表明,较宽的模型也是如此)。这种趋势也适用于机器翻译任务。 -
在右侧,当训练英语-法语Transformer机器翻译模型时,绘制了验证的BLEU分数(越高越好)。在相同的训练时间下,更深,更宽的模型比小的模型获得更高的BLEU分数。
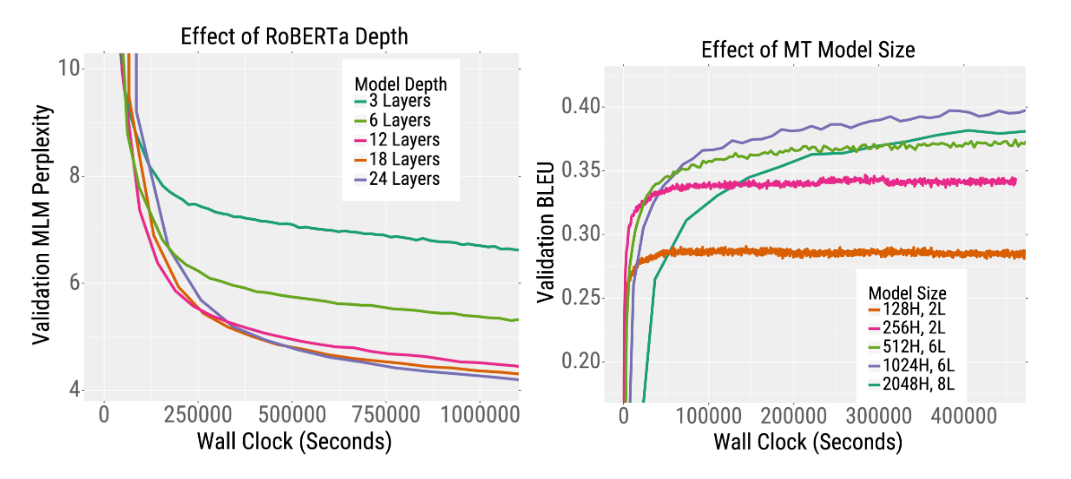
有趣的是,对于RoBERTa的预训练,增加模型的宽度和深度都会导致更快的训练。对于机器翻译,较宽的模型优于较深的模型。因此建议在更深之前尝试增加宽度。
此外,论文还建议首先增加模型大小,而不是批量大小。具体而言,一旦批次大小接近临界范围,增加批次大小只会在固定训练时间上带来微不足道的改善。因此,在资源有限的情况下,建议在此关键区域内使用固定批处理大小,然后再使用较大的模型大小。
预测效率
尽管较大的模型训练效率更高,但是它们也增加了推理的计算和存储要求。这是有问题的,因为推理的总成本比大多数实际应用中的训练成本要大得多。但是,对于RoBERTa,论文作者证明了这种折衷可以与模型压缩相协调。特别是,大型模型比小型模型对模型压缩更健壮 因此,可以通过训练非常大的模型然后对其进行大量压缩来获得两全其美的效果。
作者使用「量化」和「修剪」的压缩方法。量化以低精度格式存储模型权重;修剪会将某些神经网络权重设置为零。两种方法都可以减少推理延迟和存储模型权重的内存需求。
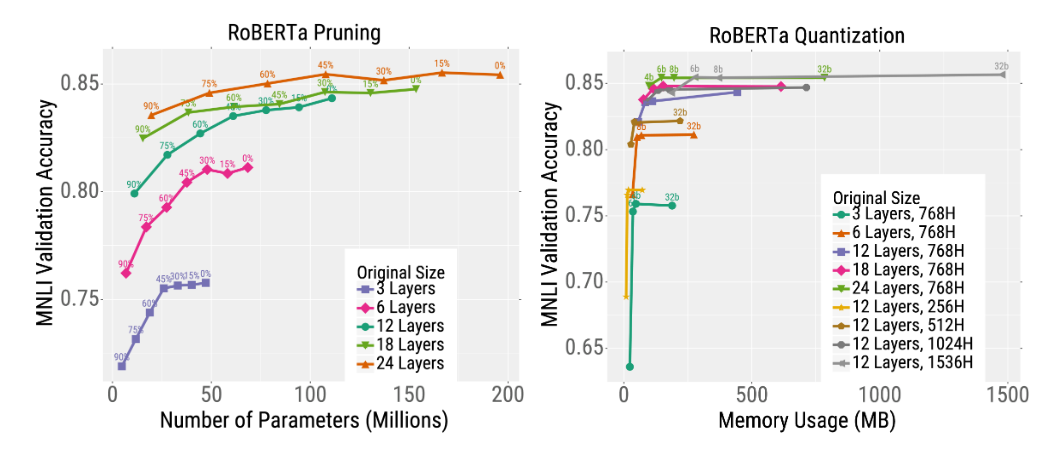
首先以相同的总时间对不同尺寸的RoBERTa模型进行预训练。然后,在下游文本分类任务(MNLI)上微调这些模型,并应用修剪或量化。结果发现,对于给定的测试时间预算,最好的模型是训练得非常大然后压缩严重的模型。
例如,考虑最深模型的修剪结果(下图左图中的橙色曲线)。在不修剪模型的情况下,它可以达到很高的精度,但是使用大约2亿个参数(因此需要大量的内存和计算量)。但是,可以对该模型进行严重修剪(沿着曲线向左移动的那些点),而不会显著降低精度。这与较小的模型形成鲜明对比,例如,粉红色表示的6层模型,其修剪后精度会大大降低。量化也出现类似趋势(下图右图)。总体而言,对于大多数测试预算(在x轴上选取一个点),最好的模型是非常大但压缩程度很高的模型。
随便唠唠
增加Transformer模型的大小可以提高训练和推理的效率,即应该先训练大然后严重压缩。这一发现引发了许多其他有趣的问题,例如,为什么大型模型收敛更快,压缩效果更好,是否跟彩票假说有什么猫腻(更小的模型!迈向更快更环保的NLP)。这些等等问题在论文中有给出初步研究,此外在作者(@Eric_Wallace_)的Twitter发文中也被大家热烈讨论。
本文参考资料
Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers: https://arxiv.org/abs/2002.11794 https://bair.berkeley.edu/blog/2020/03/05/compress/
- END -

推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




