前言
当前问题与挑战
原生支持文件、目录语义还不够,开源大数据领域常用的 HDFS 能力成为刚需。Block 模式提供了文件元数据管理,解决了 HDFS 重度用户使用 OSS 的痛点,同时这部分用户对 HDFS 重要功能也有越来越多的期待,这样迁移过来的时候可以继续使用原来在 HDFS 上的投入和资产。因此 JindoFS 开发了大量的 HDFS 功能,比如数据加密,Ranger 鉴权,和日志审计。
存储和缓存做成一套系统对中小用户确实很友好,但设计上很难满足大规模部署和更加碎片化的计算场景。JindoFS 在存储部分表现得越来越像 HDFS,越来越复杂;在缓存部分涌现的需求主要是在更多的计算场景支持更好的策略来做数据访问加速,Hadoop 不再是唯一。前者要求存储功能强大和完善,满足大规模部署;后者要求保持存储功能兼容和不变,在业务透明的情况下选择各种缓存策略进行加速。这两部分功能其实是正交的,co-design 做在一起确实对文件读写更加高效,只需要访问 JindoFS master 一次,不需要往分开的两个系统跑两趟分别拿文件元信息和缓存信息。
-
半托管部署性能最好,云原生和跨产品访问的诉求日益迫切。 原来 Hadoop 平台比较强势,大数据上云本质上就是把线下的 Hadoop 一整套搬到云上来,现在则不一样,阿里云上有非常丰富的计算产品支持,大数据上云不再只是上 Hadoop,因此 JindoFS 除了半托管部署,我们需要支持全托管服务化,构建统一的数据湖存储,方便更多的计算产品在存储方案上拉通对齐。所谓数据湖架构,就是存储统一用一套,支持计算开放百家争鸣。
解决方案:将数据湖文件系统JindoFS 打造成为HDFS
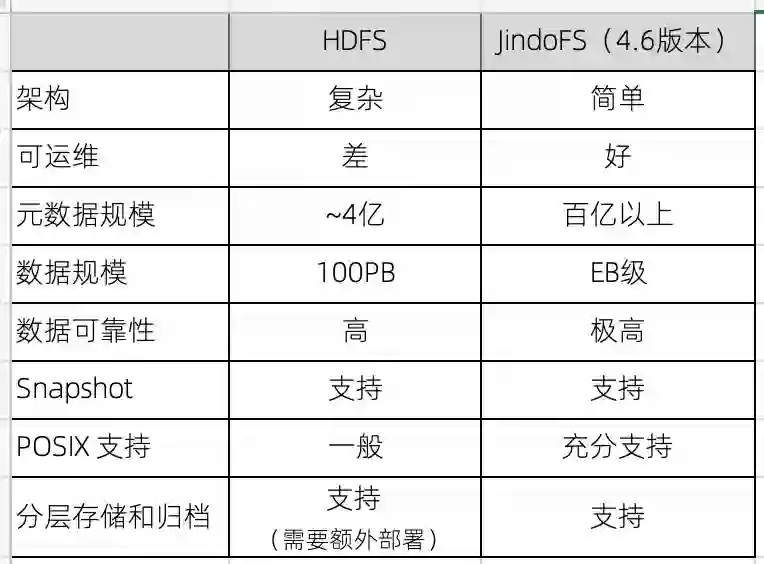
一、JindoFS 和 HDFS 系统对比分析
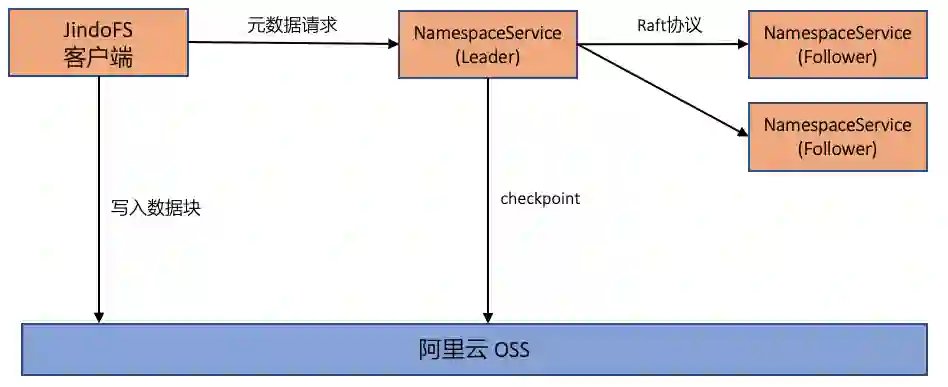
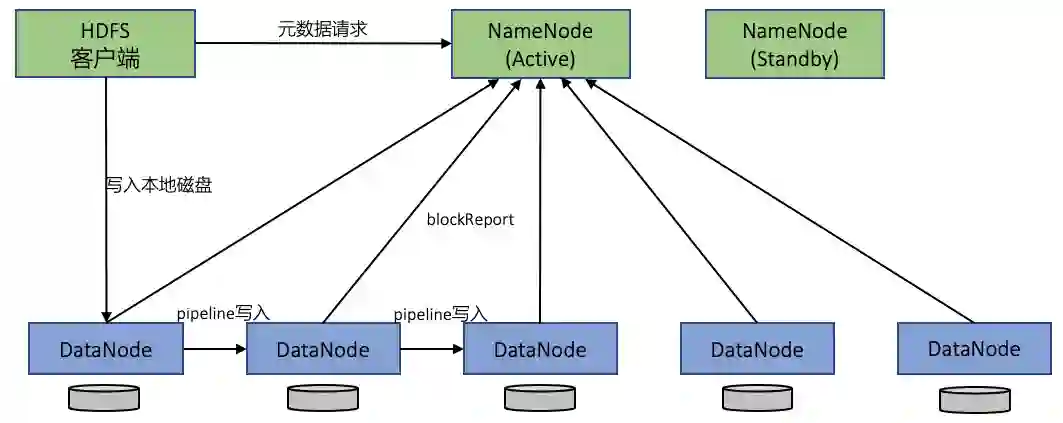
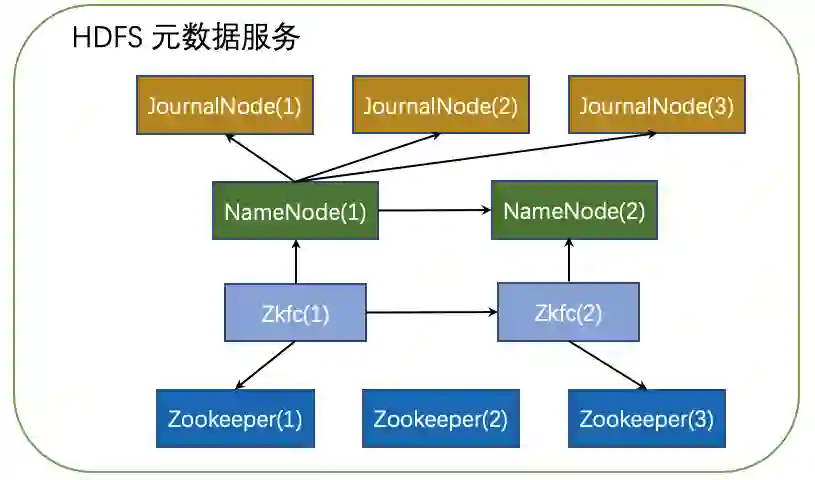
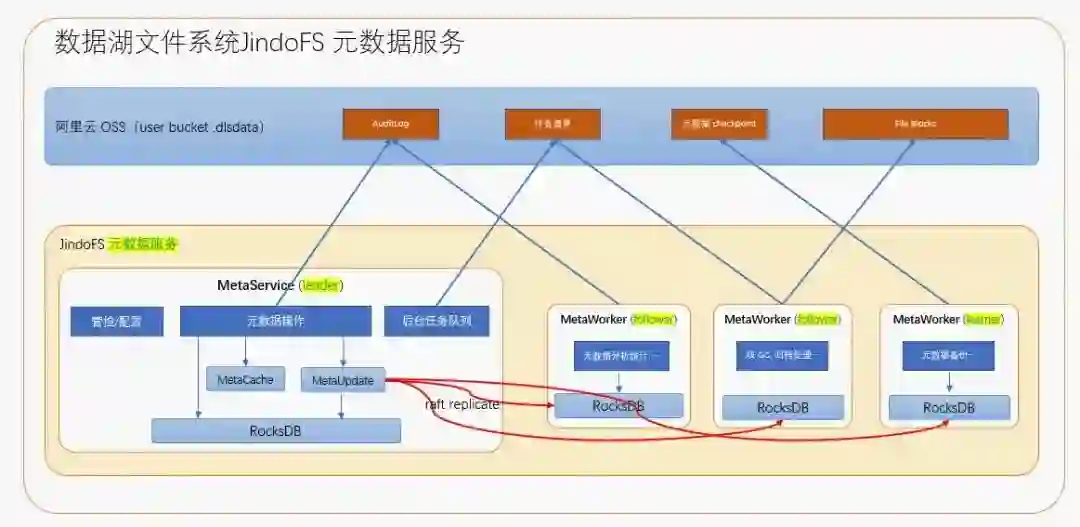
二、元数据服务
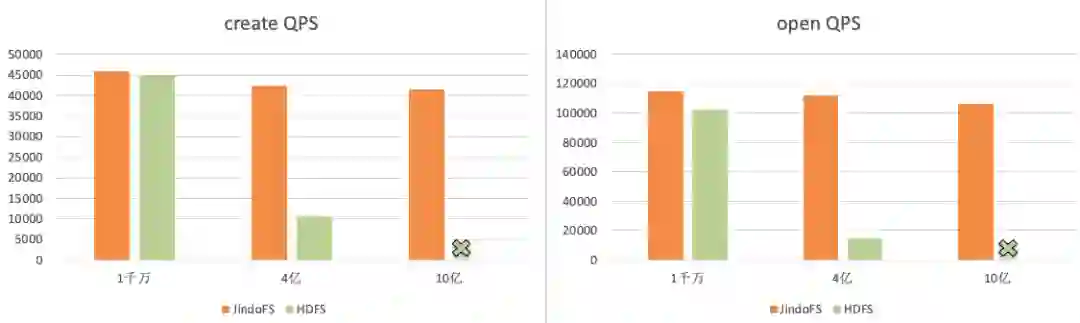
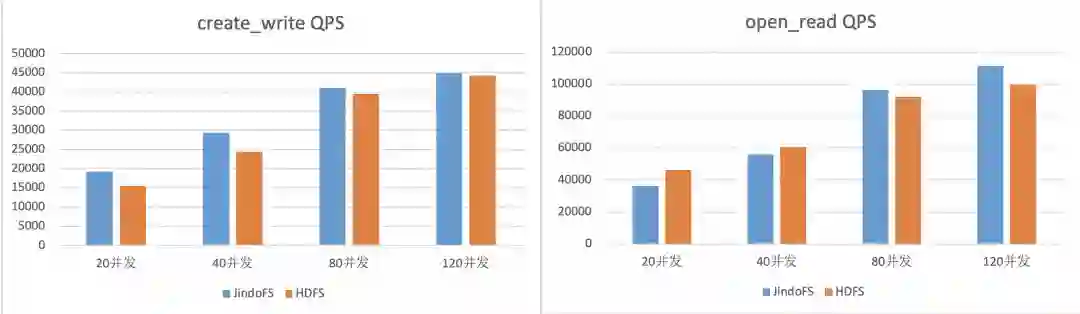
三、元数据统计分析
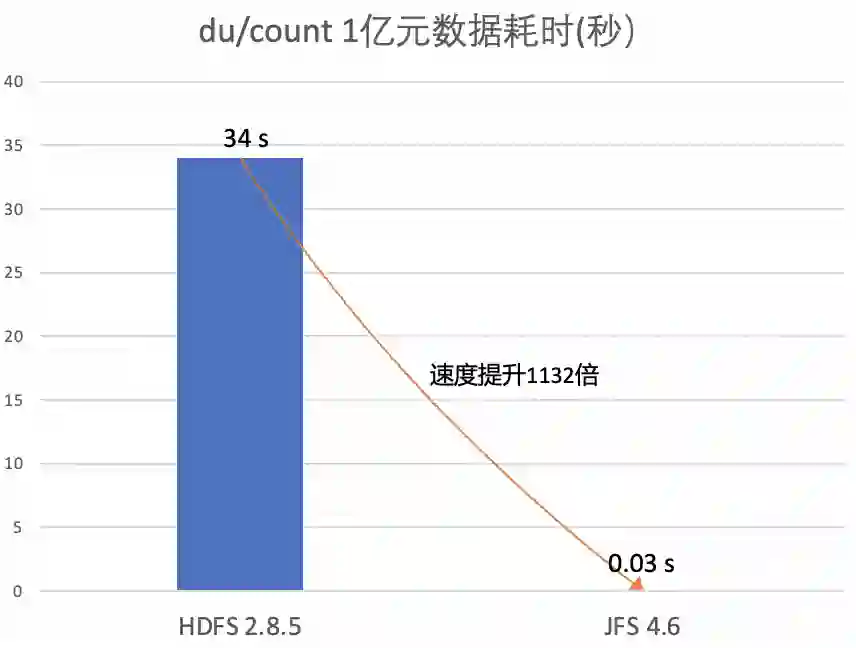
四、数据存储

五、HDFS 兼容
数据兼容
-
接口兼容
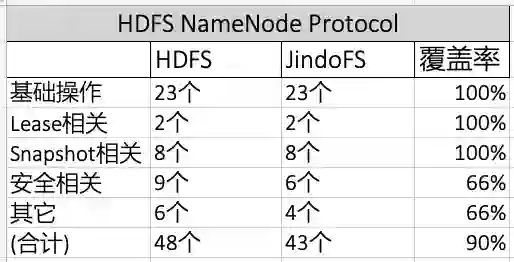
二进制协议兼容
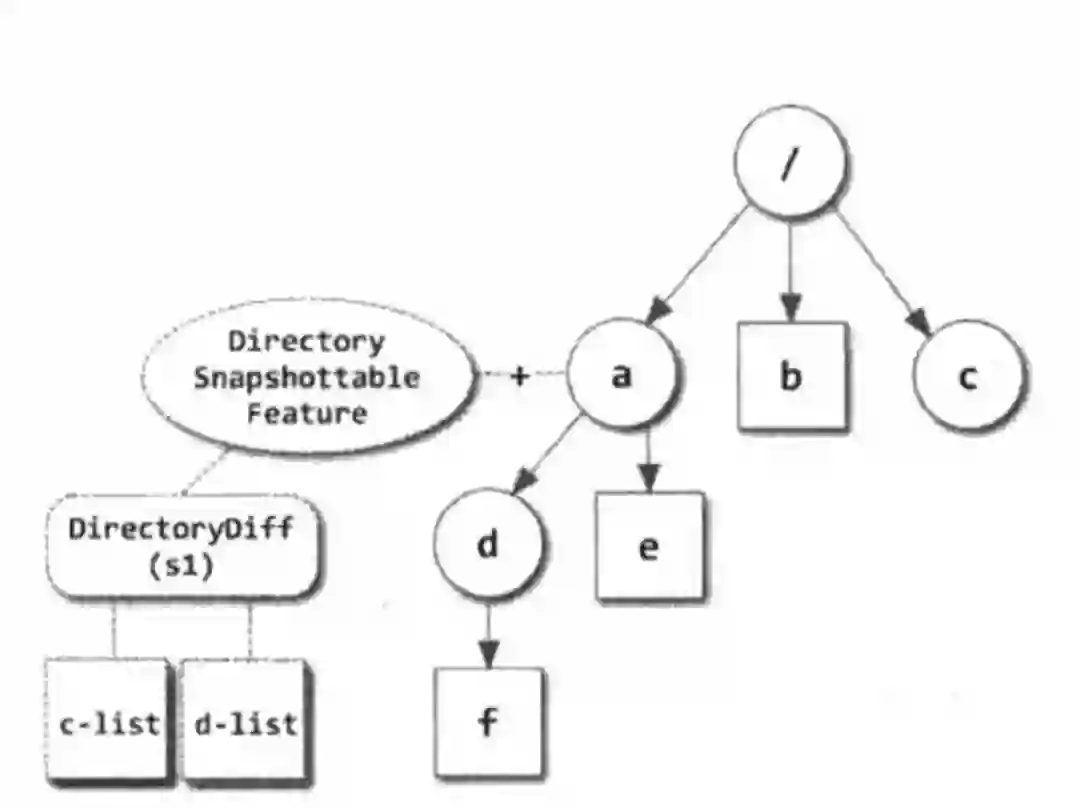
HDFS 快照
HDFS 分层存储
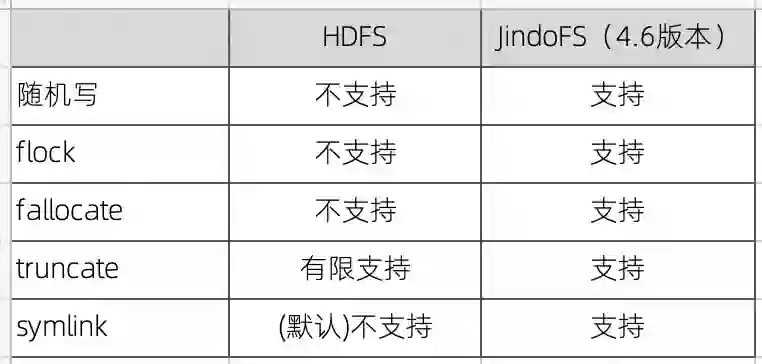
六、POSIX 支持
总结和展望:全新架构的数据湖文件系统JindoFS将成为云时代最好的HDFS
往期推荐