字节跳动开源BitSail:重构数据集成引擎,走向云原生化、实时化

自年初成立开源委员会以来,字节跳动开源动作频频。公开信息显示,字节跳动近五个月新开源了不少项目,包括 Shuffle 框架 Cloud Shuffle Service、基于 Rust 的 RPC 框架 Volo 等。
10 月 26 日,字节宣布开源自研数据集成引擎 BitSail,采用 Apache 2.0 开源许可。据悉,BitSail 支持多种异构数据源间的数据同步,并提供离线、实时、全量、增量场景下的全域数据集成解决方案,目前服务于字节内部几乎所有业务线,包括抖音、今日头条等大家耳熟能详的应用,同时也支撑了火山引擎多个客户的数据集成需求。
BitSail 开源项目 GitHub 链接:https://github.com/bytedance/bitsail
在得知 BitSail 即将开源的第一时间,InfoQ 就独家采访了字节跳动数据平台开发套件技术负责人王宇飞和数据平台数据集成方向负责人罗齐,本文将带你深入了解 BitSail 开源的背景、它在字节内部演进的历程,以及它与行业内其他数据集成项目有何不同。
BitSail 源自字节跳动数据平台团队(下文简称“团队”)自研的数据集成引擎 DTS(全称 Data Transmission Service,即数据传输服务),最初基于 Apache Flink 实现,至今已经服务于字节内部业务接近五年,是数据平台开发套件 DataLeap 的重要组件之一。
其实早在 2020 年初团队就有过将其开源的想法,但是当时内部业务发展带来的挑战和压力还比较大,同时产品本身也需要进一步打磨,团队觉得那不是一个好时机。近两年,团队积累了更多来自内外部的需求,产品也得到进一步沉淀。今年上半年,团队重新提出来讨论和思考要不要把整个产品开源出去。
既然 DTS 最初基于 Apache Flink,可能有读者会产生疑问,是不是可以把相关改进直接贡献回社区,而不是把项目单独开源出来?
针对这个问题,罗齐解释道,团队在自研过程中针对 Flink 内核做了非常多改进工作,其中大部分都已经贡献回社区了,比如针对批式 Flink 作业、解决资源无法释放问题的改进,等等。但对于集成框架本身,团队经过多次讨论觉得还是应该独立开源。
罗齐表示,Flink 作为一个通用计算框架,虽然优点很多,但在特定垂直领域还会有一些独特的问题。以数据集成领域为例,像字节这种业务线特别多、数据量极大且 SLA 要求很高的情况,仅仅依靠 Flink 框架本身并不足以把集成这件事做到极致。在开发过程中,团队也发现会有很多深度定制工作,甚至是重写。这进一步促使团队加大了 BitSail 的研发投入。
而从内部看,经过这几年字节各类业务的打磨,DTS 在稳定性、数据传输质量和运维成本三个方面都已经做得比较好,且足够成熟可靠,目前支持 20 余种数据源类型,每天有超过 20 万任务稳定运行在这套数据集成引擎之上。
除此之外,团队结合数据集成市场现状,也做了深度的考量。
据 Gartner 数据,2021 年数据集成全球市场规模达 38.5 亿美元。王宇飞认为,目前数据集成的市场需求正在快速增长,一方面是因为随着硬件成本降低,传统的 ETL 模式开始转变为 EL(T)模式,而现代数据技术栈中的数据集成产品解决的恰恰就是 EL 的问题;另一方面,由于历史原因,数据生态系统已经发展得相当复杂,存在各种不同的数据源、数据系统,如何把这么多不同来源的数据高效地收集聚合到湖或仓中,也是数据集成重点要解决的问题。因此从外部看,数据集成的市场空间和需求足够大,如果团队将自研的数据集成工具开源出去,应该能产生比较大的社会价值。
团队希望现在把它开源出来,一方面帮助外部企业客户解决数字化转型或上云第一步的问题,同时也借助社区的力量共同打造一个在全球都比较有竞争力的数据集成产品。
在决定将项目开源后,团队针对项目名称做了一次外部调研,发现 DTS 这个名字不论在产品名称层面还是商标名称层面都存在同名,经过一番讨论最终定下新名称 BitSail。据罗齐介绍,BitSail 中文直译是比特航行,希望这个项目能帮助“比特”(即数据)畅通无阻地航行到有价值的地方。
在 2017 年以前,字节内部主要使用开源的数据集成工具,比如基于 Canal 或 Spark 做一些简单的开发。自 2018 年开始,随着字节业务场景日益变得复杂,数据源越来越多、数据量越来越大,原来的简单工具已经无法支撑后续发展。字节跳动数据平台团队开始考虑自研一套新的数据集成工具。
当时团队主要有三点诉求:第一是希望这个工具能够线性、分布式地去支撑大数据场景;第二是希望用一个框架支撑流批一体的传输;第三是如果要基于一个开源框架来开发,希望这个框架能够和字节当时基于 Hadoop 的整个生态比较好地集成,并且社区要处于比较活跃的状态,这样后续整体迭代会更快一些。基于这三点诉求,当时业内比较流行的数据集成开源项目如 DataX、Sqoop 和 Flume 基本就被排除在考虑范围之外了。其中,主要用于在关系型数据库和 Hadoop 之间传输数据的 Sqoop,虽然属于 Hadoop 生态,但社区一直不太活跃,同时 Sqoop 基于 EMR 架构,本身效率要差一些,且只支持批式传输、不支持实时传输。
最终团队决定基于 Flink 自研实现流批一体的数据集成服务,终极目标是用一套统一的技术架构覆盖数据集成场景内的所有需求。
回顾这套自研的数据集成引擎在字节内部的演进历程,大致可以分为三个阶段。
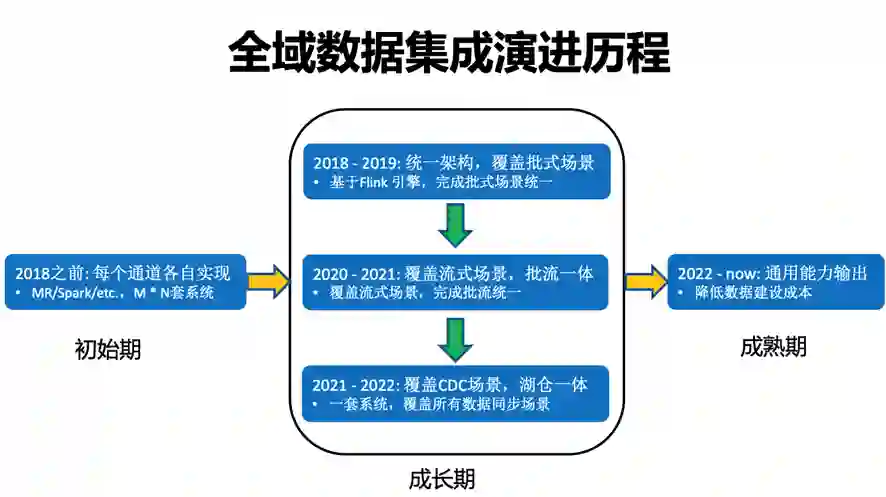
图:字节跳动数据平台全域数据集成演进历程
2018-2019 年是 V1.0 版本,团队基于 Flink Batch 构造了异构数据源之间的批式同步通道,主要用于将在线数据库导入到离线数仓,和不同数据源之间的批式传输。
V1.0 相当于起步阶段,团队主要遇到的困难在于,当时的 Flink 1.5 版本在批处理这块还不是很成熟,存在诸如批资源无法及时释放等问题。为此团队深入了解 Flink 项目源码和内核,对批处理相关的机制做了大量改进,才让批作业得以比较平稳地跑起来。
2020-2021 年数据集成引擎演进到 V2.0 版本,团队基于 Flink 构造了 MQ-Hive 的实时数据集成通道,用于将消息队列中的数据实时写入到 Hive 和 HDFS,在计算引擎上做到了流批统一。
在这个阶段,团队遇到的一个比较关键的挑战是,大数据量下 Flink Checkpoint 可靠性表现不符合预期。当时抖音的数据流量已经非常大,单任务 Flink 并发超过 5000,这在业内都是比较少见的数据量。面对如此大的数据量,基于 HDFS 的 checkpoint 成功率会明显下降,导致数据产出延迟。针对这一问题,团队联合 Flink 社区引入了 Flink Regional Checkpoint 机制,使整个 checkpoint 的成功率大幅提升:在大并发任务下,极端情况成功率从 60% 提升到了 90%。
现在字节跳动数据集成引擎已经演进到 V3.0 版本,增加了流式 CDC 和实时数据湖集成,完成了湖仓一体的数据集成引擎的构建。与此同时,在架构层面也开启了面向云原生和开源的演进,针对 K8s 云原生调度做了比较多的定制优化。
在数据湖选型上,团队基于对 Flink 和 Hudi 的技术积累和风险预判,最终选择了用 Flink+Hudi 的流式集成方案。但在做技术选型的 2021 年这个时间节点,这套方案尚不成熟,所以过去一年团队联合 Flink 和 Hudi 社区,以及公司其他团队做了很多自研改进,如今这套实时数据湖集成方案已经开始在字节内部落地应用并得到了一定收益。
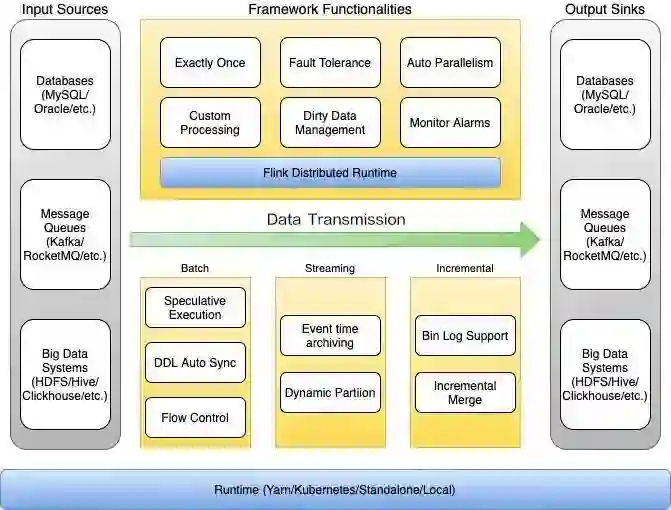
图:字节跳动数据集成引擎技术架构图
目前字节跳动数据集成引擎支持了几十条不同的数据传输管道,涵盖线上数据库,例如 MySQL、Oracle 和 MongoDB 等;消息队列,例如 Kafka、RocketMQ 等;以及大数据生态系统的各种组件,例如 HDFS、Hive 和 ClickHouse 等。
整个引擎支持三类同步模式——批式集成、流式集成和增量集成,能够覆盖离线、实时、全量、增量全场景的数据集成需求。
批式集成模式基于 Flink Batch 模式打造,将数据以批的形式在不同系统中传输,目前支持了 20 多种不同数据源类型;
流式集成模式主要是从 MQ 将数据导入到 Hive 和 HDFS,任务的稳定性和实时性都受到了用户广泛的认可;
增量模式即 CDC 模式,用于支持通过数据库变更日志 Binlog,将数据变更同步到外部组件的数据库。这种模式目前支持 5 种数据源,虽然数据源不多,但是任务数量非常庞大,其中包含了很多核心链路,例如各个业务线的计费、结算等,对数据准确性要求非常高。
这套数据集成引擎如今在字节内部服务于众多产品线,每天的任务量超过 20 万,传输的数据行数超过百万亿行。其中单批任务达到千亿行、单流任务达到千万 QPS;支持 10 分钟级延迟 SLA。
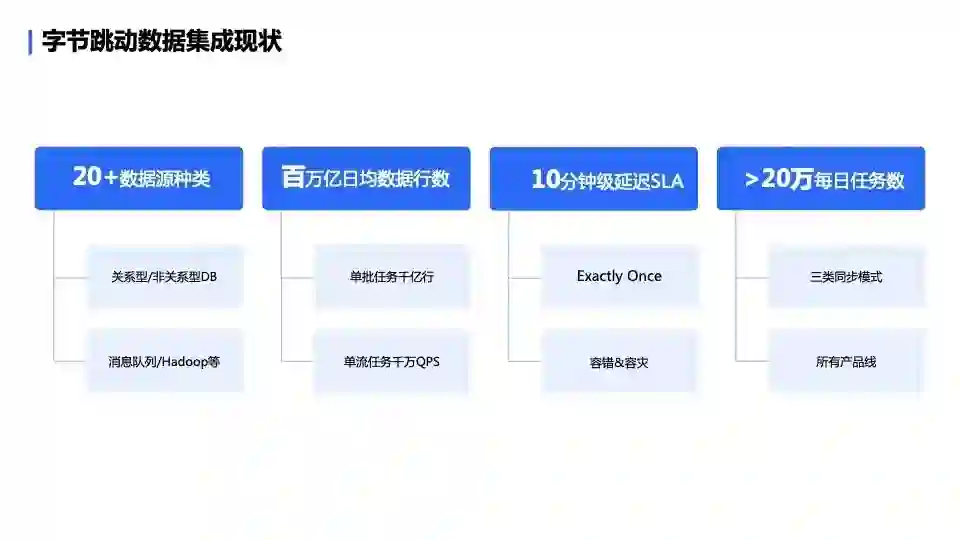
图:字节跳动数据集成现状
数据集成并非新词。早在 2005 年,Gartner 就在其 ETL 魔力象限报告中提出:ETL 工具市场正在向更广泛的数据集成平台市场过渡。
前文提及的数据集成老牌开源项目 Apache Sqoop 最初开源于 2009 年,已经在 2021 年 6 月被移至 Apache Attic 目录(等同于退役)。对照来看,BitSail 现在才开源会不会有点晚?
对此罗齐表示,一个开源项目的退役并不意味着行业发展停滞,反而可能意味着这个行业已经具备一定的成熟度,已经能跨越一个项目周期了。从行业发展来看,这两年数据集成领域涌现了很多新的开源玩家,比如国外的 Airbyte(开源数据集成平台独角兽)、国内的 Apache SeaTunnel 和 Apache InLong。罗齐认为,这些项目其实都是伴随着 ELT 模式的流行以及云原生趋势涌现出来的,这也是数据集成领域新生命力的一个表现。因此 BitSail 开源并不算晚,而是顺应领域技术发展趋势的结果——数据集成逐步走向实时化和云原生化。
那么与目前新兴的数据集成项目(如 Apache SeaTunnel 和 Apache InLong)相比,BitSail 有何差异?
对于这个问题,罗齐做了比较详细的解答。首先,Apache InLong 在消息存储上的积累更深一些,目前开源的架构中包含比较多如 SDK 采集、消息队列缓存等能力。这与典型的基于 ELT 模式的数据集成框架(如 Airbyte、DataX 或 Sqoop)存在一些区别,因此定位也有所不同。而 Apache SeaTunnel 是一个相对还在快速变化的项目,它的架构基于 Spark 和 Flink 之上,也提供一些基于引擎的 ETL transform 能力。这与 BitSail 抽象底层、不绑定计算引擎、专注于 ELT 模式不太一样。如何基于两个计算引擎提供稳定一致的能力可能会是 SeaTunnel 一个待解决的问题。
罗齐认为,不同的开源项目都有自己的特点,大家是在解决数据集成领域下面的不同子问题。综合来说,BitSail 可能给大家带来相对更多收益的点在于:
首先 BitSail 在字节内部经历了百亿级别的大流量考验,并且在火山引擎的云原生环境和客户专有云环境等各种场景都锤炼过,因此在功能细节、稳定性和性能上积累了大量优化,在成熟度上可能相对更有保障;
其次在技术层面,BitSail 支持分布式水平扩展和流批一体架构,在各种数据量和各种场景下,都能够用一个框架解决数据集成需求;
再次,BitSail 采用的是插件式架构,支持运行时解耦,其中各个数据源 connector 之间是解耦的、connector 与底层的运行引擎也是解耦的,这就提供了极大的灵活性,用户能够很低成本地接入新 connector,并且无须担心被 connector 耦合;目前 BitSail 的底层 Runtime 依赖于 Flink,但团队正在计划自研一个消耗更少资源、更灵活的本地 runtime,未来 Flink 可能仅仅作为 BitSail 的运行时之一;
最后但也非常关键的一点是,BitSail 具备字节自身在数据集成领域积累的大量基础能力,比如内置 20+ 种数据源、支持各种复合类型的自动转换、脏数据处理、流控,还有支持流式的归档、数据湖集成、自动并发度推断等等。这些功能已经支撑起字节复杂的业务场景,因此在外部用户使用的时候,也能覆盖他们绝大部分使用场景,不需要额外花时间做自研和开发工作。
作为领域内新的开源力量,字节数据平台团队希望在 BitSail 正式对外开放源代码前,能够在更多外部业务场景得到应用验证,打造一些真正有行业价值的标杆案例,因此在接受 InfoQ 采访到最终项目正式开源这段时间,团队重点围绕种子用户获取和培养做了不少工作。
技术层面,BitSail 短期内会持续夯实基础能力,包括引擎开箱即用、支持的 Connector 数量、接入成本和运维可观测性等方面都会持续提升;中长期,团队则会结合字节内部的业务情况,在比如流式数据湖、多运行时支持、弹性伸缩等创新特性上做更多研发和输出,未来也期待能够收获更多讨论和建议。

每一位开源参与者、每一个开源项目都可以成为舞台上的主角。
新的一波开源浪潮正在席卷中国,【开源聚光灯】是 InfoQ 重点打造的开源主题栏目,旨在通过新闻、系列访谈、用户调查、迷你书、视频等形式深入观察开源运动,围绕开源的价值和开源开发模式,与投身开源的每一个个体共同探讨开源发展现状,照亮每一个开源舞台上的参与者。
如果你有开源故事或对开源的深刻观点想要分享、或开源项目想要寻求报道,欢迎联系微信 caifangfang_wechat(请注明姓名和来由)。
又一巨头从Java迁移到Kotlin:关键应用全部开始切换、安卓代码库超过千万行Kotlin代码
中国开发者整体规模 2016.37万,企业服务成为热门“移民”行业| InfoQ《开发者画像洞察研究报告 2022》发布
60 岁周星驰招聘 Web3.0 人才,要求“宅心仁厚”;马斯克计划裁掉推特 75% 的员工;Linus 致开发者:不要再熬夜了 | Q 资讯
海量数据的产生带来了各种异构数据源、数据系统,如何实现高效数据集成?字节跳动数据集成引擎 BitSail 开源啦!
11 月 9 日 19:30,字节跳动数据平台举办 BitSail 首期直播活动,邀请数据集成领域专家,深入解读字节跳动数据集成技术实践与应用、开源项目规划和路径,更有工程师手把手教你如何快速上手。
👇立即扫码进群,预约直播,赢取精美礼品!




