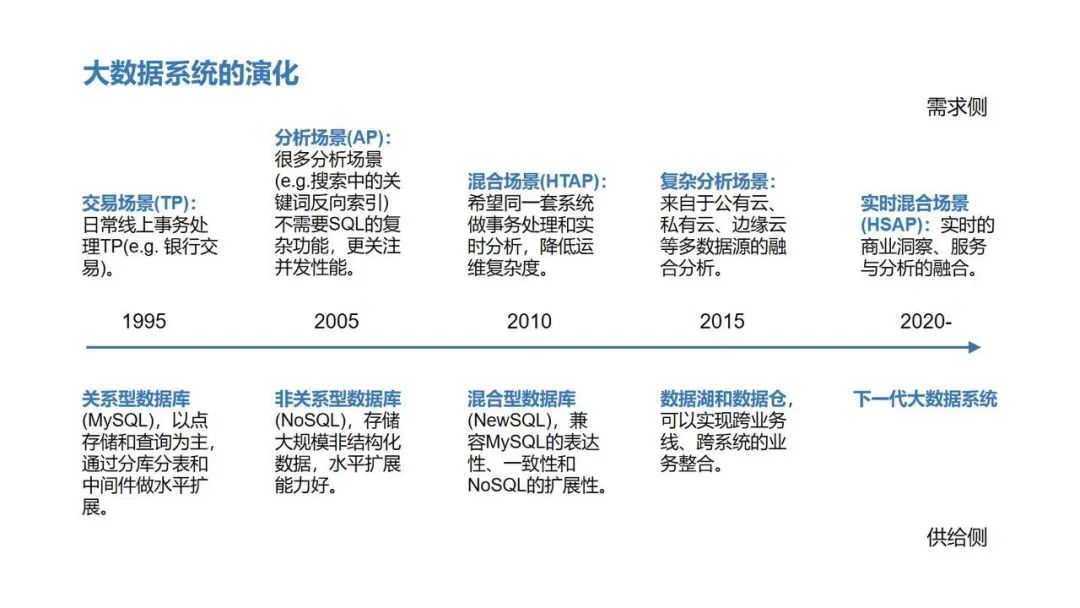
湖仓才是数据智能的未来?那你必须了解下国产唯一开源湖仓了
机器之心编辑部
国产唯一的开源数据湖存储框架 LakeSoul 近期发布了 2.0 升级版本,让数据智能触手可及。
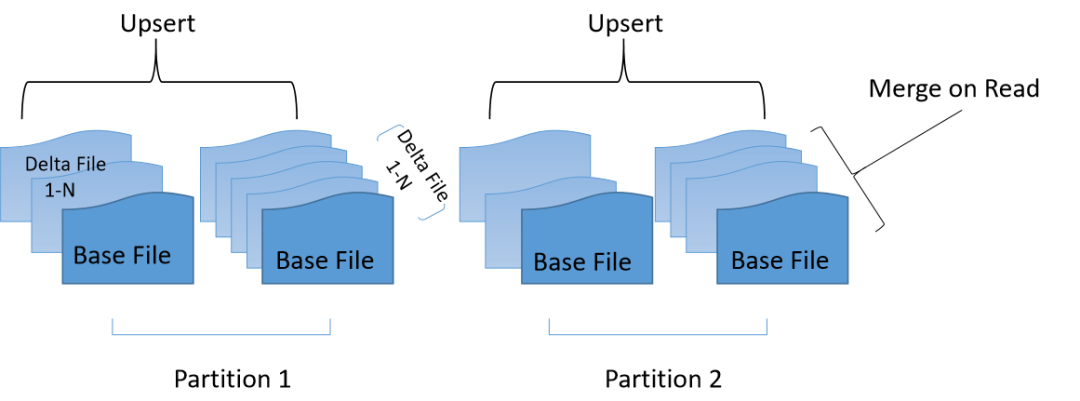
-
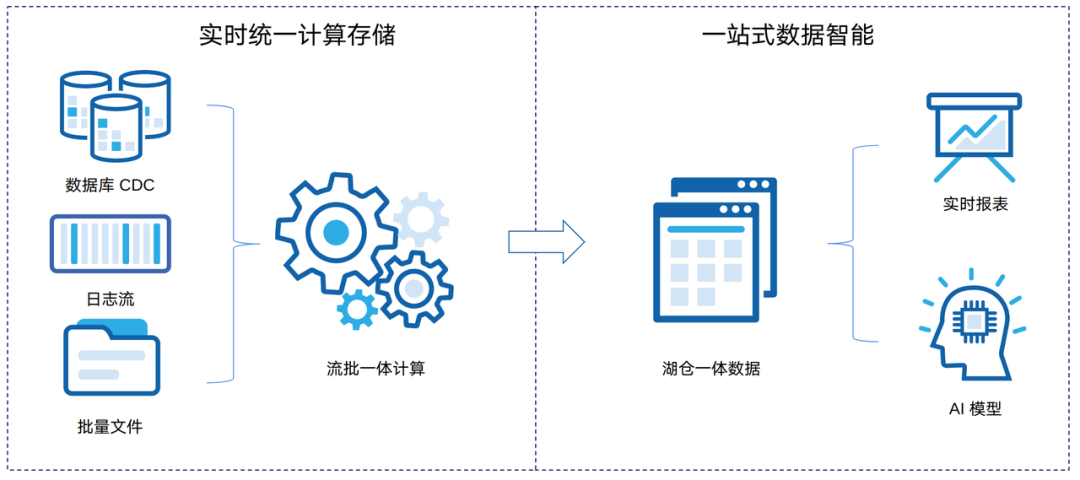
大幅简化数据智能架构,降低运维成本
-
计算成本降低,不需要多套存储 -
不依赖 Kafka 或 Flink 等有状态服务 -
避免资源潮汐效应
-
简化开发流程,降低人力成本
-
使用 SQL、Python 即可快速开发数据智能业务 -
现有数仓逻辑可以快速迁移,改造难度低
-
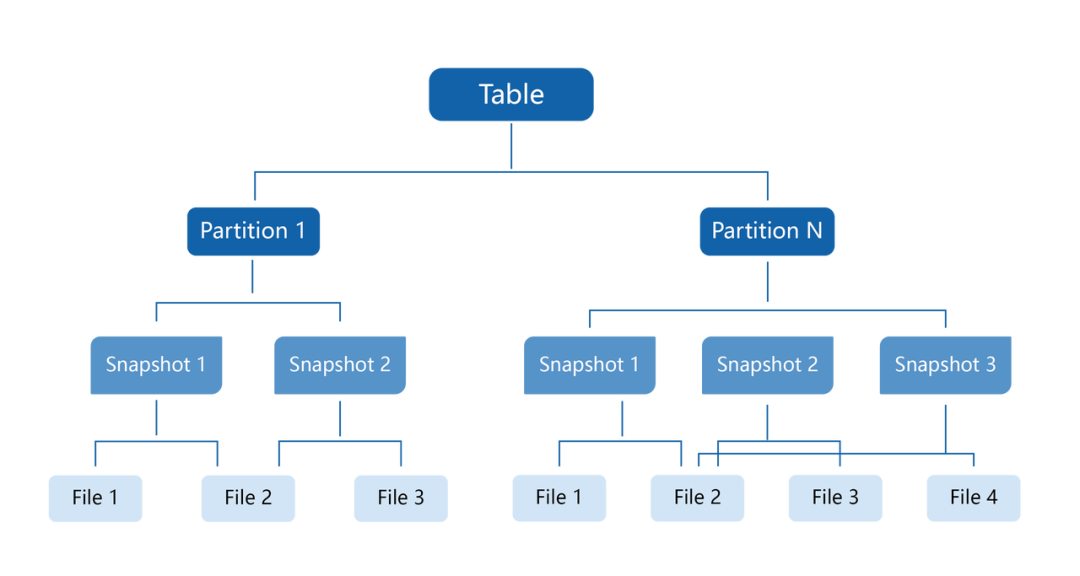
数据可靠,状态可见透明,提升数据使用效率
-
每层计算结果实时可见、可查询,数据可复用
-
上游补数、修复简单快捷,避免单点故障 -
避免数据孤岛、数据冗余、数据沼泽
-
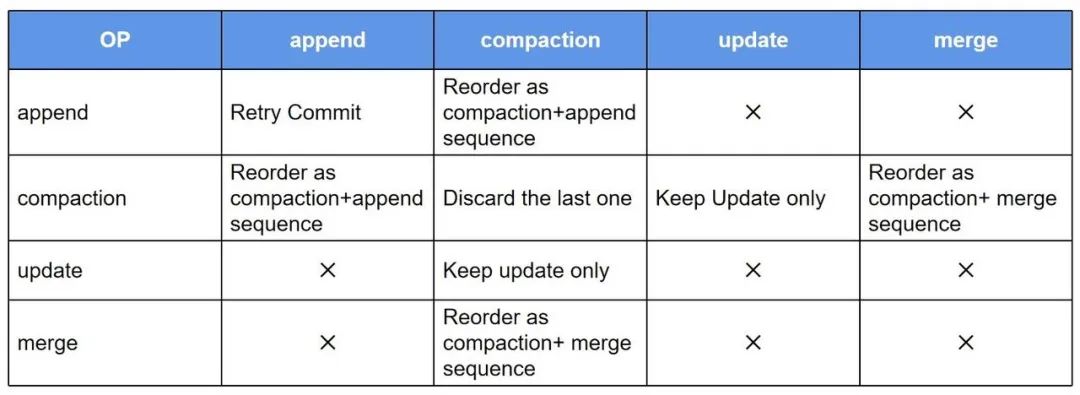
全链路 T+0 实时计算
-
计算延迟大幅降低,天级降低到分钟级 -
业务效果快速反馈
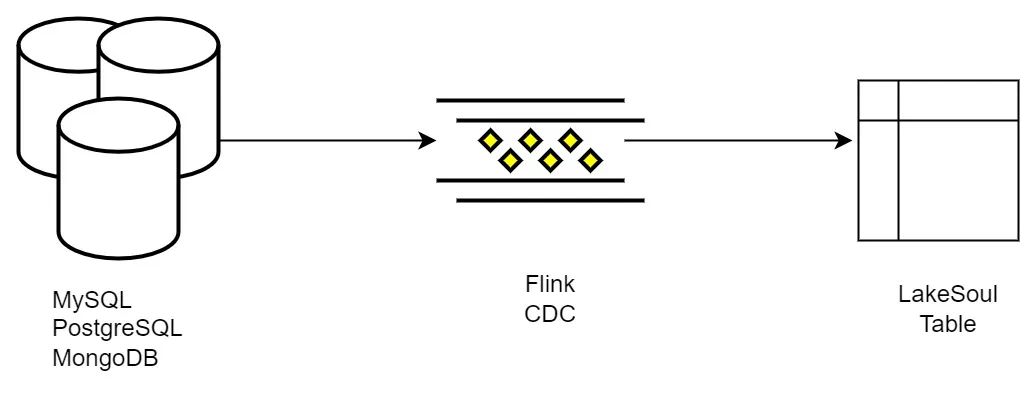
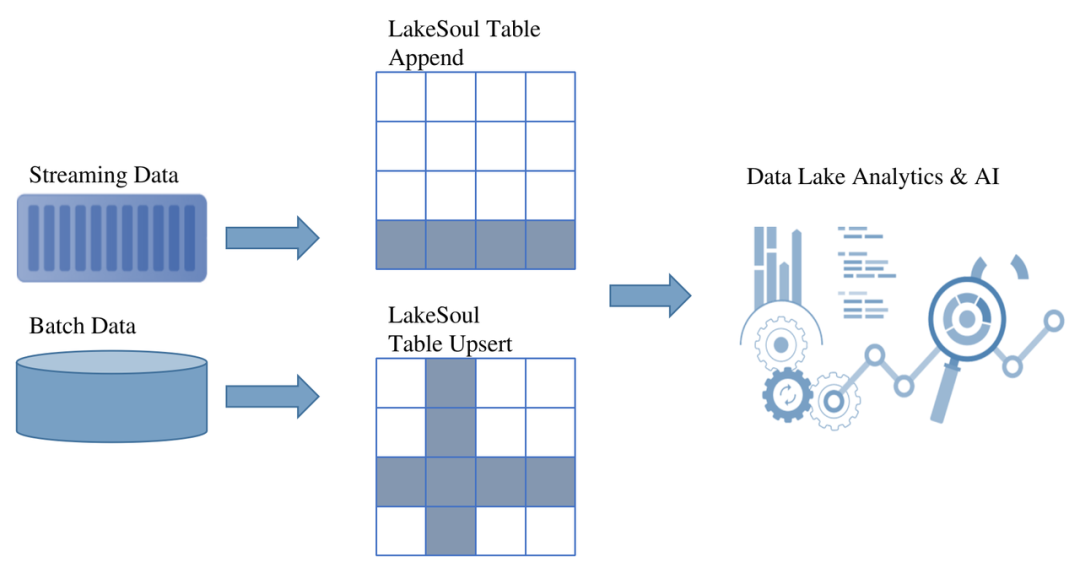
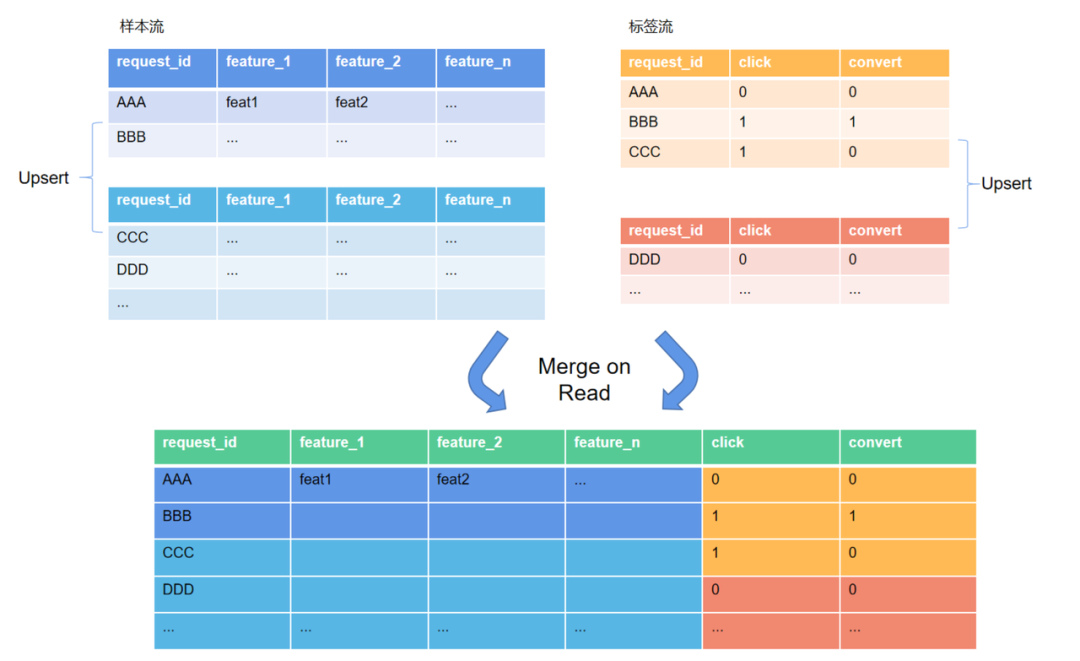
登录查看更多
相关内容
相关VIP内容
相关资讯